
技术摘要:
本发明公开了一种语句识别方法和装置、存储介质及电子设备。其中,该方法包括:获取待识别的语句数据,将语句数据执行分词操作,得到词表数据,将得到的词表数据输入到训练好语言模型得到用于表示语句数据中是否包含异常数据的识别结果,上述语言模型是使用未标注的样 全部
背景技术:
在当前进行语句识别的过程中,存在多种不同的语句数据来源,例如公众号文章、 外链文章、新闻、视频、网页、小程序、用户搜索等,上述数据被综合运用到相关的产品中。其 中,对于上述数据中的部分语句信息需要根据实际需求进行进一步的过滤,相关技术中对 不同来源的语句数据进行检测和过滤是通过大量的标注数据作为训练样本进行有监督的 语言模型训练,同时生成的语言模型大多只适用于标注样本所在的语句领域(例如文章标 题),当同一语言模型迁移到其他语句领域(即数据来源)时,会由于不同领域间的数据分布 差异导致语言模型迁移效果很差,同时,面对众多的领域,分别标注大量的数据也是费时费 力的。 针对上述的问题,目前尚未提出有效的解决方案。
技术实现要素:
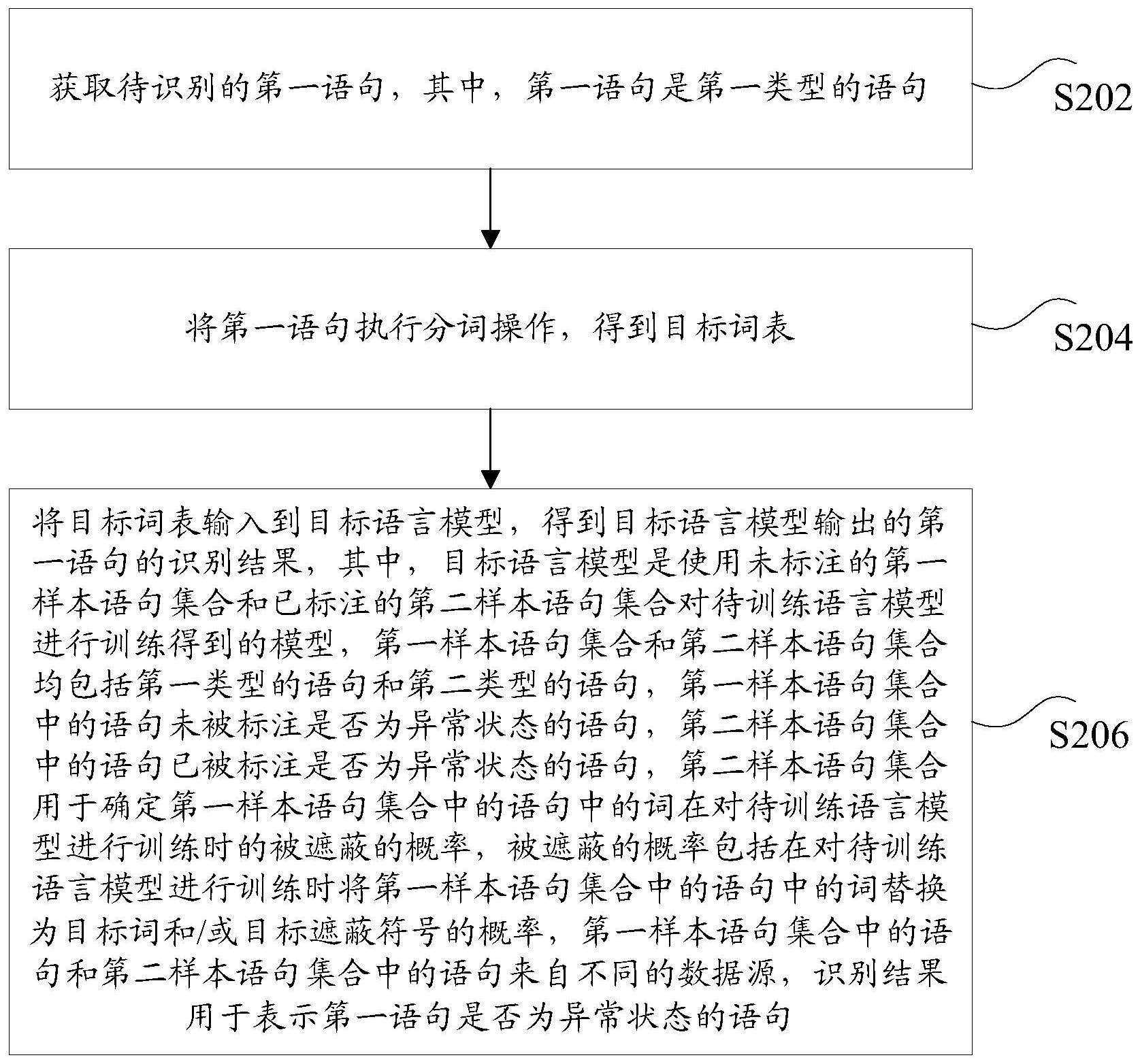
本发明实施例提供了一种语句识别方法和装置、存储介质及电子设备,以至少解 决相关技术中存在的不同领域间的语句识别训练模型迁移效果较差,难以有效完成对目标 语句识别的技术问题。 根据本发明实施例的一个方面,提供了一种语句识别方法,包括:获取待识别的第 一语句,其中,所述第一语句是第一类型的语句;将所述第一语句执行分词操作,得到目标 词表;将所述目标词表输入到目标语言模型,得到所述目标语言模型输出的所述第一语句 的识别结果,其中,所述目标语言模型是使用未标注的第一样本语句集合和已标注的第二 样本语句集合对待训练语言模型进行训练得到的模型,所述第一样本语句集合和所述第二 样本语句集合均包括所述第一类型的语句和第二类型的语句,所述第一样本语句集合中的 语句未被标注是否为异常状态的语句,所述第二样本语句集合中的语句已被标注是否为异 常状态的语句,所述第二样本语句集合用于确定所述第一样本语句集合中的语句中的词在 对所述待训练语言模型进行训练时的被遮蔽的概率,所述被遮蔽的概率包括在对所述待训 练语言模型进行训练时将所述第一样本语句集合中的语句中的词替换为目标词和/或目标 遮蔽符号的概率,所述第一样本语句集合中的语句和所述第二样本语句集合中的语句来自 不同的数据源,所述识别结果用于表示所述第一语句是否为所述异常状态的语句。 可选地,在所述将所述目标词表输入到目标语言模型,得到所述目标语言模型输 出的所述第一语句的识别结果之后,所述方法还包括:在所述识别结果表示所述第一语句 为所述异常状态的语句的情况下,执行以下至少之一操作:将所述第一语句中属于所述异 常状态的词语进行屏蔽;将所述第一语句中属于所述异常状态的词语替换为目标符号;将 所述第一语句从目标数据库中删除,其中,所述目标数据库用于记录所述第一类型的媒体 6 CN 111597306 A 说 明 书 2/21 页 资源的语句;和/或在所述识别结果表示所述第一语句不为所述异常状态的语句的情况下, 将所述第一语句传输给目标应用。 可选地,在所述将所述目标词表输入到目标语言模型,得到所述目标语言模型输 出的所述第一语句的识别结果之前,所述方法还包括:对所述第一样本语句集合中包括的 所述第一类型的语句和所述第二类型的语句进行合并和分词操作,得到第一样本词表,并 对所述第二样本语句集合中包括的所述第一类型的语句和所述第二类型的语句进行合并 和分词操作,得到第二样本词表;确定所述第二样本词表对应的目标映射序列,其中,所述 目标映射序列中的每个成员用于表示所述第二样本词表中的一个词以及所述一个词的贡 献度参数的排名,所述一个词的贡献度参数用于表示所述一个词对被标注为所述异常状态 的语句的贡献度;根据所述目标映射序列确定所述第一样本词表中的每个词在对所述待训 练语言模型进行训练时的被遮蔽的概率;使用所述第一样本词表以及所述第一样本词表中 的每个词的所述概率对所述待训练语言模型进行训练,得到训练后的语言模型;根据所述 训练后的语言模型确定所述目标语言模型。 可选地,所述确定所述第二样本词表对应的目标映射序列,包括:对所述第二样本 词表中的词进行互信息计算,得到所述第二样本词表中的每个词的所述贡献度参数;按照 所述贡献度参数的取值从大到小对所述第二样本词表中的词进行排序,得到所述第二样本 词表中的每个词的排名;将所述第二样本词表中的每个词和所述每个词的排名组成所述目 标映射序列中的一个成员,得到所述目标映射序列。 可选地,所述根据所述目标映射序列确定所述第一样本词表中的每个词在对所述 待训练语言模型进行训练时的被遮蔽的概率,包括:确定所述第一样本词表和所述第二样 本词表都包括的第一组词;将所述第一样本词表中的所述第一组词的排名设置为等于所述 第一组词在所述目标映射序列中的排名,并将所述第一样本词表中的第二组词的排名设置 为目标值,所述目标值大于所述目标映射序列中的最大排名,所述第二组词为所述第一样 本词表中的不包括在所述第二样本词表中的词;根据所述第一样本词表中的每个词的排名 确定所述第一样本词表中的每个词的所述概率。 可选地,所述根据所述第一样本词表中的每个词的排名确定所述第一样本词表中 的每个词的所述概率,包括:通过如下公式确定所述第一样本词表中的每个词的所述概率: Probi=n/(Si 1),其中,Probi表示所述第一样本词表中的第i个词的所述概率、n为预设的 遮蔽概率系数、Si表示所述第一样本词表中的第i个词的排名。 可选地,所述使用所述第一样本词表以及所述第一样本词表中的每个词的所述概 率对所述待训练语言模型进行训练,得到训练后的语言模型,包括:根据所述第一样本词表 中的每个词的所述概率,确定所述第一样本词表中的每个词需要被替换为目标词、还是不 被替换、还是需要被替换为目标遮蔽符号;在确定出所述第一样本词表中的第一词需要被 替换为所述目标词的情况下,将所述第一词替换为所述目标词,并使用所述目标词对所述 待训练语言模型进行训练;在确定出所述第一样本词表中的第二词不被替换的情况下,使 用所述第二词对所述待训练语言模型进行训练;在确定出所述第一样本词表中的第三词需 要被替换为所述目标遮蔽符号的情况下,将所述第三词替换为所述目标遮蔽符号,并使用 所述目标遮蔽符号对所述待训练语言模型进行训练。 可选地,所述根据所述训练后的语言模型确定所述目标语言模型,包括:将所述训 7 CN 111597306 A 说 明 书 3/21 页 练后的语言模型确定为所述目标语言模型。 可选地,所述根据所述训练后的语言模型确定所述目标语言模型,包括:使用所述 第二样本语句集合中包括的所述第一类型的语句对所述训练后的语言模型进行优化处理, 得到第一语言模型;使用所述第二样本语句集合中包括的所述第二类型的语句对所述第一 语言模型进行优化处理,得到目标语言模型,其中,所述目标语言模型与所述第二样本语句 集合中包括的所述第一类型的适配度大于所述第一语言模型与所述第二样本语句集合中 包括的所述第一类型的适配度,所述第一语言模型与所述第二样本语句集合中包括的所述 第一类型的适配度大于所述训练后的语言模型与所述第二样本语句集合中包括的所述第 一类型的适配度。 根据本发明实施例的一个方面,提供了一种语言模型的训练方法,包括: 获取未标注的第一样本语句集合和已标注的第二样本语句集合,其中,所述第一 样本语句集合和所述第二样本语句集合均包括所述第一类型的语句和第二类型的语句,所 述第一样本语句集合中的语句未被标注是否为异常状态的语句,所述第二样本语句集合中 的语句已被标注是否为异常状态的语句,所述第二样本语句集合用于确定所述第一样本语 句集合中的语句中的词在对所述待训练语言模型进行训练时的被遮蔽的概率,所述被遮蔽 的概率包括在对所述待训练语言模型进行训练时将所述第一样本语句集合中的语句中的 词替换为目标词和/或目标遮蔽符号的概率,所述第一样本语句集合中的语句和所述第二 样本语句集合中的语句来自不同的数据源; 使用所述未标注的第一样本语句集合和所述已标注的第二样本语句集合对待训 练语言模型进行训练,得到训练后的语言模型; 根据所述训练后的语言模型确定所述目标语言模型。 可选地,所述使用所述未标注的第一样本语句集合和所述已标注的第二样本语句 集合对待训练语言模型进行训练,得到训练后的语言模型,包括:对所述第一样本语句集合 中包括的所述第一类型的语句和所述第二类型的语句进行合并和分词操作,得到第一样本 词表,并对所述第二样本语句集合中包括的所述第一类型的语句和所述第二类型的语句进 行合并和分词操作,得到第二样本词表;确定所述第二样本词表对应的目标映射序列,其 中,所述目标映射序列中的每个成员用于表示所述第二样本词表中的一个词以及所述一个 词的贡献度参数的排名,所述一个词的贡献度参数用于表示所述一个词对被标注为所述异 常状态的语句的贡献度; 根据所述目标映射序列确定所述第一样本词表中的每个词在对所述待训练语言 模型进行训练时的被遮蔽的概率; 使用所述第一样本词表以及所述第一样本词表中的每个词的所述概率对所述待 训练语言模型进行训练,得到所述训练后的语言模型。 可选地,所述确定所述第二样本词表对应的目标映射序列,包括: 对所述第二样本词表中的词进行互信息计算,得到所述第二样本词表中的每个词 的所述贡献度参数; 按照所述贡献度参数的取值从大到小对所述第二样本词表中的词进行排序,得到 所述第二样本词表中的每个词的排名; 将所述第二样本词表中的每个词和所述每个词的排名组成所述目标映射序列中 8 CN 111597306 A 说 明 书 4/21 页 的一个成员,得到所述目标映射序列。 可选地,所述根据所述目标映射序列确定所述第一样本词表中的每个词在对所述 待训练语言模型进行训练时的被遮蔽的概率,包括: 确定所述第一样本词表和所述第二样本词表都包括的第一组词; 将所述第一样本词表中的所述第一组词的排名设置为等于所述第一组词在所述 目标映射序列中的排名,并将所述第一样本词表中的第二组词的排名设置为目标值,所述 目标值大于所述目标映射序列中的最大排名,所述第二组词为所述第一样本词表中的不包 括在所述第二样本词表中的词; 根据所述第一样本词表中的每个词的排名确定所述第一样本词表中的每个词的 所述概率。 可选地,所述使用所述第一样本词表以及所述第一样本词表中的每个词的所述概 率对所述待训练语言模型进行训练,得到训练后的语言模型,包括: 根据所述第一样本词表中的每个词的所述概率,确定所述第一样本词表中的每个 词需要被替换为目标词、还是不被替换、还是需要被替换为目标遮蔽符号; 在确定出所述第一样本词表中的第一词需要被替换为所述目标词的情况下,将所 述第一词替换为所述目标词,并使用所述目标词对所述待训练语言模型进行训练; 在确定出所述第一样本词表中的第二词不被替换的情况下,使用所述第二词对所 述待训练语言模型进行训练; 在确定出所述第一样本词表中的第三词需要被替换为所述目标遮蔽符号的情况 下,将所述第三词替换为所述目标遮蔽符号,并使用所述目标遮蔽符号对所述待训练语言 模型进行训练。 可选地,所述根据所述训练后的语言模型确定所述目标语言模型,包括: 将所述训练后的语言模型确定为所述目标语言模型;或者 使用所述第二样本语句集合中包括的所述第一类型的语句对所述训练后的语言 模型进行优化处理,得到第一语言模型;使用所述第二样本语句集合中包括的所述第二类 型的语句对所述第一语言模型进行优化处理,得到目标语言模型,其中,所述目标语言模型 与所述第二样本语句集合中包括的所述第一类型的适配度大于所述第一语言模型与所述 第二样本语句集合中包括的所述第一类型的适配度,所述第一语言模型与所述第二样本语 句集合中包括的所述第一类型的适配度大于所述训练后的语言模型与所述第二样本语句 集合中包括的所述第一类型的适配度。 根据本发明实施例的另一方面,还提供了一种语句识别装置,包括:获取模块,用 于获取待识别的第一语句,其中,所述第一语句是第一类型的语句;分词模块,用于将所述 第一语句执行分词操作,得到目标词表;处理模块,用于将所述目标词表输入到目标语言模 型,得到所述目标语言模型输出的所述第一语句的识别结果,其中,所述目标语言模型是使 用未标注的第一样本语句集合和已标注的第二样本语句集合对待训练语言模型进行训练 得到的模型,所述第一样本语句集合和所述第二样本语句集合均包括所述第一类型的语句 和第二类型的语句,所述第一样本语句集合中的语句未被标注是否为异常状态的语句,所 述第二样本语句集合中的语句已被标注是否为异常状态的语句,所述第二样本语句集合用 于确定所述第一样本语句集合中的语句中的词在对所述待训练语言模型进行训练时的被 9 CN 111597306 A 说 明 书 5/21 页 遮蔽的概率,所述被遮蔽的概率包括在对所述待训练语言模型进行训练时将所述第一样本 语句集合中的语句中的词替换为目标词和/或目标遮蔽符号的概率,所述第一样本语句集 合中的语句和所述第二样本语句集合中的语句来自不同的数据源,所述识别结果用于表示 所述第一语句是否为所述异常状态的语句。 可选地,所述装置还用于:在所述将所述目标词表输入到目标语言模型,得到所述 目标语言模型输出的所述第一语句的识别结果之后,在所述识别结果表示所述第一语句为 所述异常状态的语句的情况下,执行以下至少之一操作:将所述第一语句中属于所述异常 状态的词语进行屏蔽;将所述第一语句中属于所述异常状态的词语替换为目标符号;将所 述第一语句从目标数据库中删除,其中,所述目标数据库用于记录所述第一类型的媒体资 源的语句;和/或在所述识别结果表示所述第一语句不为所述异常状态的语句的情况下,将 所述第一语句传输给目标应用。 可选地,所述装置还用于:在所述将所述目标词表输入到目标语言模型,得到所述 目标语言模型输出的所述第一语句的识别结果之前,对所述第一样本语句集合中包括的所 述第一类型的语句和所述第二类型的语句进行合并和分词操作,得到第一样本词表,并对 所述第二样本语句集合中包括的所述第一类型的语句和所述第二类型的语句进行合并和 分词操作,得到第二样本词表;确定所述第二样本词表对应的目标映射序列,其中,所述目 标映射序列中的每个成员用于表示所述第二样本词表中的一个词以及所述一个词的贡献 度参数的排名,所述一个词的贡献度参数用于表示所述一个词对被标注为所述异常状态的 语句的贡献度;根据所述目标映射序列确定所述第一样本词表中的每个词在对所述待训练 语言模型进行训练时的被遮蔽的概率;使用所述第一样本词表以及所述第一样本词表中的 每个词的所述概率对所述待训练语言模型进行训练,得到训练后的语言模型;根据所述训 练后的语言模型确定所述目标语言模型。 可选地,所述装置用于通过如下方式确定所述第二样本词表对应的目标映射序 列:对所述第二样本词表中的词进行互信息计算,得到所述第二样本词表中的每个词的所 述贡献度参数;按照所述贡献度参数的取值从大到小对所述第二样本词表中的词进行排 序,得到所述第二样本词表中的每个词的排名;将所述第二样本词表中的每个词和所述每 个词的排名组成所述目标映射序列中的一个成员,得到所述目标映射序列。 可选地,所述装置用于通过如下方式根据所述目标映射序列确定所述第一样本词 表中的每个词在对所述待训练语言模型进行训练时的被遮蔽的概率:确定所述第一样本词 表和所述第二样本词表都包括的第一组词;将所述第一样本词表中的所述第一组词的排名 设置为等于所述第一组词在所述目标映射序列中的排名,并将所述第一样本词表中的第二 组词的排名设置为目标值,所述目标值大于所述目标映射序列中的最大排名,所述第二组 词为所述第一样本词表中的不包括在所述第二样本词表中的词;根据所述第一样本词表中 的每个词的排名确定所述第一样本词表中的每个词的所述概率。 可选地,所述装置用于通过如下方式根据所述第一样本词表中的每个词的排名确 定所述第一样本词表中的每个词的所述概率:通过如下公式确定所述第一样本词表中的每 个词的所述概率:Probi=n/(Si 1),其中,Probi表示所述第一样本词表中的第i个词的所述 概率、n为预设的遮蔽概率系数、Si表示所述第一样本词表中的第i个词的排名。 可选地,所述处理模块,包括:确定单元,用于根据所述第一样本词表中的每个词 10 CN 111597306 A 说 明 书 6/21 页 的所述概率,确定所述第一样本词表中的每个词需要被替换为目标词、还是不被替换、还是 需要被替换为目标遮蔽符号;第一处理单元,用于在确定出所述第一样本词表中的第一词 需要被替换为所述目标词的情况下,将所述第一词替换为所述目标词,并使用所述目标词 对所述待训练语言模型进行训练;第二处理单元,用于在确定出所述第一样本词表中的第 二词不被替换的情况下,使用所述第二词对所述待训练语言模型进行训练;第三处理单元, 用于在确定出所述第一样本词表中的第三词需要被替换为所述目标遮蔽符号的情况下,将 所述第三词替换为所述目标遮蔽符号,并使用所述目标遮蔽符号对所述待训练语言模型进 行训练。 可选地,所述装置用于通过如下方式根据所述训练后的语言模型确定所述目标语 言模型:将所述训练后的语言模型确定为所述目标语言模型。 可选地,所述装置用于通过如下方式根据所述训练后的语言模型确定所述目标语 言模型:使用所述第二样本语句集合中包括的所述第一类型的语句对所述训练后的语言模 型进行优化处理,得到第一语言模型;使用所述第二样本语句集合中包括的所述第二类型 的语句对所述第一语言模型进行优化处理,得到目标语言模型,其中,所述目标语言模型与 所述第二样本语句集合中包括的所述第一类型的适配度大于所述第一语言模型与所述第 二样本语句集合中包括的所述第一类型的适配度,所述第一语言模型与所述第二样本语句 集合中包括的所述第一类型的适配度大于所述训练后的语言模型与所述第二样本语句集 合中包括的所述第一类型的适配度。 根据本发明实施例的又一方面,还提供了一种计算机可读的存储介质,该计算机 可读的存储介质中存储有计算机程序,其中,该计算机程序被设置为运行时执行上述语句 识别方法。 根据本发明实施例的又一方面,还提供了一种电子设备,包括存储器和处理器,上 述存储器中存储有计算机程序,上述处理器被设置为通过所述计算机程序执行上述的语句 识别方法。 在本发明实施例中,采用获取待识别的语句数据,将语句数据执行分词操作,得到 词表数据,将得到的词表数据输入到训练好语言模型得到用于表示语句数据中是否包含异 常数据的识别结果,上述语言模型是使用未标注的样本语句集合和已标注的样本语句集合 对待训练语言模型进行训练得到的模型,样本语句集合中包括第一样本语句集合和第二样 本语句集合,第一样本语句集合中的语句和第二样本语句集合中的语句来自不同的数据源 的方式,通过针对不同数据源的语句数据对语言模型进行训练,达到了不同领域间的语言 模型能够实现迁移的目的,从而实现了提高语句识别效率,降低语句识别成本的技术效果, 进而解决了相关技术中存在的不同领域间的语句识别训练模型迁移效果较差,难以有效完 成对目标语句识别的技术问题。 附图说明 此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,本发 明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中: 图1是根据本发明实施例的一种可选的语句识别方法的应用环境的示意图; 图2是根据本发明实施例的一种可选的语句识别方法的流程示意图; 11 CN 111597306 A 说 明 书 7/21 页 图3是根据本发明实施例的另一种可选的语句识别方法的流程示意图; 图4是根据本发明实施例的又一种可选的语句识别方法的流程示意图; 图5是根据本发明实施例的一种可选的语句识别方法的示意图; 图6是根据本发明实施例的另一种可选的语句识别方法的示意图; 图7是根据本发明实施例的又一种可选的语句识别方法的流程示意图; 图8是根据本发明实施例的一种可选的语言模型的训练方法的流程示意图; 图9是根据本发明实施例的一种可选的语句识别装置的结构示意图; 图10是根据本发明实施例的另一种可选的语句识别装置的结构示意图; 图11是根据本发明实施例的一种可选的电子设备的结构示意图。











