
技术摘要:
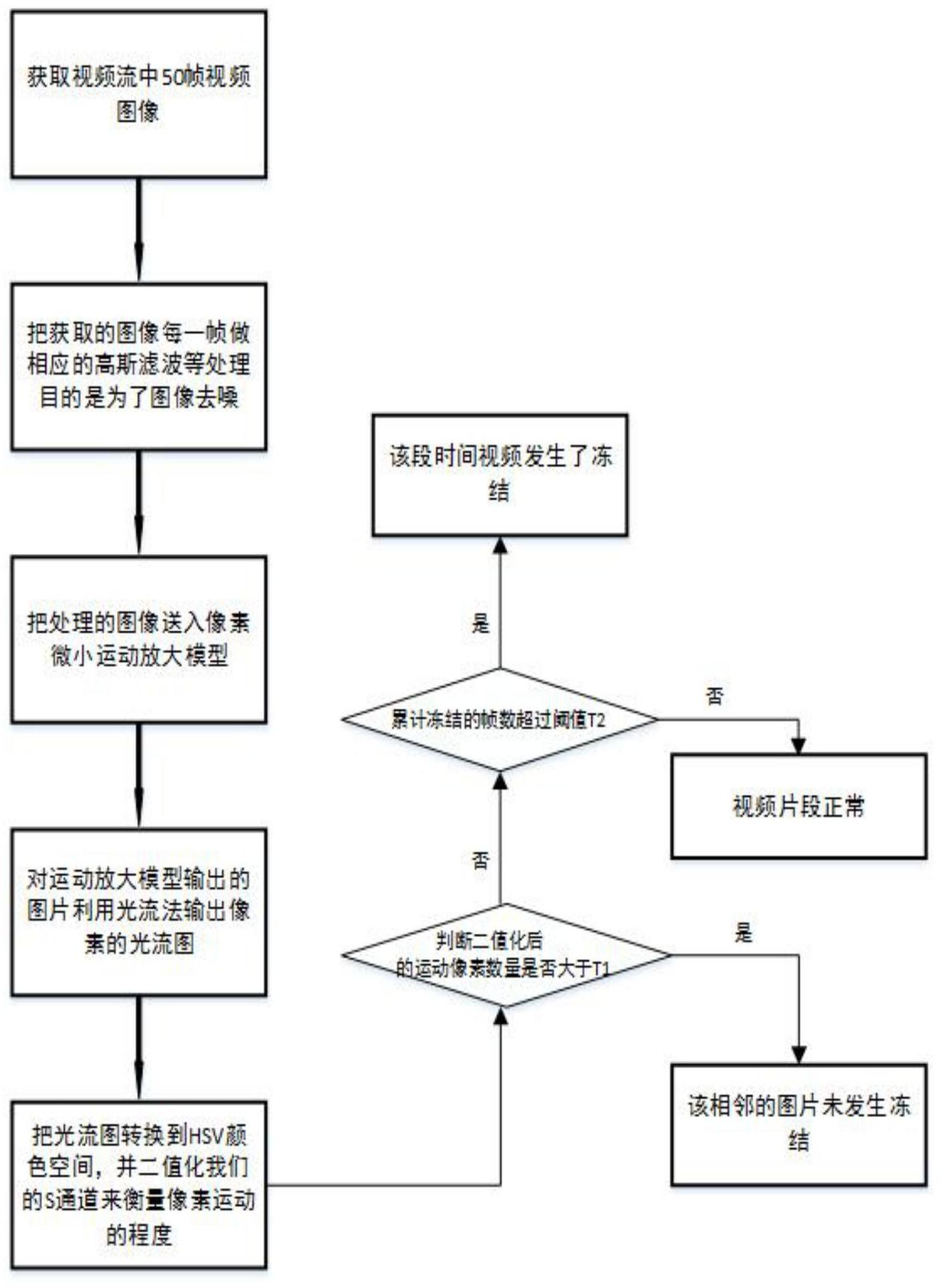
本发明公开了一种基于像素运动智能感知的画面冻结检测方法,属于视频图像诊断技术领域,包括如下步骤:获取摄像机视频流检测序列和50帧图片;利用高斯滤波核卷积对应的50帧图片;利用深度学习建立网络模型,并使该模型通过结合图片上下帧的动态信息,对图片中微小的像 全部
背景技术:
视频冻结,即IP摄像机因为网络的干扰或者在视频传输过程中系统的故障引起的 视频画面冻结,具体表现可为视频画面不变时间在不停变化,或者是时间和视频的画面都 没有发生任何的变化。并且这种情况需要存在一定时长的时间才认定为该摄像机发生了视 频画面冻结。对于偶尔发生的短暂的视频画面冻结现象,应该排除在视频冻结之外。 视频画面冻结诊断的基础是算法是否能判断出画面存在细微的变化以区别一个 场景不变的画面,这需要对比前后多帧的图像变化。现有的技术中判断视频是否发生冻结 的方法主要有利用像素直方图统计变化和判断图片画面相似度的程度。但是这些方法判断 准确度都不是非常高。其中判断直方图统计变化是根据前后帧的图片像素信息来判断视频 画面是不是发生冻结,这种方法对于微小的变化并不是非常明显,因此有时很容易会对没 有物体运动的画面误检为冻结。判断图片相似度的方法主要是根据同一像素位置的差异值 T,对连续获得的视频帧做差分,统计变化的像素个数,达到一定的比例后,就认为当前帧画 面发生变化,否则认为当前帧冻结,累计N帧后判定监控画面冻结,该方法对于复杂的环境 没有很好的适应性,因此测试环境一多,对于阈值的设定就会变得极为依赖。
技术实现要素:
本发明的主要目的是为了解决现有技术的不足,而提供一种基于像素运动智能感 知的画面冻结检测方法。 本发明的目的可以通过采用如下技术方案达到: 一种基于像素运动智能感知的画面冻结检测方法,包括如下步骤: 步骤1:获取摄像机视频流检测序列和50帧图片; 步骤2:利用高斯滤波核卷积对应的50帧图片; 步骤3:利用深度学习建立网络模型,并使该模型通过结合图片上下帧的动态信 息,对图片中微小的像素运动进行放大,并输出运动放大的灰度图; 步骤4:针对步骤3中输出的灰度图通过公式0.299×R 0.587×G 0.114×B,得到 每个视频帧的亮度信息,并对灰度图利用DIS光流进行动态分析,结果是得到多张光流场图 像; 步骤5:将得到的光流场转换到HSV颜色空间,其中光流中的数值用不同的颜色去 区分; 步骤6:设置阈值T1,利用T1判断HSV中颜色是否发生变化,若发生变化的像素大于 T1则判定该图像中存在运动物体,反之,则判定为冻结; 步骤7:排除50帧中偶然的因素,额外增设了阈值T2,其中T2是用来比较发生冻结 4 CN 111582076 A 说 明 书 2/6 页 的比率, M表示发生冻结的帧数,若radio>T2则认为在该50帧视频中发生了冻 结,若radio











