
技术摘要:
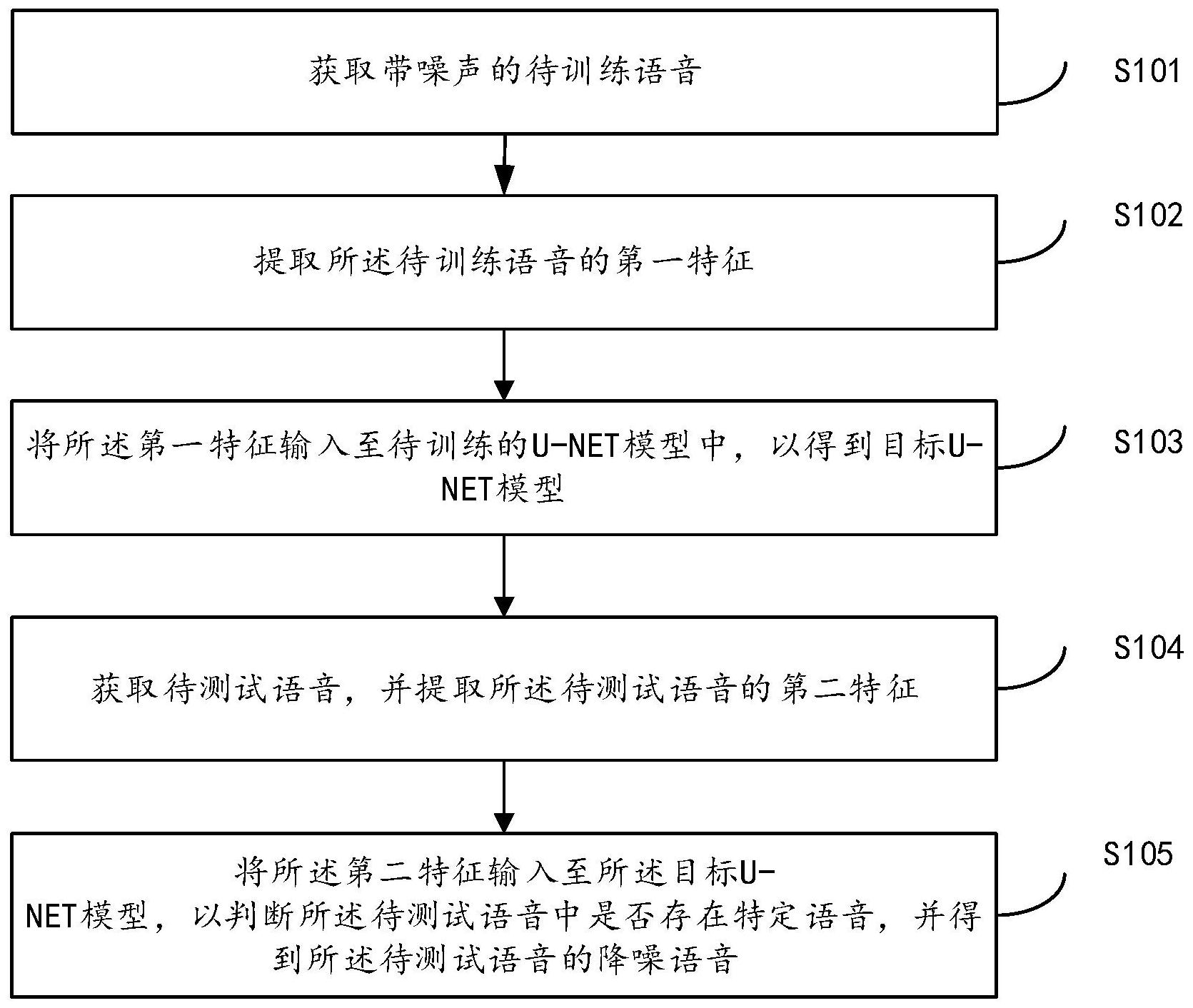
本发明是关于特定词语音的处理方法及装置。该方法包括:获取带噪声的待训练语音;提取所述待训练语音的第一特征;将所述第一特征输入至待训练的U‑NET模型中,以得到目标U‑NET模型;获取待测试语音,并提取所述待测试语音的第二特征;将所述第二特征输入至所述目标U‑ 全部
背景技术:
目前,市面上出现了大量的用于智能家居、移动自动设备和基于语音交互的装置, 比如一些智能音箱,Amazon Alexa,Apple Siri等,而这些装置在语音交互前都需要一个特 定词检测系统进行唤醒,但是这个特定词检测系统一般只能在相对安静的场景中才有较好 的检测效果,噪声场景下的性能不好,即现有技术的特定词检测方法只对在相对安静的环 境中录制的语音才有较好的检测效果,在噪声场景下性能会呈现悬崖式下,从而使得带噪 语音中关键词检测不准确。
技术实现要素:
本发明实施例提供了特定词语音的处理方法及装置。所述技术方案如下: 根据本发明实施例的第一方面,提供一种特定词语音的处理方法,包括: 获取带噪声的待训练语音; 提取所述待训练语音的第一特征; 将所述第一特征输入至待训练的U-NET模型中,以得到目标U-NET模型; 获取待测试语音,并提取所述待测试语音的第二特征; 将所述第二特征输入至所述目标U-NET模型,以判断所述待测试语音中是否存在 特定词语音,并得到所述待测试语音的降噪语音。 在一个实施例中,所述将所述第一特征输入至待训练的U-NET模型中,以得到目标 U-NET模型,包括: 将所述第一特征输入至所述待训练的U-NET模型中,以得到所述待训练语音对应 的第一估计掩蔽值以及所述待训练语音中是否包括预设语音的估计结果;所述第一特征为 所述待训练语音在频域空间的幅值; 根据所述第一估计掩蔽值和所述估计结果,对所述待训练的U-NET模型进行训练, 以得到所述目标U-NET模型。 在一个实施例中,所述根据所述第一估计掩蔽值和所述估计结果,对所述待训练 的U-NET模型进行训练,以得到所述目标U-NET模型,包括: 获取所述待训练语音对应的真实掩蔽值和所述待训练语音中是否包括预设语音 的真实判断结果; 根据所述第一估计掩蔽值、所述估计结果、所述真实掩蔽值和所述真实判断结果, 计算模型损失函数; 根据所述模型损失函数,对所述待训练的U-NET模型进行调整,以得到所述目标U- NET模型。 在一个实施例中,根据所述第一估计掩蔽值、所述估计结果、所述真实掩蔽值和所 5 CN 111613211 A 说 明 书 2/8 页 述真实判断结果,计算模型损失函数,包括: 通过以下第一预设公式计算所述模型损失函数Loss: 其中, 和 分别是所述第一估计掩蔽值、所述估计结果, PSM、LABEL分别是所述真实掩蔽值、所述真实判断结果、MAE表示平均绝对误差; 真实掩蔽值PSM是通过第二预设公式计算获得的,所述第二预设公式为: |pure|表示所述待训练语音对应的纯净语音在频域空间的幅值,|mixture|表示 所述待训练语音在频域空间的幅值,θpure表示所述待训练语音对应的纯净语音在频域空间 的相位,θmixture表示所述待训练语音在频域空间的相位。 在一个实施例中,所述将所述第二特征输入至所述目标U-NET模型,以判断所述待 测试语音中是否存在特定词语音,并得到所述待测试语音的降噪语音,包括: 将所述第二特征输入至所述目标U-NET模型中,以判断所述待测试语音中是否存 在特定词语音以及所述待测试语音对应的第二估计掩蔽值;所述第二特征为所述待测试语 音在频域空间的幅值; 将所述待测试语音通过短时傅里叶变换,以得到所述待测试语音的频谱; 将所述第二估计掩蔽值和所述频谱相乘后进行逆傅里叶变换,以得到所述降噪语 音。 根据本发明实施例的第二方面,提供一种特定词语音的处理装置,包括: 获取模块,用于获取带噪声的待训练语音; 提取模块,用于提取所述待训练语音的第一特征; 输入模块,用于将所述第一特征输入至待训练的U-NET模型中,以得到目标U-NET 模型; 第一处理模块,用于获取待测试语音,并提取所述待测试语音的第二特征; 第二处理模块,用于将所述第二特征输入至所述目标U-NET模型,以判断所述待测 试语音中是否存在特定词语音,并得到所述待测试语音的降噪语音。 在一个实施例中,所述输入模块包括: 输入子模块,用于将所述第一特征输入至所述待训练的U-NET模型中,以得到所述 待训练语音对应的第一估计掩蔽值以及所述待训练语音中是否包括预设语音的估计结果; 所述第一特征为所述待训练语音在频域空间的幅值; 训练子模块,用于根据所述第一估计掩蔽值和所述估计结果,对所述待训练的U- NET模型进行训练,以得到所述目标U-NET模型。 在一个实施例中,所述训练子模块具体用于: 获取所述待训练语音对应的真实掩蔽值和所述待训练语音中是否包括预设语音 的真实判断结果; 根据所述第一估计掩蔽值、所述估计结果、所述真实掩蔽值和所述真实判断结果, 计算模型损失函数; 6 CN 111613211 A 说 明 书 3/8 页 根据所述模型损失函数,对所述待训练的U-NET模型进行调整,以得到所述目标U- NET模型。 在一个实施例中,所述训练子模块具体还用于: 通过以下第一预设公式计算所述模型损失函数Loss: 其中, 和 分别是所述第一估计掩蔽值、所述估计结果, PSM、LABEL分别是所述真实掩蔽值、所述真实判断结果、MAE表示平均绝对误差; 真实掩蔽值PSM是通过第二预设公式计算获得的,所述第二预设公式为: |pure|表示所述待训练语音对应的纯净语音在频域空间的幅值,|mixture|表示 所述待训练语音在频域空间的幅值,θpure表示所述待训练语音对应的纯净语音在频域空间 的相位,θmixture表示所述待训练语音在频域空间的相位。 在一个实施例中,所述第二处理模块包括: 输入子模块,用于将所述第二特征输入至所述目标U-NET模型中,以判断所述待测 试语音中是否存在特定词语音以及所述待测试语音对应的第二估计掩蔽值;所述第二特征 为所述待测试语音在频域空间的幅值; 变换子模块,用于将所述待测试语音通过短时傅里叶变换,以得到所述待测试语 音的频谱; 处理子模块,用于将所述第二估计掩蔽值和所述频谱相乘后进行逆傅里叶变换, 以得到所述降噪语音。 本发明的实施例提供的技术方案可以包括以下有益效果: 通过将待训练语音的第一特征输入至待训练的U-NET模型中,可得到训练后的成 熟度和准确度较高的目标U-NET模型,然后在获取待测试语音后,可提取待测试语音的第二 特征,并将第二特征输入至准确度较高的目标U-NET模型,以得到所述待测试语音的降噪语 音即待测试语音中除去噪音之外的纯净语音,并判断所述待测试语音中是否存在特定词语 音,以充分有效地提高降噪质量以及带噪语音中关键词的检测效率。 应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不 能限制本发明。 附图说明 此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本发明的实施 例,并与说明书一起用于解释本发明的原理。 图1A是根据一示例性实施例示出的一种特定词语音的处理方法的流程图。 图1B是根据一示例性实施例示出的一种特定词语音的处理方法的流程图。 图2是根据一示例性实施例示出的一种特定词语音的处理装置的框图。 7 CN 111613211 A 说 明 书 4/8 页











