
技术摘要:
本发明提供一种医疗文本搜索方法及相关设备。所述方法获取多个医疗文本;对多个医疗文本中的每个医疗文本进行医疗命名实体识别,得到每个医疗文本的多个医疗命名实体;接收请求方的搜索请求;对待搜索文本进行扩展;对扩展后的待搜索文本进行医疗命名实体识别;在多个 全部
背景技术:
蕴含在医疗文本中的知识对生物医学的医疗实践、教学和科研都有重要的意义。 而医疗文本的巨大数量使得人们在海量的文献集中发现和获取这些有用的信息变得愈加 困难。因此,针对海量医疗文本的准确的搜索工具成为相关人员的迫切需要。
技术实现要素:
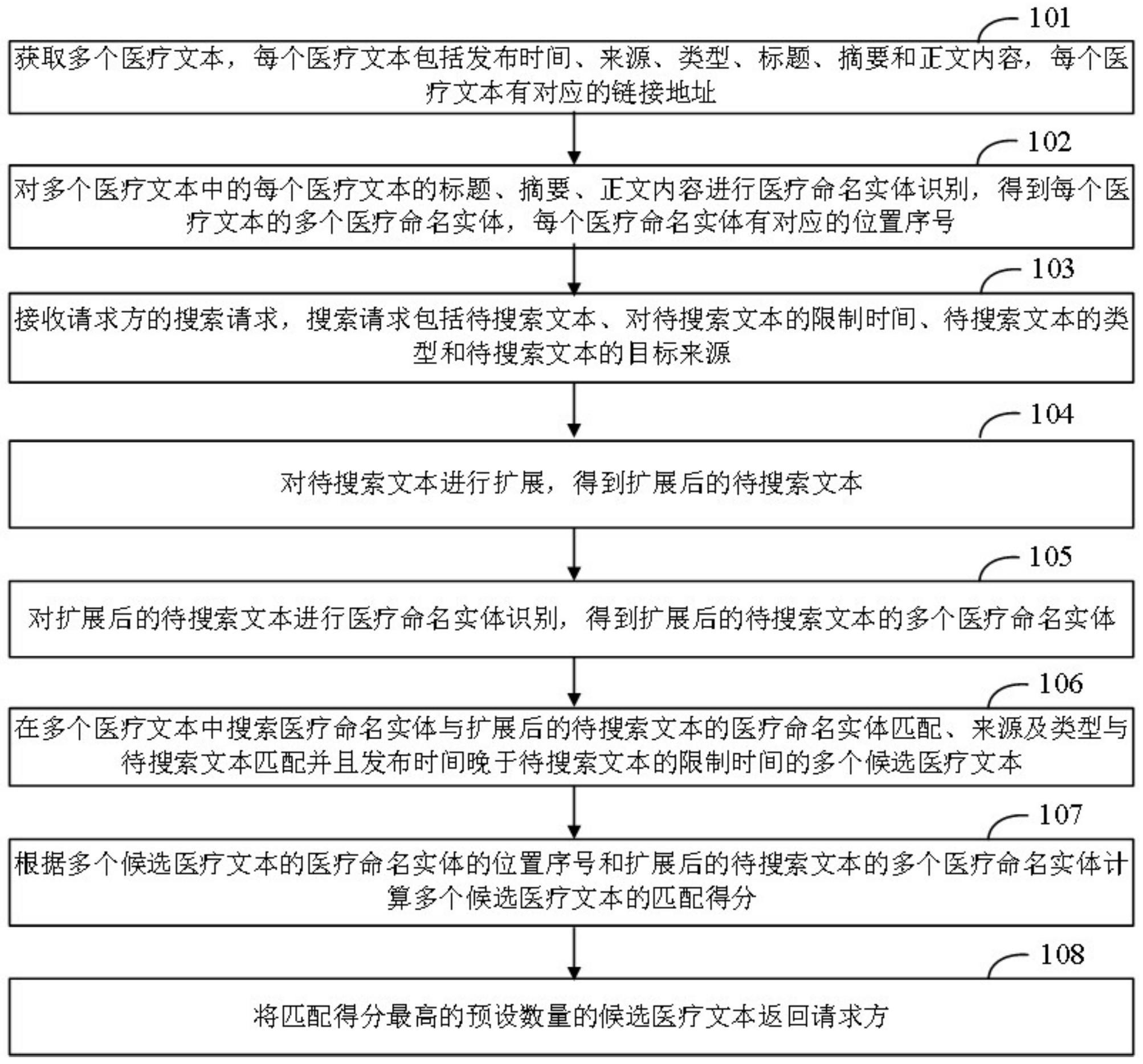
鉴于以上内容,有必要提出一种医疗文本搜索方法、装置、计算机设备及计算机存 储介质,其可以识别待识别药物语句中的药物。 本申请的第一方面提供一种医疗文本搜索方法,所述方法包括: 获取多个医疗文本,每个医疗文本包括发布时间、来源、类型、标题、摘要和正文内 容,每个医疗文本有对应的链接地址; 对所述多个医疗文本中的每个医疗文本的标题、摘要、正文内容进行医疗命名实 体识别,得到每个医疗文本的多个医疗命名实体,每个医疗命名实体有对应的位置序号; 接收请求方的搜索请求,所述搜索请求包括待搜索文本、对所述待搜索文本的限 制时间、所述待搜索文本的类型和所述待搜索文本的目标来源; 对所述待搜索文本进行扩展,得到扩展后的待搜索文本; 对所述扩展后的待搜索文本进行医疗命名实体识别,得到所述扩展后的待搜索文 本的多个医疗命名实体; 在所述多个医疗文本中搜索医疗命名实体与所述扩展后的待搜索文本的医疗命 名实体匹配、来源及类型与所述待搜索文本匹配并且发布时间晚于所述待搜索文本的限制 时间的多个候选医疗文本; 根据所述多个候选医疗文本的医疗命名实体的位置序号和所述扩展后的待搜索 文本的多个医疗命名实体计算所述多个候选医疗文本的匹配得分; 将匹配得分最高的预设数量的候选医疗文本返回所述请求方。 另一种可能的实现方式中,所述对所述多个医疗文本中的每个医疗文本的标题、 摘要、正文内容进行医疗命名实体识别包括: 对每个医疗文本的标题、摘要、正文内容进行分句、去重、错误修正预处理,得到预 处理后的文本内容; 将所述预处理后的文本内容中的每个语句转化为向量序列; 将每个语句对应的向量序列输入训练好的第一双向长短时记忆网络,得到该语句 的特征向量序列,将该语句的特征向量序列输入训练好的第一条件随机场,得到该语句的 标记序列; 5 CN 111581337 A 说 明 书 2/15 页 根据所述预处理后的文本内容中的每个语句的标记序列识别医疗命名实体。 另一种可能的实现方式中,在所述对所述多个医疗文本中的每个医疗文本的标 题、摘要、正文内容进行医疗命名实体识别之前,所述方法还包括: 获取医疗训练语句和所述医疗训练语句的标签向量序列; 将所述医疗训练语句转化为向量序列; 将所述医疗训练语句的向量序列输入所述第一双向长短时记忆网络,得到所述医 疗训练语句的特征向量序列,将所述医疗训练语句的特征向量序列输入所述第一条件随机 场,得到所述医疗训练语句的标记序列; 根据所述医疗训练语句的标签向量序列和标记序列通过梯度下降法调整所述第 一双向长短时记忆网络和所述第一条件随机场的隐藏层的权重和偏置值。 另一种可能的实现方式中,所述对所述待搜索文本进行扩展包括: 对所述待搜索文本进行分词处理,得到多个目标词语; 确定所述多个词语中每个目标词语的近义词集合; 在所述待搜索文本中用每个目标词语的近义词集合中的词语替换该目标词语,将 每次替换后的所述待搜索文本确定为一个扩展后的待搜索文本。 另一种可能的实现方式中,所述确定所述多个词语中每个目标词语的近义词集合 包括: 从预设近义词词典中查询该目标词语的近义词;和/或 获取历史搜索信息,从所述历史搜索信息中标记的医疗文本中确定该目标词语的 近义词;和/或 从所述待搜索文本中删除该目标词语,得到该目标词语的匹配模板,从所述多个 医疗文本中查找所述匹配模板,将查找到的所述匹配模板所在的语句中与该目标词语对应 的词语确定为该目标词语的近义词,其中,该目标词语在所述匹配模板中的位置与该目标 词语对应的词语在查找到的所述匹配模板中的位置一致。 另一种可能的实现方式中,所述对所述扩展后的待搜索文本进行医疗命名实体识 别包括: 对所述扩展后的待搜索文本进行预处理,得到预处理后的扩展后的待搜索文本; 将所述预处理后的扩展后的待搜索文本中的每个语句转化为向量序列; 将每个语句对应的向量序列输入训练好的第二双向长短时记忆网络,得到该语句 的特征向量序列,将该语句的特征向量序列输入训练好的第二条件随机场,得到该语句的 标记序列; 根据所述预处理后的文本内容中的每个语句的标记序列识别医疗命名实体。 另一种可能的实现方式中,所述根据所述多个候选医疗文本的医疗命名实体的位 置序号和所述扩展后的待搜索文本的多个医疗命名实体计算所述多个候选医疗文本的匹 配得分包括: 对于所述多个候选医疗文本中的第i个医疗文本,1≤i≤n,n为所述多个候选医疗 文本的数量,根据第i个医疗文本中与所述扩展后的待搜索文本的多个医疗命名实体一致 的医疗命名实体的位置序号确定第i个医疗文本的位置权重Wi: 6 CN 111581337 A 说 明 书 3/15 页 其中,mi为第i个医疗文本中与所述扩展后的待搜索文本的多个医疗命名实体一 致的医疗命名实体的数量,Oi ,j表示第i个医疗文本中第j个医疗命名实体的位置序号,Ei ,1 表示位于第i个医疗文本的标题的位置序号的集合,Ei ,2表示位于第i个医疗文本的摘要的 位置序号的集合,Ei ,3表示位于第i个医疗文本的正文内容的头尾语句的位置序号的集合, Ei ,4表示位于第i个医疗文本的正文内容的非头尾语句的位置序号的集合,d1、d2、d3和d4为 预设值; 根据第i个医疗文本的医疗命名实体和所述扩展后的待搜索文本的医疗命名实体 计算第i个医疗文本的长度匹配度li: 其中,Ci表示第i个医疗文本中与所述扩展后的待搜索文本的医疗命名实体一致 的医疗命名实体的数量,Ai表示第i个医疗文本中医疗命名实体的数量,B表示所述扩展后 的待搜索文本中医疗命名实体的数量; 从第i个医疗文本中查找词语与所述扩展后的待搜索文本的词语一致的目标文 本,计算所述目标文本与所述扩展后的待搜索文本的逆序数Gi,根据逆序数Gi和所述扩展后 的待搜索文本计算第i个医疗文本的词序相似度si: 其中,F表示所述扩展后的待搜索文本中词语的数量; 根据第i个医疗文本的位置权重、长度匹配度和词序相似度计算第i个医疗文本的 匹配得分Pi: Pi=Wi(wi,1li wi,2si) 其中,wi,1和wi,2为预设权重。 本申请的第二方面提供一种医疗文本搜索装置,所述装置包括: 获取模块,用于获取多个医疗文本,每个医疗文本包括发布时间、来源、类型、标 题、摘要和正文内容,每个医疗文本有对应的链接地址; 第一识别模块,用于对所述多个医疗文本中的每个医疗文本的标题、摘要、正文内 容进行医疗命名实体识别,得到每个医疗文本的多个医疗命名实体,每个医疗命名实体有 对应的位置序号; 接收模块,用于接收请求方的搜索请求,所述搜索请求包括待搜索文本、对所述待 搜索文本的限制时间、所述待搜索文本的类型和所述待搜索文本的目标来源; 扩展模块,用于对所述待搜索文本进行扩展,得到扩展后的待搜索文本; 第二识别模块,用于对所述扩展后的待搜索文本进行医疗命名实体识别,得到所 述扩展后的待搜索文本的多个医疗命名实体; 7 CN 111581337 A 说 明 书 4/15 页 搜索模块,用于在所述多个医疗文本中搜索医疗命名实体与所述扩展后的待搜索 文本的医疗命名实体匹配、来源及类型与所述待搜索文本匹配并且发布时间晚于所述待搜 索文本的限制时间的多个候选医疗文本; 计算模块,用于根据所述多个候选医疗文本的医疗命名实体的位置序号和所述扩 展后的待搜索文本的多个医疗命名实体计算所述多个候选医疗文本的匹配得分; 返回模块,用于将匹配得分最高的预设数量的候选医疗文本返回所述请求方。 另一种可能的实现方式中,所述对所述多个医疗文本中的每个医疗文本的标题、 摘要、正文内容进行医疗命名实体识别包括: 对每个医疗文本的标题、摘要、正文内容进行分句、去重、错误修正预处理,得到预 处理后的文本内容; 将所述预处理后的文本内容中的每个语句转化为向量序列; 将每个语句对应的向量序列输入训练好的第一双向长短时记忆网络,得到该语句 的特征向量序列,将该语句的特征向量序列输入训练好的第一条件随机场,得到该语句的 标记序列; 根据所述预处理后的文本内容中的每个语句的标记序列识别医疗命名实体。 另一种可能的实现方式中,所述医疗文本搜索装置还包括训练模块,用于在所述 对所述多个医疗文本中的每个医疗文本的标题、摘要、正文内容进行医疗命名实体识别之 前,获取医疗训练语句和所述医疗训练语句的标签向量序列;将所述医疗训练语句转化为 向量序列;将所述医疗训练语句的向量序列输入所述第一双向长短时记忆网络,得到所述 医疗训练语句的特征向量序列,将所述医疗训练语句的特征向量序列输入所述第一条件随 机场,得到所述医疗训练语句的标记序列;根据所述医疗训练语句的标签向量序列和标记 序列通过梯度下降法调整所述第一双向长短时记忆网络和所述第一条件随机场的隐藏层 的权重和偏置值。 另一种可能的实现方式中,所述对所述待搜索文本进行扩展包括: 对所述待搜索文本进行分词处理,得到多个目标词语; 确定所述多个词语中每个目标词语的近义词集合; 在所述待搜索文本中用每个目标词语的近义词集合中的词语替换该目标词语,将 每次替换后的所述待搜索文本确定为一个扩展后的待搜索文本。 另一种可能的实现方式中,所述确定所述多个词语中每个目标词语的近义词集合 包括: 从预设近义词词典中查询该目标词语的近义词;和/或 获取历史搜索信息,从所述历史搜索信息中标记的医疗文本中确定该目标词语的 近义词;和/或 从所述待搜索文本中删除该目标词语,得到该目标词语的匹配模板,从所述多个 医疗文本中查找所述匹配模板,将查找到的所述匹配模板所在的语句中与该目标词语对应 的词语确定为该目标词语的近义词,其中,该目标词语在所述匹配模板中的位置与该目标 词语对应的词语在查找到的所述匹配模板中的位置一致。 另一种可能的实现方式中,所述对所述扩展后的待搜索文本进行医疗命名实体识 别包括: 8 CN 111581337 A 说 明 书 5/15 页 对所述扩展后的待搜索文本进行预处理,得到预处理后的扩展后的待搜索文本; 将所述预处理后的扩展后的待搜索文本中的每个语句转化为向量序列; 将每个语句对应的向量序列输入训练好的第二双向长短时记忆网络,得到该语句 的特征向量序列,将该语句的特征向量序列输入训练好的第二条件随机场,得到该语句的 标记序列; 根据所述预处理后的文本内容中的每个语句的标记序列识别医疗命名实体。 另一种可能的实现方式中,所述根据所述多个候选医疗文本的医疗命名实体的位 置序号和所述扩展后的待搜索文本的多个医疗命名实体计算所述多个候选医疗文本的匹 配得分包括: 对于所述多个候选医疗文本中的第i个医疗文本,1≤i≤n,n为所述多个候选医疗 文本的数量,根据第i个医疗文本中与所述扩展后的待搜索文本的多个医疗命名实体一致 的医疗命名实体的位置序号确定第i个医疗文本的位置权重Wi: 其中,mi为第i个医疗文本中与所述扩展后的待搜索文本的多个医疗命名实体一 致的医疗命名实体的数量,Oi ,j表示第i个医疗文本中第j个医疗命名实体的位置序号,Ei ,1 表示位于第i个医疗文本的标题的位置序号的集合,Ei ,2表示位于第i个医疗文本的摘要的 位置序号的集合,Ei ,3表示位于第i个医疗文本的正文内容的头尾语句的位置序号的集合, Ei ,4表示位于第i个医疗文本的正文内容的非头尾语句的位置序号的集合,d1、d2、d3和d4为 预设值; 根据第i个医疗文本的医疗命名实体和所述扩展后的待搜索文本的医疗命名实体 计算第i个医疗文本的长度匹配度li: 其中,Ci表示第i个医疗文本中与所述扩展后的待搜索文本的医疗命名实体一致 的医疗命名实体的数量,Ai表示第i个医疗文本中医疗命名实体的数量,B表示所述扩展后 的待搜索文本中医疗命名实体的数量; 从第i个医疗文本中查找词语与所述扩展后的待搜索文本的词语一致的目标文 本,计算所述目标文本与所述扩展后的待搜索文本的逆序数Gi,根据逆序数Gi和所述扩展后 的待搜索文本计算第i个医疗文本的词序相似度si: 其中,F表示所述扩展后的待搜索文本中词语的数量; 根据第i个医疗文本的位置权重、长度匹配度和词序相似度计算第i个医疗文本的 匹配得分Pi: Pi=Wi(wi,1li wi,2si) 9 CN 111581337 A 说 明 书 6/15 页 其中,wi,1和wi,2为预设权重。 本申请的第三方面提供一种计算机设备,所述计算机设备包括处理器,所述处理 器用于执行存储器中存储的计算机程序时实现所述医疗文本搜索方法。 本申请的第四方面提供一种计算机存储介质,其上存储有计算机程序,所述计算 机程序被处理器执行时实现所述医疗文本搜索方法。 本发明实现了根据用户的输入从医疗文本集中搜索匹配医疗文本,提升了医疗文 本搜索的准确度。 附图说明 图1是本发明实施例提供的医疗文本搜索方法的流程图。 图2是本发明实施例提供的医疗文本搜索装置的结构图。 图3是本发明实施例提供的计算机设备的示意图。











