
技术摘要:
本发明提供了一种具有高自然度的语音拼接合成方法、系统、设备及介质,其在只有低计算资源设备的条件下,依然可以生成媲美真人发音的高自然度合成音。方法包括以下步骤:输入文本,对待合成文本进行文本处理,获取文本的发音、韵律、上下文信息;使用决策树根据文本的 全部
背景技术:
语音合成,也就是人类声音的人工产品,被广泛应用于从助手到游戏、娱乐等各种 领域。最近,配合语音识别,语音合成已经成为语音助手不可或缺的一部分。 如今,业内主要使用两种语音合成技术:单元选择和参数合成。单元选择语音合成 技术在拥有足够高质量录音时能够合成最高质量的语音,也因此成为商业产品中最常用的 语音合成技术。另外,参数合成能够提供高度可理解的、流畅的语音,但整体质量略低。因 此,在语料库较小、低占用的情况下,通常使用参数合成技术。现代的单元选择系统结合这 两种技术的优势,因此被称为混合系统。混合单元选择方法类似于传统的单元选择技术,但 其中使用了参数合成技术来预测选择的单元。 近期,深度学习对语音领域冲击巨大,极大的超越了传统的技术,例如隐马尔可夫 模型。参数合成技术也从深度学习技术中有所收益。深度学习也使得一种全新的语音合成 技术成为了可能,也就是直接音波建模技术(例如WaveNet)。该技术极有潜力,既能提供单 元选择技术的高质量,又能提供参数选择技术的灵活性。然而,这种技术计算成本极高,对 产品而言还不成熟。
技术实现要素:
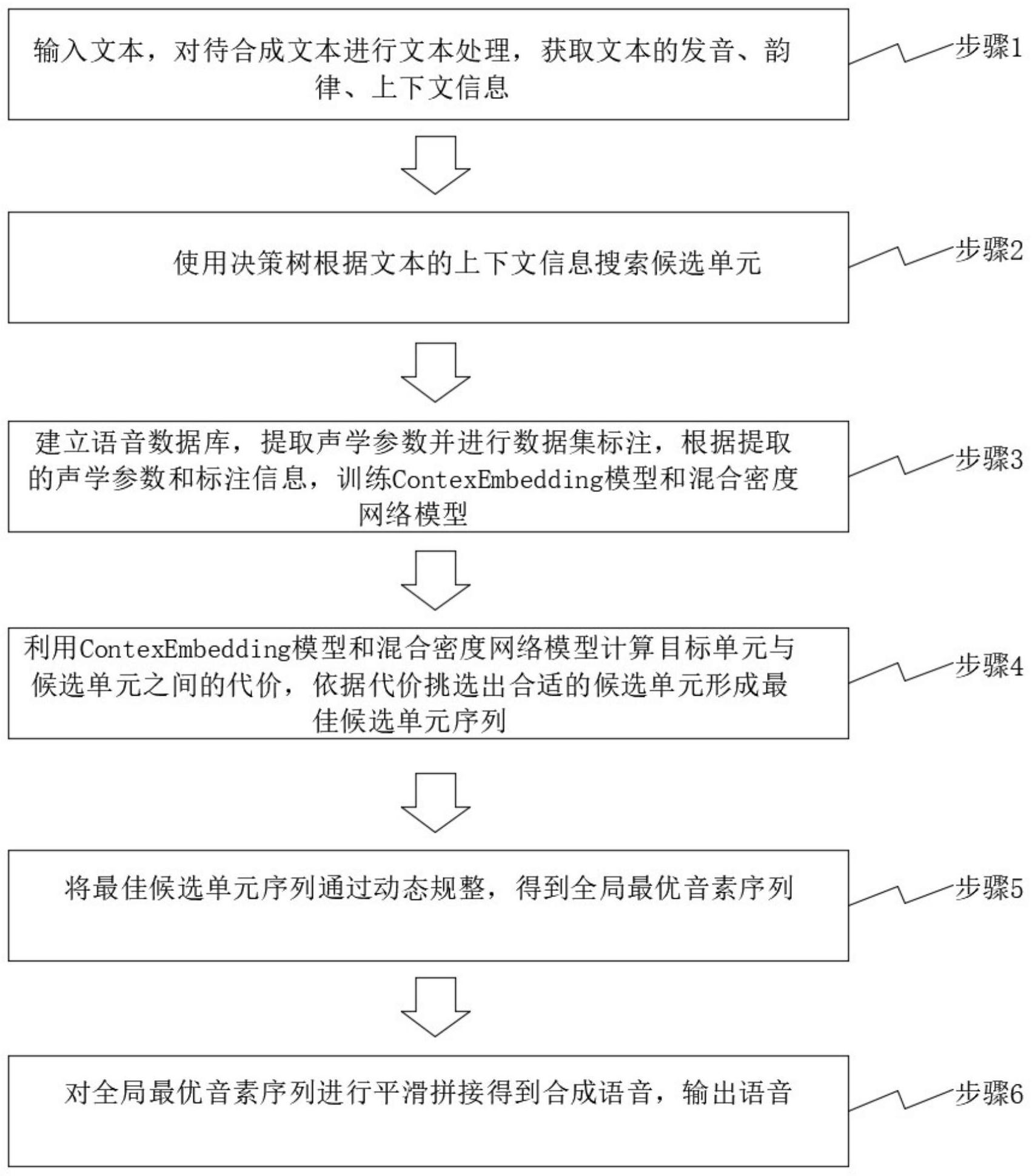
为解决参数合成音质差、深度学习计算开销大的问题,本发明提供一种具有高自 然度的语音拼接合成方法、系统、设备及介质,其在只有低计算资源设备的条件下,依然可 以做到媲美真人发音、神经网络计算开销较小。 其技术方案是这样的:一种具有高自然度的语音拼接合成方法,其特征在于,包括 以下步骤: 步骤1:文本处理:输入文本,对待合成文本进行文本处理,获取文本的发音、韵律、 上下文信息; 步骤2:候选单元预筛选:使用决策树根据文本的上下文信息搜索候选单元; 步骤3:模型训练:建立语音数据库,提取声学参数并进行数据集标注,根据提取的 声学参数和标注信息,训练ContexEmbedding模型和混合密度网络模型; 步骤4:候选单元选择:利用ContexEmbedding模型和混合密度网络模型计算目标 单元与候选单元之间的代价,依据代价挑选出合适的候选单元形成最佳候选单元序列; 步骤5:动态规整:将最佳候选单元序列通过动态规整,得到全局最优音素序列; 步骤6:波形拼接:对全局最优音素序列进行平滑拼接得到合成语音,输出语音。 具体的,步骤3具体包括以下步骤: 步骤301:根据上下文发音覆盖以及韵律边界覆盖规则设计文本语料并录制语音 5 CN 111599339 A 说 明 书 2/8 页 数据库; 步骤302:提取的声学参数,提取的声学参数包括音频的基频、倒谱系数; 步骤303:进行数据集标注,包括对音频的音素边界以及文本的韵律边界、重读进 行标注; 步骤304:通过提取的声学参数以及标注信息训练声学参数的隐马尔可夫模型; 步骤305:通过隐马尔可夫模型对音频进行解码,获取音素边界以及对应的各个状 态边界; 步骤306:通过获得的状态边界训练音素时长的隐马尔可夫模型; 步骤307:利用机器学习方法,将步骤305获得的状态边界作为每一帧的位置信息, 并结合决策树状态绑定问题集作为输入,将声学参数作为输出,训练得到ContexEmbedding 模型; 步骤308:利用机器学习方法,将步骤305获得的状态边界作为每一帧的位置信息, 并结合决策树状态绑定问题集作为输入,将声学特征的高斯分布作为输出,训练得到混合 密度网络模型。 具体的,在步骤1中,对待合成文本进行文本处理时,基于Multitask的Bilstm-CRF 的韵律预测工具获取韵律边界,通过Bilstm的多音字消歧工具获得准确的待合成文本的发 音;通过文本规则处理日期时间、特殊字符。 具体的,在步骤2中,在决策树的训练过程中,采用共状态聚类的方案计算包含多 状态音素的似然度、以最小描述长度准则对决策树各节点进行分裂。 具体的,在步骤3中,在训练ContexEmbedding模型时,以最小均方误差准则作为训 练准则;在训练混合密度网络模型时,以声学参数在高斯分布上的最小似然度作为训练准 则。 具体的,混合密度网络模型具体包括以下步骤: 步骤S21:使用音素时长的隐马尔可夫模型生成目标单元各个状态的时长,从而获 得目标单元各个状态的位置信息; 步骤S22:利用决策树绑定问题集生成目标单元的上下文; 步骤S23:将步骤S21得到的位置信息和步骤S22得到的上下文作为混合密度网络 模型的输入,生成各个状态的声学参数的分布。 具体的,其特征在于,ContexEmbedding模型采用三层单向LSTM模型,包括以下步 骤: 步骤S31:使用音素时长的隐马尔可夫模型生成目标单元各个状态的时长,从而获 得目标单元各个状态的位置信息; 步骤S32:利用决策树绑定问题集生成目标单元的上下文; 步骤S33:将步骤S31得到的状态位置信息和步骤S32得到的上下文作为 ContexEmbedding模型的输入,模型的输出为目标单元的声学参数,采用LSTM模型的第二层 的输出作为Embedding特征; 步骤S34:计算Embdedding特征之间的欧式距离度量候选单元与目标单元声学距 离。 具体的,在步骤4中,候选单元的代价计算包括目标代价和连接代价的计算, 6 CN 111599339 A 说 明 书 3/8 页 其中,目标代价为候选单元的声学参数分别在contexEmbedding模型以及混合密 度网络上的计算代价,其中候选单元在混合密度网络上的代价为: 其中,S为候选单元的声学参数,u、Σ分别为混合密度网声学特征的均值与方差,n 表示候选单元的第n帧,k表示候选单元的第k个状态,f为第f类声学参数, 候选单元在ContexEmdedding模型上的代价为: CEMBn=||UE_tarn-UE_candin||2 其中,UE_tar、UE_candi分别为目标单元以及候选单元的ContexEmbdeeing特征; 连接代价为:前后候选单元的最后一帧以及第一帧的声学参数,分别以在后、在前 候选单元对应的混合密度网络的第一状态以及最后一状态上的似然度,作为连接代价,用 于衡量前后两个候选单元在拼接上的听觉一致性,连接代价的计算为: 其中,SF为候选单元第一帧的声学参数,SL为最后一帧的声学参数, 候选单元的代价计算为: 其中,U为最佳候选单元序列,N为待合成音素序列测长度,K为各个音素对应混合 密度网络的状态数量,F为声学特征的种类,W、WC分别目标代价以及连接代价中声学特征的 权重。 具体的,在步骤5中,对于最佳候选单元序列的动态规整具体包括以下步骤: 利用混合密度网络获取候选单元各个状态的基频的分布, 获取存在基频的状态数,判断是否为浊音,是则对应生成连续浊音子序列, 获取候选单元序列中的连续浊音子序列并分别对其进行第一次动态规整解码,获 取子路径; 将原解码网络中连续浊音段的路径替换为子路径; 对替换后的解码网络进行第二次动态规整解码,得到全局最优音素序列。 具体的,在步骤6中,对于全局最优音素序列进行平滑拼接具体如下: 对全局最优音素序列中的音素片段的首尾N毫秒进行自相关计算,取自相关值最 大的位置作为最佳的拼接点,其中,N大于最小基频的倒数。 一种具有高自然度的语音拼接合成系统,其特征在于,包括: 训练模块,用于建立语音数据库,提取声学参数并进行数据集标注,根据提取的声 学参数和标注信息,训练ContexEmbedding模型和混合密度网络模型; 合成模块,用于输入文本,对待合成文本进行文本处理,获取文本的发音、韵律、上 下文信息;使用决策树根据文本的上下文信息搜索候选单元;利用训练模块训练得到的 ContexEmbedding模型和混合密度网络模型计算目标单元与候选单元之间的代价,依据代 7 CN 111599339 A 说 明 书 4/8 页 价挑选出合适的候选单元形成最佳候选单元序列;将最佳候选单元序列通过动态规整,得 到全局最优音素序列;对全局最优音素序列进行平滑拼接得到合成语音,输出语音。 具体的,所述训练模块具体用于: 根据上下文发音覆盖以及韵律边界覆盖规则设计文本语料并录制语音数据库;提 取的声学参数,提取的声学参数包括音频的基频、倒谱系数;进行数据集标注,包括对音频 的音素边界以及文本的韵律边界、重读进行标注;通过提取的声学参数以及标注信息训练 隐马尔可夫模型;通过隐马尔可夫模型对音频进行解码,获取音素边界以及对应的各个状 态边界;通过获得的状态边界训练音素时长的隐马尔可夫模型;利用机器学习方法,将获得 的状态边界作为每一帧的位置信息,并结合决策树状态绑定问题集作为输入,将声学参数 作为输出,训练得到ContexEmbedding模型;利用机器学习方法,将获得的状态边界作为每 一帧的位置信息,并结合决策树状态绑定问题集作为输入,将声学特征的高斯分布作为输 出,训练得到混合密度网络模型。 一种电子设备,其特征在于,包括存储器、处理器以及存储在存储器上并可在处理 器上运行的程序,所述处理器执行所述程序时实现如上述的具有高自然度的语音拼接合成 方法。 一种计算机可读存储介质,其上存储有程序,其特征在于:所述程序被处理器执行 时实现如上述的具有高自然度的语音拼接合成方法。 与现有技术相比本发明具有以下有益效果: 相较于现有的语音拼接合成前端,本发明高精确度的前端建模能够获得待合成文 本的高自然度的韵律以及准确的读音,前端主要功能是通过相对应的文本处理,将待合成 文本解释成与声学参数相关的韵律边界等级、分词词性、重读、拼音等信息; 传统的语音拼接合成使用隐马尔可夫模型进行声学建模,其可靠性绝大程度上依 赖于决策树问题集的设计且不能描述帧级别的声学特性,本发明采用混合密度网络描述目 标单元声学参数的高斯分布,辅以ContexEmbedding模型约束候选单元短时特性,通过上述 方式,可以在计算资源有限的前提下获得高自然度、媲美真人发音的合成音; 此外,本发明使用两级动态规整的方案,增强动态规整的局部解码效果,基于连续 浊音匹配的二级动态规整搜索,第一级搜索保证单元序列的局部最优,第二级搜索保证候 选单元序列的全局最优,最终获得高自然度的拼接合成音; 本发明的具有高自然度的语音拼接合成方法、系统、设备及介质可被广泛应用于 手机助手、智能音箱、AI教育等领域。 附图说明 图1为本发明的一种具有高自然度的语音拼接合成方法的流程示意图; 图2为本发明的一种具有高自然度的语音拼接合成方法的流程框图; 图3为本发明的一种具有高自然度的语音拼接合成系统的框图。











