
技术摘要:
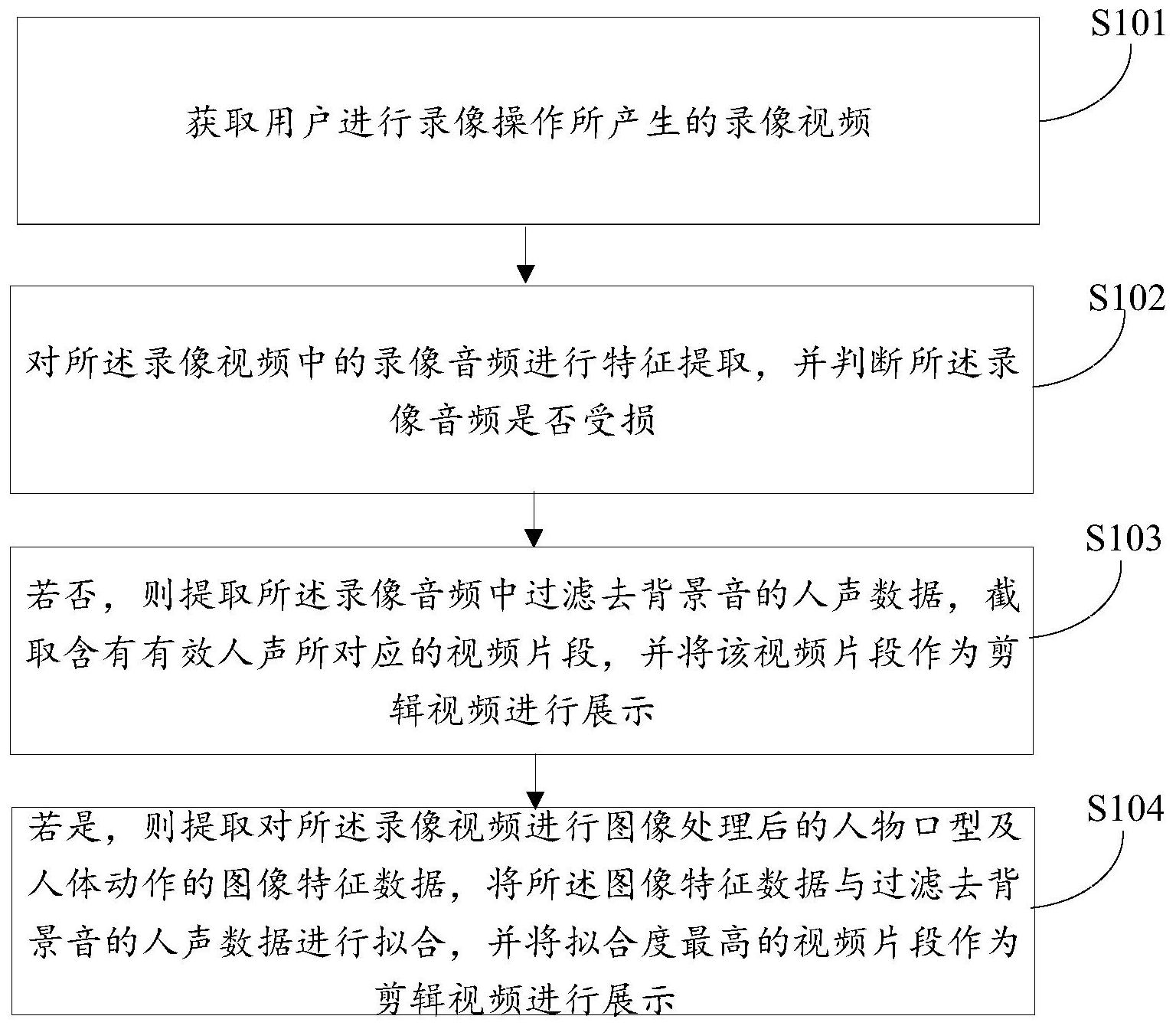
本发明公开了一种利用视频内容进行视频切割的方法及系统,所述方法包括:获取用户进行录像操作所产生的录像视频;对所述录像视频中的录像音频进行特征提取,并判断所述录像音频是否受损;若否,则提取所述录像音频中过滤去背景音的人声数据,截取含有有效人声所对应的 全部
背景技术:
AI剪辑视频技术是运用图像识别或语音识别技术,对视频内容进行智能识别处 理,从而实现对视频内容的智能剪辑,极大提高了视频剪辑效率,节省剪辑成本,因此AI剪 辑视频技术成为了视频剪辑领域重要组成部分。 图像识别自动裁剪视频技作为AI剪辑视频技术中常见的剪辑技术,能够通过人工 智能去识别视频画面内容的指定对象,提取包含此对象的视频画面段,实现在一段或多段 较长的视频中快速识别并剪辑出指定图像对应的片段的技术。 然而,现有的图像识别自动剪辑视频技术只是获取相似图像的片段,对音频不做 处理,吵杂的背景音或不带人声的视频片段也会被保留下来,从而大大降低了用户进行视 频剪辑体验的满意度。
技术实现要素:
为了解决上述问题,本发明的目的是提供一种能够解决现有视频剪辑效率低、视 频质量差,提高用户视频剪辑体验满意度的利用视频内容进行视频切割的方法、系统、介质 及智能设备。 一种利用视频内容进行视频切割的方法,所述方法包括: 获取用户进行录像操作所产生的录像视频; 对所述录像视频中的录像音频进行特征提取,并判断所述录像音频是否受损; 若否,则提取所述录像音频中过滤去背景音的人声数据,截取含有有效人声所对 应的视频片段,并将该视频片段作为剪辑视频进行展示; 若是,则提取对所述录像视频进行图像处理后的人物口型及人体动作的图像特征 数据,将所述图像特征数据与过滤去背景音的人声数据进行拟合,并将拟合度最高的视频 片段作为剪辑视频进行展示。 根据本发明提供的利用视频内容进行视频切割的方法,通过对用户进行录像操作 所产生的录像视频中的录像音频进行特征提取,以判断该录像音频是否受损,当该录像视 频受损则提取所述录像音频中过滤去背景音的人声数据,并截取含有有效人声所对应的视 频片段,以去除吵杂的背景音,并保留带有人声的视频片段,即使在吵杂的环境下拍摄的视 频也能够清楚听到说话者的声音;通过在录像音频受损后,提取对录像视频进行图像处理 后的人物口型及人体动作的图像特征数据,将该图像特征数据与人声数据进行拟合,以输 出拟合度较高的视频片段,实现了在录像音频受损后仍能进行根据录像视频中的图像信息 及已有的有效人声片段的语义进行还原,同时减少了录像音频中的无效内容,使视频中说 话这的声音更加突出,且可根据视频内容进行贴纸及音效等素材的添加与合成,解决了现 4 CN 111556254 A 说 明 书 2/8 页 有视频剪辑效率低、视频质量差,用户剪辑体验满意度低的问题,满足了实际应用需求。 另外,根据本发明上述的利用视频内容进行视频切割的方法,还可以具有如下附 加的技术特征: 进一步地,提取所述音频中过滤去背景音的人声数据,截取含有有效人声所对应 的视频片段,并将该视频片段作为剪辑视频进行展示的方法包括: 通过AI模型对录像视频中的人声视频片段进行识别,提取所述人声视频片段中的 有效人声数据,过滤去背景音,并记录下该有效人声数据所对应的第一时间范围; 将过滤去背景音的有效人声数据转换为文字,并记录该文字对应的第二时间范 围,根据所述第二时间范围对所述第一时间范围进行调整; 根据所述有效人声数据、有效人声数据对应的文字、调整后的时间范围调及录像 视频中的视频画面对含有有效人声数据的视频片段进行剪辑与合成,并将得到的剪辑视频 进行效果展示。 进一步地,提取所述人声视频片段中的有效人声数据,过滤去背景音,并记录下该 有效人声数据所对应的的方法包括: 将所述人声数据切割成多个声音子片段,通过快速傅里叶变换提取各声音子片段 的频率信息,通过基于CNN VAD算法的AI模型及各声音子片段的频率信息对各声音子片段 中的噪声进行滤除后合并成具有连续声音的声音片段,并记录该声音片段所对应的时间段 以作为第一时间范围。 进一步地,提取对所述录像视频进行图像处理后的人物口型及人体动作的图像特 征数据的方法包括: 获取所述录像视频中包含人物说话的图像帧,对该图像帧中的人物口型及人体动 作进行图像识别及分析,以得到人物口型的唇部信息及人体动作的动作信息; 对所述人物口型的唇部信息及人体动作的动作信息进行特征提取,从而得到对应 的图像特征数据。 进一步地,所述方法还包括: 将有效人声数据所对应的文本进行语意分割,以得到多个分割语意; 在素材库中搜索与所述分割语义相匹配的音频及视频贴纸,将与所述分割语义相 匹配的视频贴纸放置于相应的位置,将与所述分割语义相匹配的音频添加至视频片段的对 应位置。 进一步地,将与所述分割语义相匹配的视频贴纸放置于相应的位置,将与所述分 割语义相匹配的音频添加至视频片段的对应位置的方法包括: 根据所需放置视频贴纸的视频画面信息计算贴纸放置的多个有效位置,并根据贴 纸放置的有效位置的调整该视频壁纸的大小; 根据所述有效人声数据所对应的文本及视频画面出现的时间调整所需添加的音 频的时间区域及音轨信息。 进一步地,所述方法还包括: 根据所述视频贴纸与音频所对应的关键词视频音轨中出现的时间,计算该视频贴 纸与音频在视频录像中出现的时间。 本发明的另一实施例提出一种利用视频内容进行视频切割的系统,解决现有的图 5 CN 111556254 A 说 明 书 3/8 页 像识别自动剪辑视频技术只是获取相似图像的片段,对音频不做处理,吵杂的背景音或不 带人声的视频片段也会被保留下来,从而大大降低了用户进行视频剪辑体验的满意度的问 题。 根据本发明实施例的利用视频内容进行视频切割的系统,包括: 获取模块,用于获取用户进行录像操作所产生的录像视频; 判断模块,用于对所述录像视频中的录像音频进行特征提取,并判断所述录像音 频是否受损; 截取模块,用于提取所述录像音频中过滤去背景音的人声数据,截取含有有效人 声所对应的视频片段,并将该视频片段作为剪辑视频进行展示; 拟合模块,用于提取对所述录像视频进行图像处理后的人物口型及人体动作的图 像特征数据,将所述图像特征数据与过滤去背景音的人声数据进行拟合,并将拟合度最高 的视频片段作为剪辑视频进行展示。 本发明的另一个实施例还提出一种介质,其上存储有计算机程序,该程序被处理 器执行时实现上述方法的步骤。 本发明的另一个实施例还提出一种智能设备,包括存储器、处理器以及存储在存 储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述方法。 本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变 得明显,或通过本发明的实施例了解到。 附图说明 图1是本发明第一实施例提出的利用视频内容进行视频切割的方法的流程图; 图2是图1中步骤S101的具体流程图; 图3是图1中步骤S102的具体流程图; 图4是本发明第二实施例提出的利用视频内容进行视频切割的系统的结构框图。











