
技术摘要:
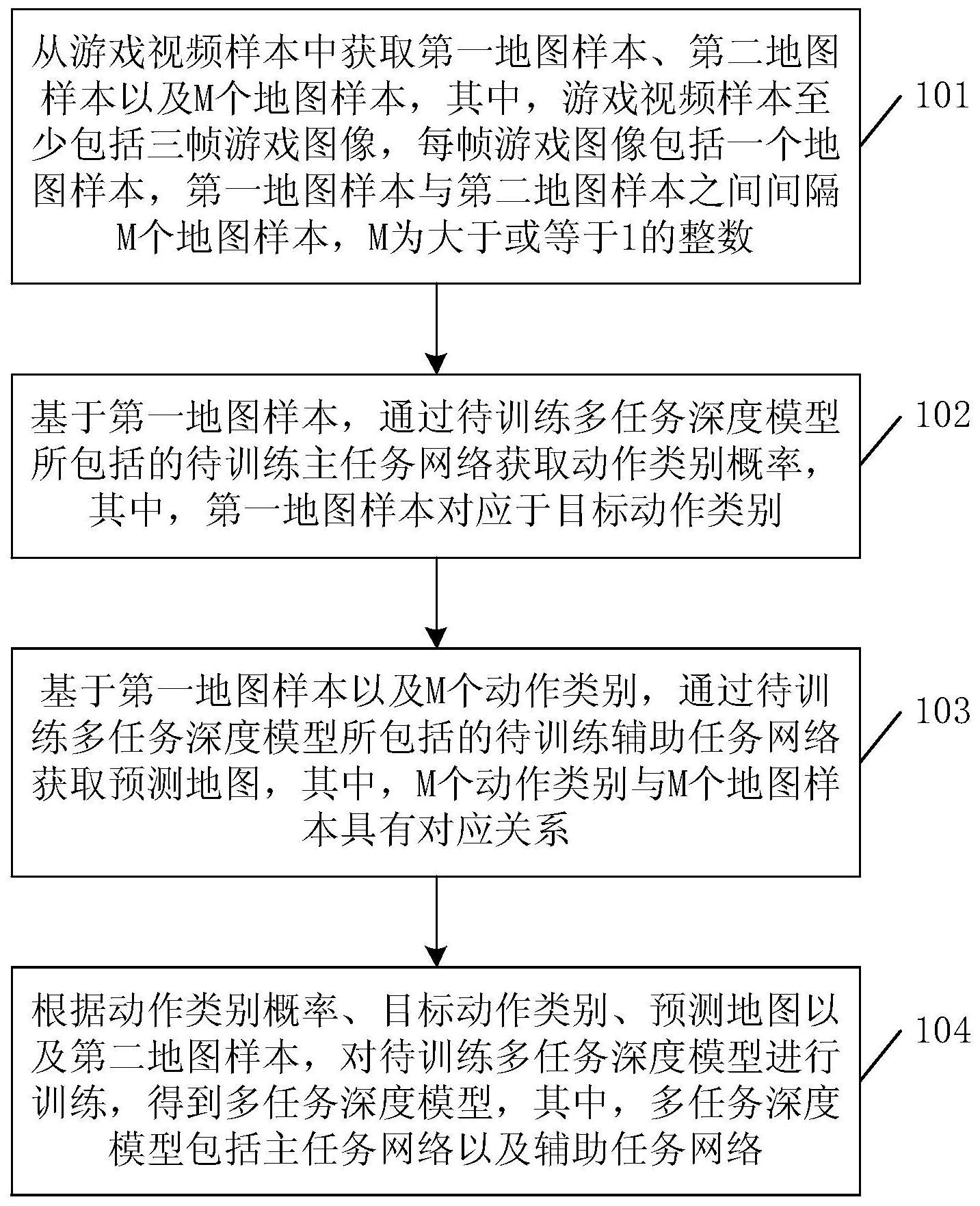
本申请公开了一种应用于人工智能领域的模型训练方法,包括:从游戏视频样本中获取第一地图样本、第二地图样本以及M个地图样本;基于第一地图样本,通过待训练多任务深度模型所包括的待训练主任务网络获取动作类别概率;基于第一地图样本以及M个动作类别,通过待训练多 全部
背景技术:
近年来,人工智能(Artificial Intelligence,AI)技术掀起了以深度学习为核心 的变革,如今,AI技术开始向各个垂直领域扩展,例如金融、医疗以及游戏行业等。对于游戏 行业而言,基于AI技术可以实现游戏测试、人机对战以及队友辅助等功能。 目前,可针对游戏设计一个用于模拟真实玩家的AI模型,通常采用强化学习的方 法训练该AI模型。具体为,先与环境进行交互,再根据游戏角色的动作反馈计算动作的奖 励,通过将奖励最大化的方式来优化AI模型的模型参数。 然而,基于强化学习的方法训练AI模型,虽然能够取得较好的模拟效果,但是这种 方式需要长时间的与环境进行交互,导致训练的时间较长。
技术实现要素:
本申请实施例提供了一种模型训练方法、游戏测试方法、模拟操作方法及装置,整 个训练过程无需耗费大量时间与环境进行交互,从而减少了训练时间,提升了模型训练的 效率。与此同时,还可降低过拟合的风险,从而提升模型效果。 有鉴于此,本申请一方面提供一种模型训练的方法,包括: 从游戏视频样本中获取第一地图样本、第二地图样本以及M个地图样本,其中,游 戏视频样本至少包括三帧游戏图像,每帧游戏图像包括一个地图样本,第一地图样本与第 二地图样本之间间隔M个地图样本,M为大于或等于1的整数; 基于第一地图样本,通过待训练多任务深度模型所包括的待训练主任务网络获取 动作类别概率,其中,第一地图样本对应于目标动作类别; 基于第一地图样本以及M个动作类别,通过待训练多任务深度模型所包括的待训 练辅助任务网络获取预测地图,其中,M个动作类别与M个地图样本具有对应关系; 根据动作类别概率、目标动作类别、预测地图以及第二地图样本,对待训练多任务 深度模型进行训练,得到多任务深度模型,其中,多任务深度模型包括主任务网络以及辅助 任务网络。 本申请另一方面提供一种游戏测试的方法,包括: 针对于待测试游戏,获取待测试游戏图像所对应的地图; 基于待测试游戏图像所对应的地图,通过多任务深度模型中的主任务网络获取动 作类别概率,其中,多任务深度模型为采用上述方法训练得到的; 根据动作类别概率确定目标动作类别; 根据目标动作类别,控制终端设备执行相应的模拟操作,以得到操作反馈结果; 根据操作反馈结果生成游戏测试结果。 6 CN 111598169 A 说 明 书 2/27 页 本申请另一方面提供一种模拟操作的方法,包括: 获取游戏图像中的目标地图; 基于目标地图,通过多任务深度模型中的主任务网络获取动作类别概率,其中,多 任务深度模型为采用上述方法训练得到的; 根据动作类别概率确定目标动作类别; 根据目标动作类别,控制终端设备执行相应的模拟操作。 本申请另一方面提供一种模型训练装置,包括: 获取模块,用于从游戏视频样本中获取第一地图样本、第二地图样本以及M个地图 样本,其中,游戏视频样本至少包括三帧游戏图像,每帧游戏图像包括一个地图样本,第一 地图样本与第二地图样本之间间隔M个地图样本,M为大于或等于1的整数; 获取模块,还用于基于第一地图样本,通过待训练多任务深度模型所包括的待训 练主任务网络获取动作类别概率,其中,第一地图样本对应于目标动作类别; 获取模块,还用于基于第一地图样本以及M个动作类别,通过待训练多任务深度模 型所包括的待训练辅助任务网络获取预测地图,其中,M个动作类别与M个地图样本具有对 应关系; 训练模块,用于根据动作类别概率、目标动作类别、预测地图以及第二地图样本, 对待训练多任务深度模型进行训练,得到多任务深度模型,其中,多任务深度模型包括主任 务网络以及辅助任务网络。 在一种可能的设计中,在本申请实施例的另一方面的一种实现方式中, 获取模块,具体用于获取游戏视频样本; 从游戏视频样本中获取第一游戏图像以及第二游戏图像,其中,第一游戏图像与 第二游戏图像之间间隔M个游戏图像; 根据第一游戏图像获取第一地图样本; 根据第二游戏图像获取第二地图样本。 在一种可能的设计中,在本申请实施例的另一方面的另一种实现方式中, 获取模块,具体用于基于第一地图样本,通过待训练多任务深度模型所包括的至 少一个卷积层,获取图像卷积特征; 基于图像卷积特征,通过待训练主任务网络所包括的至少一个全连接层,获取动 作类别概率。 在一种可能的设计中,在本申请实施例的另一方面的另一种实现方式中, 获取模块,具体用于获取M个动作类别; 基于第一地图样本,通过待训练多任务深度模型所包括的至少一个卷积层,获取 图像卷积特征; 基于图像卷积特征,通过待训练辅助任务网络所包括的第一全连接层,获取第一 特征向量; 基于M个动作类别,通过待训练辅助任务网络所包括的第二全连接层,获取第二特 征向量; 基于第一特征向量以及第二特征向量,通过待训练辅助任务网络所包括的第三全 连接层获取第三特征向量; 7 CN 111598169 A 说 明 书 3/27 页 基于第三特征向量,通过待训练辅助任务网络所包括的转换层获取特征矩阵; 基于特征矩阵,通过待训练辅助任务网络所包括的至少一个上采样层,获取预测 地图。 在一种可能的设计中,在本申请实施例的另一方面的另一种实现方式中, 获取模块,具体用于基于第一地图样本,通过待训练多任务深度模型所包括的第 一卷积层,获取第一图像卷积特征; 基于第一图像卷积特征,通过待训练多任务深度模型所包括的第二卷积层,获取 第二图像卷积特征; 基于第二图像卷积特征,通过待训练多任务深度模型所包括的第三卷积层,获取 图像卷积特征; 基于特征矩阵,通过待训练辅助任务网络所包括的至少一个上采样层,获取预测 地图,包括: 基于特征矩阵,通过待训练辅助任务网络所包括的第一上采样层,获取第一图像 特征; 基于第一图像特征以及第二图像卷积特征,通过待训练辅助任务网络所包括的第 二上采样层,获取第二图像特征; 基于第二图像特征以及第一图像卷积特征,通过待训练辅助任务网络所包括的第 三上采样层,获取预测地图。 在一种可能的设计中,在本申请实施例的另一方面的另一种实现方式中, 训练模块,具体用于根据动作类别概率以及目标动作类别确定第一损失值; 根据预测地图以及第二地图样本确定第二损失值; 基于第一损失值以及第二损失值,采用目标损失函数确定目标损失值; 当满足模型训练条件时,则根据目标损失值对待训练多任务深度模型进行训练, 得到多任务深度模型。 在一种可能的设计中,在本申请实施例的另一方面的另一种实现方式中, 训练模块,具体用于基于动作类别概率以及目标动作类别,通过第一损失函数确 定第一地图样本所对应的第一子损失值,其中,第一地图样本属于N个地图样本中的一个地 图样本,N为大于或等于1的整数; 当获取到N个地图样本中每个地图样本所对应的第一子损失值时,根据N个地图样 本中每个地图样本所对应的第一子损失值,确定第一损失值。 在一种可能的设计中,在本申请实施例的另一方面的另一种实现方式中, 训练模块,具体用于基于预测地图以及第二地图样本,通过第二损失函数确定Q个 像素点中每个像素点所对应的第二子损失,其中,Q为大于或等于1的整数,第二子损失用于 表示像素点在至少一个通道上的像素值差异; 当获取到Q个第二子损失时,根据Q个第二子损失确定第二损失值。 在一种可能的设计中,在本申请实施例的另一方面的另一种实现方式中, 训练模块,具体用于当达到迭代次数阈值,或,目标损失值达到收敛时,确定满足 模型训练条件; 采用目标损失值对待训练多任务深度模型的模型参数进行更新,得到更新后的模 8 CN 111598169 A 说 明 书 4/27 页 型参数; 根据更新后的模型参数获取多任务深度模型。 本申请另一方面提供一种游戏测试装置,包括: 获取模块,用于针对于待测试游戏,获取待测试游戏图像所对应的地图; 获取模块,还用于基于待测试游戏图像所对应的地图,通过多任务深度模型中的 主任务网络获取动作类别概率,其中,多任务深度模型为采用上述方法训练得到的; 确定模块,用于根据动作类别概率确定目标动作类别; 模拟模块,用于根据目标动作类别,控制终端设备执行相应的模拟操作,以得到操 作反馈结果; 生成模块,用于根据操作反馈结果生成游戏测试结果。 本申请另一方面提供一种模拟操作装置,包括: 获取模块,用于获取游戏图像中的目标地图; 获取模块,还用于基于目标地图,通过多任务深度模型中的主任务网络获取动作 类别概率,其中,多任务深度模型为采用上述方法训练得到的; 确定模块,用于根据动作类别概率确定目标动作类别; 模拟模块,用于根据目标动作类别,控制终端设备执行相应的模拟操作。 本申请另一方面提供一种计算机设备,包括:存储器、收发器、处理器以及总线系 统; 其中,存储器用于存储程序; 处理器用于执行存储器中的程序,包括执行上述各方面所述的方法; 总线系统用于连接存储器以及处理器,以使存储器以及处理器进行通信。 本申请另一方面提供了一种计算机可读存储介质,所述计算机可读存储介质中存 储有指令,当其在计算机上运行时,使得计算机执行上述各方面所述的方法。 从以上技术方案可以看出,本申请实施例具有以下优点: 本申请实施例中,提供了一种模型训练的方法,首先从游戏视频样本中获取第一 地图样本、第二地图样本以及M个地图样本,然后基于第一地图样本,通过待训练多任务深 度模型所包括的待训练主任务网络获取动作类别概率,并基于第一地图样本以及M个动作 类别,通过待训练多任务深度模型所包括的待训练辅助任务网络获取预测地图,最后根据 动作类别概率、目标动作类别、预测地图以及第二地图样本,对待训练多任务深度模型进行 训练,得到多任务深度模型。通过上述方式,基于多任务深度模型可采用少量样本训练得到 主任务网络,整个过程无需耗费大量时间与环境进行交互,从而减少了训练时间,提升了模 型训练的效率。与此同时,多任务深度模型还融合了两个相关的任务网络来提升模型学习 能力,可降低过拟合的风险,从而提升模型效果。 附图说明 图1为本申请实施例中模拟操作系统的一个环境示意图; 图2为本申请实施例中实现游戏模拟操作的一个流程示意图; 图3为本申请实施例中模型训练方法的一个实施例示意图; 图4为本申请实施例中基于竞速类游戏的一个游戏图像示意图; 9 CN 111598169 A 说 明 书 5/27 页 图5为本申请实施例中基于射击类游戏的一个游戏图像示意图; 图6为本申请实施例中多任务深度模型的一个结构示意图; 图7为本申请实施例中从游戏视频样本中提取地图样本的一个实施例示意图; 图8为本申请实施例中基于主任务网络输出动作类别概率的一个实施例示意图; 图9为本申请实施例中基于辅助任务网络输出预测地图的一个实施例示意图; 图10为本申请实施例中基于辅助任务网络输出预测地图的另一个实施例示意图; 图11为本申请实施例中游戏测试方法的一个实施例示意图; 图12为本申请实施例中游戏测试报告的一个示意图; 图13为本申请实施例中模拟操作方法的一个实施例示意图; 图14为本申请实施例中模型训练装置的一个实施例示意图; 图15为本申请实施例中游戏测试装置的一个实施例示意图; 图16为本申请实施例中模拟操作装置的一个实施例示意图; 图17为本申请实施例中终端设备的一个结构示意图; 图18为本申请实施例中服务器的一个结构示意图。











