
技术摘要:
一种方法,其中多个进程被配置成持有去往其他进程的数据块,且数据重新打包电路包括:接收电路,其被配置用于从多个进程中的源进程接收至少一个数据块;重新打包电路,其被配置用于根据多个进程中的至少一个目的进程重新打包接收到的数据;以及发送电路,其被配置用于 全部
背景技术:
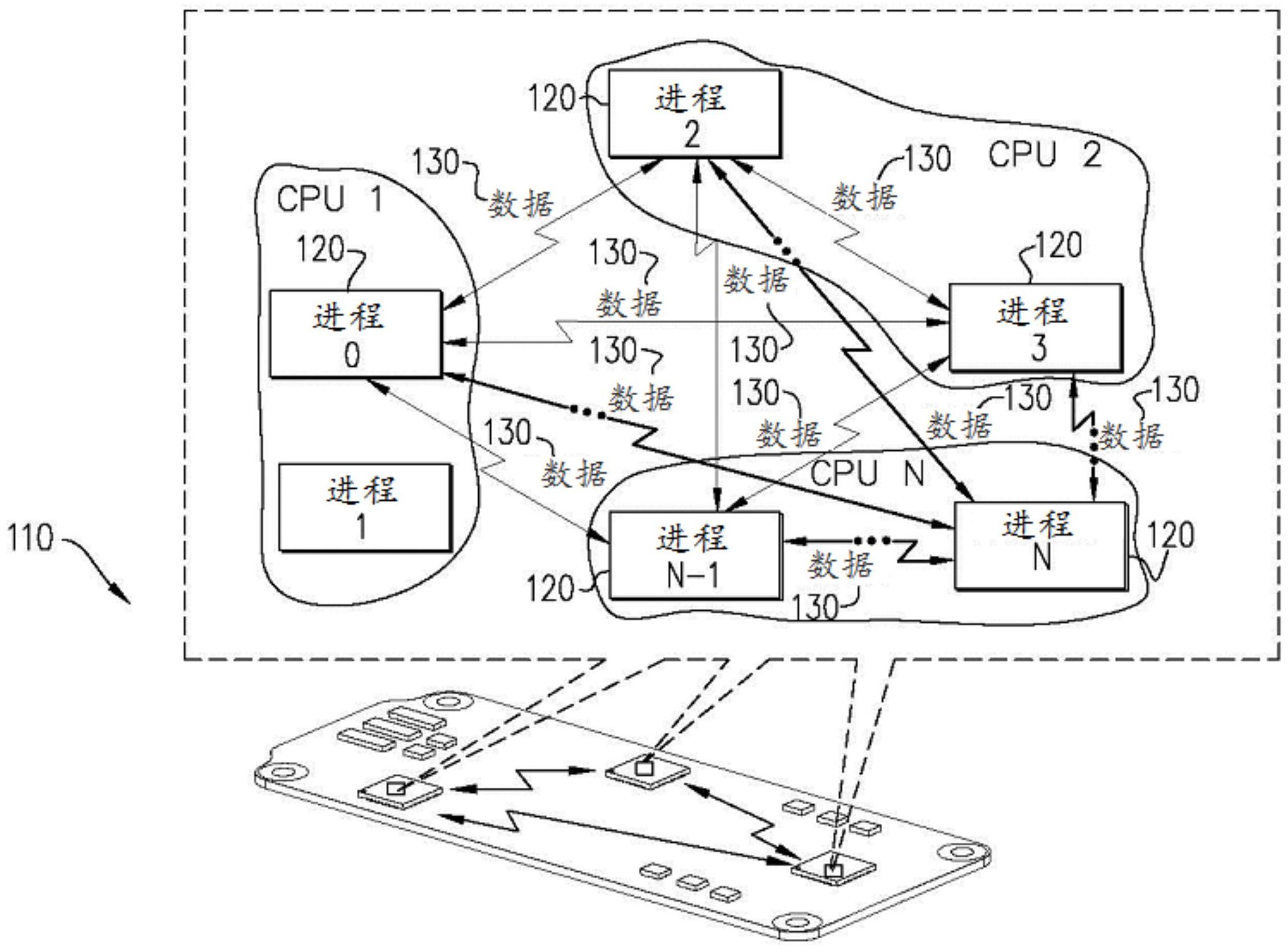
本发明在其特定实施方式中,旨在提供改进的系统和方法用于集体通信,尤其涉 及但不仅限于消息传递操作,包括全对全(all-to-all)操作。 因此,根据本发明的示例性实施方式,提供了一种方法包括提供多个进程,所述多 个进程中的每个进程被配置成持有去往所述多个进程中的其他进程的数据块;提供至少一 个数据重新打包电路实例,其包括被配置用于从所述多个进程中的至少一个源进程接收至 少一个数据块的接收电路,被配置用于根据所述多个进程中的至少一个目的进程重新打包 接收到的数据的重新打包电路,以及被配置用于将重新打包的数据发送到所述多个进程中 的所述至少一个目的进程的发送电路;接收用于全对全数据交换的数据组,该数据组被配 置为矩阵,该矩阵被分布在所述多个进程中;以及通过以下方式转置数据:所述多个进程中 的每个进程将矩阵数据从所述进程发送到所述重新打包电路,以及所述重新打包电路进行 接收、重新打包并将所产生的矩阵数据发送到目的进程。 此外,根据本发明的示例性实施方式,所述方法还包括提供控制树,所述控制树被 配置用于控制所述多个进程和所述重新打包电路。 更进一步地,根据本发明的示例性实施方式,所述控制树还被配置用于从所述多 个进程中的每个进程接收注册消息,当已经从所述多个进程的给定子组的所有成员接收到 注册消息时将所述给定子组标记为准备好操作,当作为源子组的给定子组和作为目的子组 的对应子组准备好操作时将给定的源子组和给定的目的子组配对并将所述给定的源子组 和所述给定的目的子组分配给重新打包电路实例,以及在关于每个所述源子组和每个所述 目的子组的操作完成时通知每个所述源子组和每个所述目的子组。 此外,根据本发明的示例性实施方式,所述控制树被配置用于,除了将所述给定的 源子组和所述给定的目的子组配对之外,将所述给定的源子组和所述给定的目的子组分配 给数据重新打包电路实例。 此外,根据本发明的示例性实施方式,所述方法还包括除了所述控制树之外的分 配电路,所述分配电路被配置用于将所述给定的源子组和所述给定的目的子组分配给数据 重新打包电路实例。 此外,根据本发明的示例性实施方式,所述控制树包括约简树。 根据本发明的另一示例性实施方式,还提供了一种设备,包括:接收电路,其被配 置用于从多个进程中的至少一个源进程接收至少一个数据块,所述多个进程中的每个进程 4 CN 111614581 A 说 明 书 2/9 页 被配置成持有去往所述多个进程中的其他进程的数据块;至少一个数据重新打包电路实 例,其被配置用于根据所述多个进程中的至少一个目的进程重新打包接收到的数据;以及 发送电路,其被配置用于将所述重新打包的数据发送到所述多个进程中的所述至少一个目 的进程,所述设备被配置用于接收用于全对全数据交换的数据组,所述数据组被配置为矩 阵,所述矩阵被分布在所述多个进程中,并且所述设备还被配置用于通过以下方式转置所 述数据:在所述重新打包电路处从所述多个进程中的每个进程接收来自所述进程的矩阵数 据,以及所述数据重新打包电路进行接收、重新打包并将所产生的矩阵数据发送到目的进 程。 此外,根据本发明的示例性实施方式,所述设备还包括控制树,所述控制树被配置 用于控制所述多个进程和所述重新打包电路。 更进一步地,根据本发明的示例性实施方式,所述控制树还被配置用于从所述多 个进程中的每个进程接收注册消息,当已经从所述多个进程的给定子组的所有成员接收到 注册消息时将所述给定子组标记为准备好操作,当作为源子组的给定子组和作为目的子组 的对应子组准备好操作时将给定的源子组和给定的目的子组配对并将所述给定的源子组 和所述给定的目的子组分配给数据重新打包电路实例,以及在关于每个源子组和每个目的 子组的操作完成时通知每个所述源子组和每个所述目的子组。 此外,根据本发明的示例性实施方式,所述控制树被配置用于,除了将所述给定的 源子组和所述给定的目的子组配对之外,将所述给定的源子组和所述给定的目的子组分配 到给定的数据重新打包电路实例。 此外,根据本发明的示例性实施方式,所述设备还包括除了所述控制树之外的分 配电路,所述分配电路被配置用于将所述给定的源子组和所述给定的目的子组分配到给定 的数据重新打包电路实例。 此外,根据本发明的示例性实施方式,所述控制树包括约简树。 附图说明 通过以下详细描述并结合附图,将会更充分地理解和领会本发明,其中: 图1A是根据本发明的示例性实施方式构建和操作的示例性计算机系统的简化图 示; 图1B是示例性数据块布局的简化图示; 图2是另一示例性数据块布局的简化图示; 图3是描绘全对全v初始阶段和最终阶段的简化图示; 图4是描绘直接成对交换的简化图示; 图5是描述聚合算法的简化图示; 图6是描绘根据本发明的示例性实施方式的全对全操作的初始块分布的简化图 示; 图7是描绘根据本发明的示例性实施方式的全对全操作的最终块分布的简化图 示; 图8是描绘根据本发明的另一示例性实施方式的全对全子矩阵分布的简化图示; 以及 5 CN 111614581 A 说 明 书 3/9 页 图9是描绘根据本发明的示例性实施方式的子块转置的简化图示。
技术实现要素:
在通信标准诸如消息传递接口(Message Passing Interface,MPI)(论坛,2015) 中定义的全对全(all-to-all)操作是集体数据操作,其中每个进程向集体组中的每个其他 进程发送数据,并从组中的每个进程接收相同量的数据。发送到每个进程的数据具有相同 的长度a,并且是惟一的,源自不同的存储器位置。在诸如MPI之类通信标准中,进程操作的 概念与任何特定的硬件基础架构解耦。本文讨论的集体组是指定义(集体)操作的一组进 程。在MPI规范中,集体组被称为“通信子(communicator)”,而在OpenSHMEM中(例如,参见 www.openshmem.org/site/),集体组被称为“团队(team)”。 现参考图1A,其为根据本发明的示例性实施方式构建和操作的示例性计算机系统 的简化图示。图1A的系统,总体上标示为110,包括多个进程120,其中数据(通常为数据块) 130在其间流动。本文使用的术语“数据块”(在各种语法形式下)是指数据,所述数据在集体 组内从成员(进程、等级、……)i发送到成员j。应当理解,正如本文其他各处所解释的,对于 全对全,所有块的大小是相同的(并且可以是0),而对于全对全v/w,假设数据块的大小是不 一致的,并且一些/所有块可能是0。 下文描述了图1A的系统的示例性操作方法。在图1A中,通过非限制示例的方式示 出了在片上系统中互连的多个CPU(包括CPU 1、CPU 2和CPU N)正在运行多个进程120。其他 系统示例,举非限制示例而言,包括:单个CPU;由网络连接起来的多个系统或服务器;或者 任何其他合适的系统。如上所述,本文所述的进程操作的概念与任何特定的硬件基础架构 解耦,尽管应当理解,在任何实际的实现中,将会使用一些硬件基础架构(如图1A中所示或 如上文所述)。 现参考图1B,其为包括多个数据块180的示例性数据块布局175的简化图示;并且 参考图2,其为包括多个数据块220的另一示例性数据块布局210的简化图示。图1B示出了施 加全对全操作之前的示例性数据块布局175,而图2示出了施加全对全操作之后对应的数据 块布局210。图1B中的每个数据块180和图2中的每个数据块220对应于长度为a的矢量。 用于实现全对全算法的算法一般分为两类——直接交换算法和聚合算法。 全对全聚合算法旨在降低延迟成本,该延迟成本在短数据传输中占主导地位。全 对全聚合算法采用数据转发方法,以便减少发送的消息的数目,从而降低延迟成本。这样的 方法从/向多个源收集/分散数据,从而产生更少的较大数据传输,但是将给定的数据段发 送多次。当参与集体操作的通信上下文的数目变得过多时,聚合技术变得比直接数据交换 更低效;这是由于将给定的数据段多次传输的成本越来越高。全对全算法利用了数据长度a 是算法常数这一事实,从而提供了足够的全局知识来协调中间过程中的数据交换。 直接交换算法通常用于全对全实例,其中传输的数据长度a超过带宽贡献占主导 的阈值,或者当聚合技术聚合了来自过多进程的数据时,会导致聚合技术效率低下。 随着系统大小的增长,对于支持小型数据全对全交换的高效实现的需求也在增 加,因为这是许多高性能计算(high-performance computing,HPC)应用所使用的数据交换 模式。本发明在其示例性实施方式中,提出了一种新的全对全算法,其被设计用于在通信子 大小的全范围内提高小型数据交换的效率。这包括一种新的基于聚合的算法,其适用于小 6 CN 111614581 A 说 明 书 4/9 页 型数据个体化全对全数据交换,并且可以被视为分布式矩阵的转置。虽然在本说明书和权 利要求书中以各种语法形式使用了转置,但应当理解,转置包括根据本发明的示例性实施 方式将算法概念化的方式;例如,在不限制上述声明的一般性的情况下,在(例如)MPI标准 的层面上可能不存在这样的概念化。在示例性实施方式中,这样的转置包括改变块相对于 其他块的位置,而不改变任何块内的结构。参考本发明的示例性实施方式,本文描述的算法 受益于网络中可用的大量并发性,并且被设计为对于通过网络硬件的实现简单高效。在示 例性实施方式中,交换硬件和主机通道适配器的实现都是这种新设计的目标。 个体化全对全v/w(all-to-all-v/w)算法在某些方面与个体化全对全数据交换相 似。个体化全对全w算法与全对全v算法的不同之处在于,每个单独传输的数据类型在整个 函数中可能是唯一的。对全对全算法做出改变以支持这种集体操作。更具体地关于数据类 型:使用MPI标准接口传输的数据为所有数据指定了数据类型,诸如MPI_DOUBLE用于双精度 字。全对全v接口指定所有数据元素具有相同的数据类型。全对全w允许为每个数据块指定 不同的数据类型,举例而言,诸如为从进程i到进程j的数据指定数据类型。 将全对全v/w操作用于每个进程以与参与此集体操作的进程组中的每个其他进程 交换独特数据。两个给定进程之间交换的数据的大小可能是不对称的,并且每一对进程可 能具有与其他对不同的数据模式,且交换的数据大小可能有很大差异。给定的等级只需要 具有其所参与的数据交换的本地API级信息。 针对硬件实现的个体化全对全v/w算法有些类似于个体化全对全算法,但需要更 多描述用以实现的详细数据长度的元数据。此外,该算法只处理低于预先指定阈值的消息。 针对较大的消息,使用直接数据交换。 先前,用于全对全函数实现的算法分为两大类: -直接数据交换 -聚合算法 基本算法定义描述了集体组或者MPI定义中的MPI通信子中所有进程对之间的数 据交换。术语“基本算法”是指接口级的算法定义——从逻辑上讲函数是什么/做什么,而不 是如何实现函数结果。因此,举特定的非限制性示例而言,全对全v的基本描述是每个进程 向组中的所有进程发送数据块。在本发明的某些示例性实施方式中,举特定的非限制性示 例而言,描述了通过聚合数据并使用本文描述的通信模式来实现特定函数的方法。总体而 言,算法定义在概念上需要O(N2)次数据交换,其中N为组大小。 现参考图3,其为描绘全对全v初始阶段和最终阶段的简化图示。 图3提供了个体化全对全v的示例,示出了初始(参考标号310)阶段和最终(参考标 号320)阶段。在图3中,符号(i,j)表示从位置j的等级i开始并且应当传送到位置i的等级j 的数据段。所有段的数据大小可能不同(甚至可能是零长度)。发送位置和接收位置的偏移 也可能不同。 所述函数的直接数据交换实现是全对全函数的最简单实现。简单的实现将许多消 息放在网络上,并潜在地通过引起拥塞和端点n→1争用而严重降低网络利用率。(本文使用 的术语“端点”表示向集体操作贡献数据的实体,诸如进程或线程)。因此,实现直接数据交 换的算法使用如图4中所示的诸如成对交换等通信模式,(Jelena Pjevsivac-Grbovic , 2007),以减少网络负载和端点争用。对于带宽有限的大型消息交换,直接数据交换算法往 7 CN 111614581 A 说 明 书 5/9 页 往会充分利用网络资源。然而,当数据交换规模小时,延迟和消息速率成本将主导整个算法 成本,并随N线性扩大,并且不能很好地利用系统资源。具体而言,图4描绘了涉及进程0的交 换的直接成对交换模式的非限制性示例。每个交换的长度为a,具有双向数据交换。 聚合算法(Ana Gainaru ,2016)被用于实现小型数据聚合,且Bruck(J .Bruck , 1997)算法可能是该类中最著名的算法。其中使用此方法涉及每个进程的数据交换的数目 为O((k-1)*logk(N)),其中N为集体组大小,而k为算法基数。图5示出了一种可能的聚合模 式的通信模式。具体而言,图5描绘了聚合算法发送任意基数k的侧数据模式的非限制性示 例,假设N是算法基数k的整数次幂。N是集体组的大小。聚合算法提供了比直接交换更好的 可扩展性特性。消息数目的减少降低了全对全操作的延迟和消息速率成本,但增加了与带 宽相关的成本。如果组规模不太大,则所述聚合算法胜过直接交换算法。聚合算法中每个数 据交换的消息大小规模为O(a*N/k),其中a为全对全函数消息大小。因此,当组变大时,聚合 算法在降低全对全数据交换的延迟方面是无效的,并将导致超过直接数据交换算法的延 迟。 在本发明的示例性实施方式中,全对全和全对全v/w算法旨在通过以下方式优化 小型数据交换: 1 .在网络中定义多个聚合点,交换机或者主机通道适配器(host channel adapter,HCA)。 2.针对从进程的子块去往进程的相同子块或其他子块的数据,向网络基础架构中 的各个聚合器分配聚合点。这些数据可以被视为分布式矩阵的子矩阵。单个聚合器可以处 理来自单个个体化全对全或全对全v/w算法的子矩阵的多个块。 3.子块可以由不连续的进程组组成,这些进程组在某些示例性实施方式中即时形 成,以处理调用应用中的负载不平衡。在这样的情况下,矩阵子块可能是不连续的。 4.本文使用的术语“聚合器”是指这样的实体:其对子矩阵进行聚合,对其进行转 置,并且继而将结果发送到其最终目的地。在本发明的某些示例性实施方式中,聚合器是 HCA内的逻辑块。继而,本步骤4可以包括使聚合器: a.从所有源收集数据 b.混洗数据以准备使得去往特定进程的数据可以当作单个消息发送到此目的地。 在当前上下文中,术语“混洗”指的是对来自不同源进程的传入数据重新排序,使得去往给 定目的地的数据能够被方便地处理。在本发明的某些示例性实施方式中,发往单个目的地 的数据可以被复制到一个连续的存储器块。 c.将数据发送到目的地 5.在某些优选实施方式中,数据不连续性以及数据源和/或目的地在网络边缘处 理,使得聚合器仅处理连续的打包数据。换言之,从用户发送或由用户接收的数据不需要在 用户的虚拟存储器空间中是连续的;这种情况可以被看作是立方体的面,其中6个面中的2 个面不会在连续的存储器地址中。硬件发送连续数据流。处理从非连续的变为连续的“打包 (packing)”是在第一步完成的(通过使用CPU将数据打包到连续的缓冲区,或者通过使用 HCA收集能力)。类似地,将非连续数据拆包到用户缓冲区可以通过HCA将数据传递到连续目 的缓冲区并继而使用CPU拆包,或者通过使用HCA分散能力来完成。因此,中间步骤中的算法 数据操纵可以处理连续的打包数据。 8 CN 111614581 A 说 明 书 6/9 页 本发明在其示例性实施方式中,可以被视为使用网络内的聚合点从分布式矩阵的 非连续部分收集数据,转置数据,并将数据发送到其目的地。 在示例性实施方式中,本发明可被概括如下: 1 .数据布局被视为分布式矩阵,其中每个进程持有去往每个其他进程的数据块。 对于全对全算法,所有源数据块的数据块大小是相同的;而对于全对全v/w,数据块大小可 以是不同的长度,包括长度0。在本文使用的符号中,水平索引表示数据源,垂直索引表示其 目的地。 2.集体操作执行数据块的转置。 3.为了对分布式矩阵进行转置,将矩阵细分为dh×dv维度的矩形子矩阵,其中dh是 在水平维度的大小,而dv是在垂直维度的大小。子块不需要在逻辑上连续。子矩阵可以被预 定义,或者可以在运行时基于一些准则来确定,举非限制示例而言,诸如按进入全对全操作 的顺序。 4.提供数据重新打包单元,其接受来自指定源集的数据,所述数据去往指定的目 的地集,按目的地重新打包数据,并将数据发送到指定的目的地。在示例性实施方式中,所 述数据重新打包单元具有用于所描述的每个操作的子单元。在本发明的某些示例性实施方 式中,如本文所述的聚合器将会包括或利用数据重新打包单元。 5.将子矩阵的转置分配到给定的数据重新打包单元,其中每个单元被分配多个子 矩阵进行转置。在本发明的某些示例性实施方式中,所述分配可以由在下面第7点中提到的 控制树来完成;备选地,可以提供另一组件(举非限制性示例而言,诸如软件组件)来完成分 配。 6.数据重新打包单元可以在系统内适当地实现。例如,其可以在交换机ASIC、主机 通道适配器(HCA)单元、CPU或其他合适的硬件中实现,并且能够以硬件、固件、软件或其任 何适当的组合来实现。 7.使用约简树作为控制树以对集体操作进行控制,方法如下: 7.1.组中的每个进程通过向控制树传递到达通知,来向控制树注册自己。 7 .2 .一旦子组的所有成员到达,该子组就被标记为准备好操作(准备好发送/接 收)。 7 .3 .当给定子矩阵的源和目的组就绪时,相关的数据重新打包单元调度数据移 动。 7.4.数据从源进程传输到数据重新打包单元。该单元对数据进行重新打包并将其 发送到适当的目的地。 7.5.每个源进程都会得到完成通知,每个目的进程也是。在本发明的某些示例性 实施方式中,这是通过聚合器通知源块和目的块完成来实现的;举特定的非限制性示例而 言,这可以使用控制树来实现。 7.6.一旦接收到所有预期的数据并完成所有源数据的传输,操作就在每个进程本 地完成。 在示例性实施方式中,更详细的说明如下: 在全对全算法和全对全v/w算法中,每个进程具有去往组中每个其他进程的唯一 数据块。全对全与全对全v的主要区别在于数据布局模式。全对全的数据块大小都相同,而 9 CN 111614581 A 说 明 书 7/9 页 全对全v/w算法支持不同大小的数据块,并且数据块在用户缓冲区中不必以单调递增的顺 序排序。 全对全算法的数据块布局可以被视为分布式矩阵,其中全对全算法对这个块分布 进行转置。需要重点注意的是,在本发明的示例性实施方式中,每个块内的数据在转置中没 有重排,而只是重排了数据块本身的排序。 图6示出了大小为六的组的示例性全对全数据源数据块布局,从而展示了全对全 操作的示例性初始分布。每列表示每个进程持有用于所有其他进程的数据块。每个块都用 两个索引标签标记,其中第一索引指示数据源自的进程,第二索引是该块的目的进程的等 级(术语“等级”,根据MPI标准使用,其中通信子(对集体进行定义的进程组)的每个成员都 被给予等级或ID)。 在全对全操作被施加于图6示例中的数据之后,伴随着数据块被转置,产生图7中 展示的数据块布局。 全对全v/w算法进行了类似的数据转置。这样的变换的不同之处如下: 1.各块之间的数据大小可能不同,并且甚至可能长度为零。 2.源缓冲区和目的缓冲区处的数据块都不必按目的地(源缓冲区)或源(结果缓冲 区)递增顺序排列。实际的块顺序被指定为全对全v/w操作的一部分。 因此,类似的通信模式可以用于实现全对全和全对全v/w。 实际矩阵变换是对数据的子块执行。本文使用术语“实际矩阵转换”是因为当矩阵 中的每个元素都是数据块时,操作所定义的数据传输块可以被视为矩阵转换。矩阵的列是 每个进程拥有的数据块。每个进程具有与组中的每个进程相关联的数据块,因此可以将矩 阵视为方阵。对于全对全,所有块的大小是相同的,对于全对全v和全对全w,块的大小可能 不同。从数据布局的块状视图(不是每个块的实际大小)来看,全对全v和全对全w仍然是正 方形。 为了进行变换,定义了水平子矩阵维数dh和垂直子矩阵维数dv。子块维数不必是整 个矩阵维数的整数因数,并且dh和dv不必相等。允许有不完整的子块;也就是说,对于给定的 组大小,有些子组的组大小与子块大小之比不是整数。这种情况会在边缘处产生“剩余”块。 举特定的非限制性示例而言,这样的“剩余”块会在大小为11的矩阵中出现,并带有大小为3 的子块。最后,整个矩阵中的值的垂直和水平范围不必是连续的,例如,当映射到整个矩阵 时,这样的子矩阵可以分布到矩阵上几个不同的连续数据块中。 例如,如果我们取dh=hv=2,并且我们使用进程组{1,2},{0,3}和{4,5}来对矩阵 进行分块,则图8使用编码[a]到[i]来展示整个矩阵可以如何在一个非限制性示例中被细 分为2×2的子块。注意,示例中有三个分布式子块:1)数据块(0,0)(0,3)(3,0)(3,3),表示 为[a];2)数据块(0,1)(0,2)(3,1)(3,2),表示为[c];以及3)(1,0)(2,0)(1,3)(2,3),表示 为[b]。 在本发明的示例性实施方式中,使用约简树对整个端到端全对全进行统筹。当进 程调用集体操作时,每个进程使用约简树来注册集体操作。当子组的所有成员都注册了操 作时,该子组被标记为有效。当源和目的子组都有效时,该子组可以被转置。 在本发明的某些示例性实施方式中,集体操作以下列方式执行: 1.组中的每个进程通过向控制器传递到达通知,来向控制树注册自己。 10 CN 111614581 A 说 明 书 8/9 页 2.一旦子组的所有成员到达,该子组就被标记为准备好操作。 3.当源组和目的组准备就绪时,将它们配对并分配给数据重新打包单元。 4.数据从源进程传输到数据重新打包单元。该单元对数据进行重新打包并将其发 送到合适的目的地。 5.每个源进程都会得到完成通知,每个目的进程也是。 6.一旦接收到所有预期的数据并完成所有源数据的传输,操作就在每个进程本地 完成。 图9示出了在非限制性的示例实施方式中,如何使用系统中的数据重新打包单元 910之一来转置由水平子组{0,3}和垂直子组{1,2}定义的子矩阵。进程0和进程3各自将其 子矩阵的一部分发送给数据重新打包单元,该单元重新排列数据,并发送给进程1和进程2。 在图9中所示的具体非限制性示例中,进程0具有数据元素(0,1)和(0,2),进程3具有数据元 素(3,1)和(3,2)。该数据被发送到控制器,所述控制器将(0,1)和(3,1)发送到进程1并将 (0,2)和(3,2)发送到进程2。结果缓冲区中的最终数据放置由端点处理。通常,在示例性实 施方式中,重新打包单元910将所有由其处理的数据视为连续的“一团(blob)”数据——重 新打包单元910不识别数据中的任何结构。在每个块内的端点处的最终数据分布可能是连 续的,在这种情况下所述重新打包单元和所述目的进程将会具有相同的数据视图。然而,目 的进程处的最终数据布局可能是不连续的,在这种情况下是端点在目的地适当地分布数 据。应当理解,端点或任何其他合适的系统组件可以适当地分布数据。 参考文献 Ana Gainaru ,R .L .Graham ,Artem Polyakov ,Gilad Shainer(2016) .Using InfiniBand Hardware Gather-Scatter Capabilities to Optimize MPI All-to-All (Vol .Proceedings of the 23rd European MPI Users 'Group Meeting) .Edinburgh , United Kingdom:ACM MPI Forum ,(2015) .Message Passing Interface .Knoxville:University of Tennessee. J.Bruck,Ching-Tien Ho,Shlomo Kipnis,Derrick Weathersby(1997) .E cient algorithms for all-to-all communications in multi-port message-passing systems.In IEEE Transactions on Parallel and Distributed Systems,pages 298– 309. Jelena Pjevsivac-Grbovic ,Thara Angskun ,Geroge Bosilca ,Graham Fagg , Edgar Gabriel ,Jack Dongarra ,(2007) .Performance analysis of MPI collective operations.Cluster Computing. 应当理解,如果需要,本发明的软件组件可以以ROM(只读存储器)的形式实现。如 果需要,软件组件通常可以使用传统技术以硬件实现。还应当理解,软件组件可以被实例 化,例如:作为计算机程序产品或处在有形介质上。在一些情况下,有可能将软件组件实例 化为可由合适的计算机解读的信号,尽管这样的实例化可能在本发明的某些实施方式中被 排除在外。 应当理解,为了清楚起见,在单独的实施方式的上下文中描述的本发明各个特征 也可以组合在单一实施方式中提供。反之,为简洁起见,在单一实施方式的上下文中描述的 11 CN 111614581 A 说 明 书 9/9 页 本发明各个特征也可以分开提供或以任何适当的子组合形式提供。 本领域技术人员应当理解,本发明不受上述的具体表示和描述的限制。相反,发明 的范围由所附的权利要求书及其等同项确定。 12 CN 111614581 A 说 明 书 附 图 1/10 页 图1A 13 CN 111614581 A 说 明 书 附 图 2/10 页 图1B 14 CN 111614581 A 说 明 书 附 图 3/10 页 图2 15 CN 111614581 A 说 明 书 附 图 4/10 页 图3 16 CN 111614581 A 说 明 书 附 图 5/10 页 图4 17 CN 111614581 A 说 明 书 附 图 6/10 页 图5 18 CN 111614581 A 说 明 书 附 图 7/10 页 图6 19 CN 111614581 A 说 明 书 附 图 8/10 页 图7 20 CN 111614581 A 说 明 书 附 图 9/10 页 图8 21 CN 111614581 A 说 明 书 附 图 10/10 页 图9 22











