
技术摘要:
本发明涉及一种数据文件快速导入的方法、系统及计算机存储介质,其方法包括,基于分布式文件处理机制,将待导入数据文件拆分成多个拆分数据文件;基于多主机节点并行运行,将分布在各主机节点上的拆分数据文件导入数据库中;基于多主机多线程部署并运行运算,对数据库 全部
背景技术:
新业务的推广往往伴随着成本/收益的控制,这就涉及到用户范围的圈定,而用户 圈定后如何快速与业务挂勾,目前是在业务上增加目标范围这样的规则,但前提是需要将 用户给定的范围按不同的业务不同的打标标识对应入库才能做到。以前该类操作,一个通 宵可分析并处理千万级数量,但随着业务的发展,用户要求的响应速度要达到每小时分析 并处理千万级,那么现有的处理方法无法满足日益增长的业务需求。
技术实现要素:
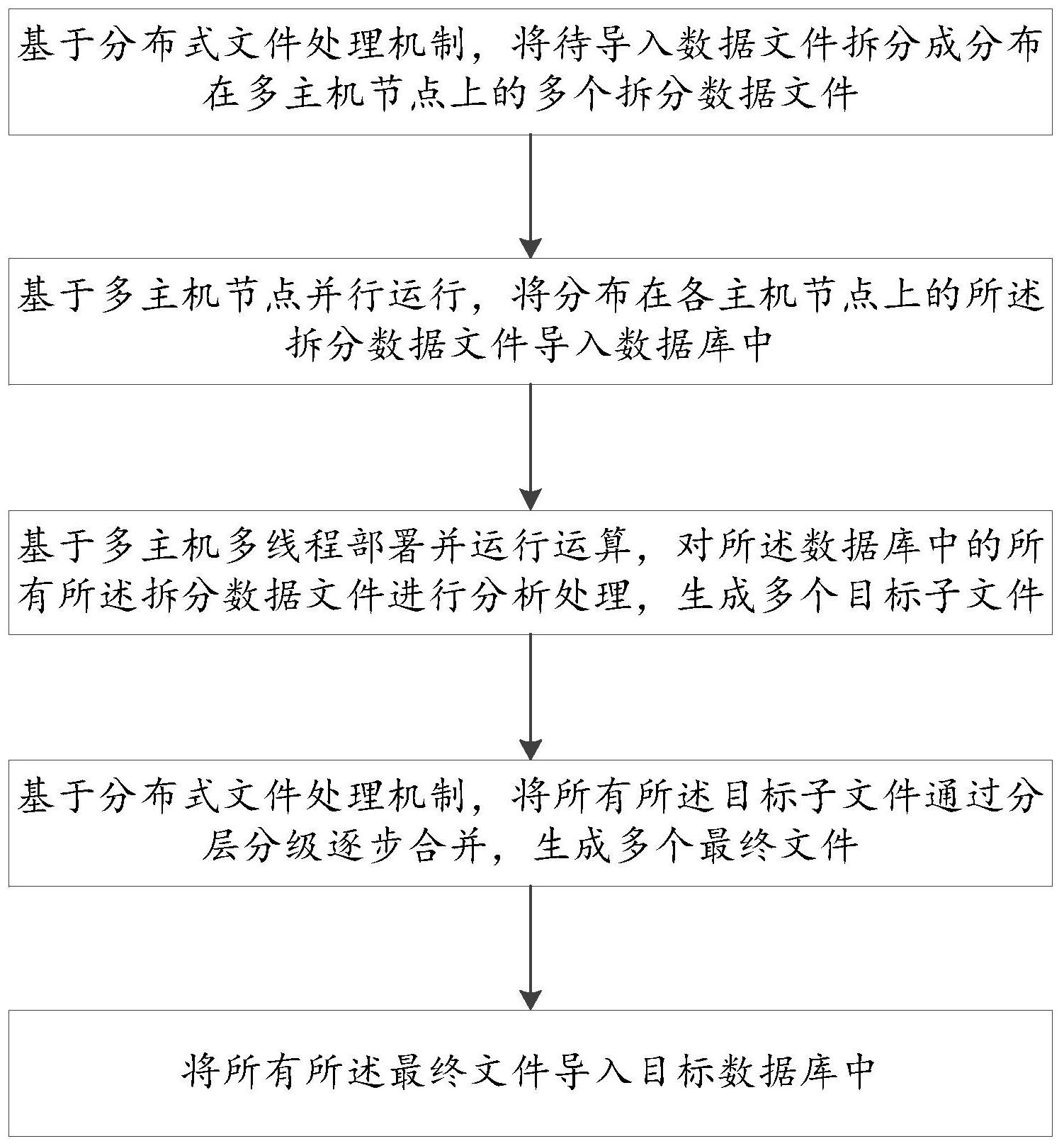
本发明所要解决的技术问题是提供一种数据快速导入的方法、系统及计算机存储 介质,可以实现大数据的快速导入,提升后台批量数据导入的速度,快速响应大批量文件导 入的需求。 本发明解决上述技术问题的技术方案如下:一种数据文件快速导入的方法,包括 以下步骤, S1,基于分布式文件处理机制,将待导入数据文件拆分成分布在多主机节点上的 多个拆分数据文件; S2,基于多主机节点并行运行,将分布在各主机节点上的所述拆分数据文件导入 数据库中; S3,基于多主机多线程部署并运行运算,对所述数据库中的所有所述拆分数据文 件进行分析处理,生成多个目标子文件; S4,基于分布式文件处理机制,将所有所述目标子文件通过分层分级逐步合并,生 成多个最终文件; S5,将所有所述最终文件导入目标数据库中。 在上述技术方案的基础上,本发明还可以做如下改进。 进一步,在所述S1中,所述待导入数据为大数据。 进一步,在所述S1中,所述待导入数据按打标标识进行拆分。 进一步,所述数据库具体为分布式内存数据库。 进一步,所述S3具体为, 基于多主机多线程部署并运行运算以及任务统一调度,通过所述分布式内存数据 库对所有所述拆分数据文件进行细分,通过队列调度机制,筛选出目标数据,生成多个目标 子文件。 进一步,在所述S4中,根据预设的规则将所有所述目标子文件通过分层分级逐步 合并。 4 CN 111597244 A 说 明 书 2/4 页 进一步,在所述S4中,在生成多个所述最终文件后,还包括如下步骤,对多个所述 最终文件的数据操作类型进行归类合并,并送至指定的文件目标主机。 进一步,将所有所述最终文件导入目标数据库中的方法为, 基于关系数据库导入方法,将所有所述最终文件导入目标数据库; 或,利用分布试内存库,将所有所述最终文件高并发导入目标数据库; 或,利用多节点进程多线程并发导入方法,将所有所述最终文件导入目标数据库。 基于上述一种数据快速导入的方法,本发明还提供一种数据快速导入的系统。 一种数据快速导入的系统,包括以下模块, 数据拆分模块,其用于基于分布式文件处理机制,将待导入数据文件拆分成分布 在多主机节点上的多个拆分数据文件; 数据入库模块,其用于基于多主机节点并行运行,将分布在各主机节点上的所述 拆分数据文件导入数据库中; 数据处理模块,其用于基于多主机多线程部署并运行运算,对所述数据库中的所 有所述拆分数据文件进行分析处理,生成多个目标子文件; 数据合并模块,其用于基于分布式文件处理机制,将所有所述目标子文件通过分 层分级逐步合并,生成多个最终文件; 数据导入模块,其用于将所有所述最终文件导入目标数据库中。 基于上述一种数据快速导入的方法,本发明还提供一种计算机存储介质。 一种计算机存储介质,包括存储器,以及存储在所述存储器上的计算机程序,当所 述计算机程序被处理器执行时实现如上述所述的方法步骤。 本发明的有益效果是:本发明一种数据文件快速导入的方法、系统及计算机存储 介质采用分布式文件、多主机节点、多进程、高并发的处理机制将大数据进行拆分—入库— 分析处理—合并—导入几个步骤,可以实现大数据的快速导入;每一个步骤作为单独构件 设计开发,处理过程基础数据配置,处理能力可横向扩展,生成过程数据和结果数据提供监 控服务。本发明主要用于大数据的快速导入分析入表,提升后台批量数据导入的速度,快速 响应大批量文件导入的需求,将后台批量入库的能力提升10倍以上,同时减对需求压力,减 少维护人员的工作,通过前台监控增加提高系统可维护性,导入过程配置化提高系统的可 修改性。 附图说明 图1为本发明一种数据文件快速导入的方法的流程图; 图2为本发明一种数据文件快速导入的方法的原理图; 图3为本发明一种数据文件快速导入的系统的结构框图。











