
技术摘要:
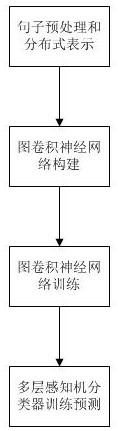
本发明公开了一种基于作文扣题度的自动作文评分计算方法,该方法包括S1:句子预处理和分布式表示;S2:图卷积神经网络构建;S3:图卷积神经网络训练;S4:多层感知机分类器训练预测。本发明应用在自动作文评分领域,实现对非扣题作文的检测和发现,作文参考范文和学生 全部
背景技术:
文本匹配是自然语言理解中的一个核心问题。很多的自然语言处理任务中,比如 问答系统、复述问题、信息检索、机器翻译、对话系统等都可以抽象成文本匹配问题,一般都 会以文本相似度计算,文本相关性计算等形式出现。根据文本长度的不同,语义匹配可以细 分为三类:短文本-短文本语义匹配,短文本-长文本语义匹配和长文本-长文本语义匹配。 文本语义匹配计算方法,目前的方法集中在以下几个方面: (1)向量空间模型 向量空间模型用高维稀疏向量来表示文档,简单明了。对应维度使用TF-IDF计算, 从信息论角度包含了词和文档的点互信息熵,以及文档的信息编码长度。有了文档向量表 示,相似度度量的公式有Jaccard、Cosine、Euclidean distance、BM25等。 (2)矩阵分解方法 通过矩阵分解的方法,把高维稀疏矩阵分解成两个狭长小矩阵,而这两个低维矩 阵包含了语义信息,这个过程即潜在语义分析。潜在语义分析能对文档或者词做低维度语 义表示,在做匹配时其性能较高(比如文档有效词数大于K),它包含语义信息,对于语义相 同的一些文档较准确。 (3)主题模型 PLSA(Probabilistic Latent Semantic Analysis)、LDA(Latent Dirichlet Allocation)等在潜在语义分析之上引入了主题概念,它是一种语义含义,对文档的主题建 模不再是矩阵分解,而是概率分布(比如多项式分布),这样就能解决多义词的分布问题,并 且主题是有明确含义的。这些技术对文本的语义表示形式简洁、运算方便,较好的弥补了传 统词汇匹配方法的不足。 (4)基于深度学习的方法 通过神经语言模型可以建模词分布式表示和句分布式表示,DSSM、CLSM、LSTM- DSSM等模型通过神经网络建模句子表示层和交互矩阵关系层,可以捕获高维文本语义信 息,取得了很好的效果。
技术实现要素:
本发明的目的在于,针对现有技术的不足,提出一种基于作文扣题度的自动作文 评分计算方法,通过一种新颖的方式构建了图神经网络,综合了各个句子的相似度计算文 档相似度,提高了模型准确性和鲁棒性,同时使用Triplet network引入第三个文档建模句 子间相似度。 一种基于作文扣题度的自动作文评分计算方法,包括以下步骤: 4 CN 111581379 A 说 明 书 2/5 页 S1:句子预处理和分布式表示; S2:图卷积神经网络构建; S3:图卷积神经网络训练; S4:多层感知机分类器训练预测; 所述句子预处理和分布式表示,用于对文档句子进行预处理并形成句向量; 所述图卷积神经网络构建,用于构建图神经网络的顶点和边; 所述图卷积神经网络训练,用于通过图卷积神经网络对顶点特征向量进行训练; 所述多层感知机分类器训练预测,用于进行最终文本匹配程度训练和预测。 进一步的,步骤S1具体包括以下子步骤: S11:输入三个文档,分别为文档A,文档B,文档C,其中当文档A和文档B为相似文本 时,文档C为文档A的不相似文本,当文档A和文档B为不相似文本时,文档C为文档A的相似文 本,分别对三个文档进行下面的处理; S12:使用jieba分词对文档中各个句子分词,根据停用词列表去除句子中的停用 词; S13:使用训练好的word2vec模型,对每个句子中的过滤之后的词取出相应的 word2vec词向量,句向量为所有词向量的平均值。 进一步的,步骤S2具体包括以下子步骤: S21:使用K-Means算法根据向量欧氏距离对文档A,文档B,文档C中所有句向量进 行聚类处理得到k个簇,其中k选取等于10; S22:对于文档A聚类结果的十个类中的每个类,分别得到文档B,文档C聚好的十个 类中与文档A每个类最相近的类,计算方法为计算余弦相似度的最大值,最终得到十个句子 类,每一个类中都包含文档A,文档B,文档C中的句子; S23:构建一个图,图的顶点为步骤S22得到的十个类,计算十个类每个类中句子的 向量平均值,计算任意两个类向量的余弦相似度,如果相似度大于0.5,此两个类在图中的 顶点连边,此边的权重值为余弦相似度的值,如果相似度小于0.5,此两个类在图中的顶点 不连边; S24:对于图的顶点,使用Triplet network方式得到顶点的特征向量。 进一步的,步骤S24具体包括以下子步骤: S241:使用一个Triplet network,对于文档A,如果文档B和文档A为相似文本,此 时标记文档B为Positive(x ),标记文档C为Negative(x-),如果文档C和文档A为相似文本, 此时标记文档C为Positive(x ),标记文档B为Negative(x-),由此构成一个(A,Positive, Negative)三元组;(A,Positive,Negative)三元组之间的关系用欧氏距离表示,并通过训 练参数使得x向x 靠近,远离x-。 S242:对于顶点代表的三个文档中的句子,首先得到每个文档中此顶点所有句子 每个词的word2vec词向量,构建一个Context层,Context层使用lstm对词向量进行建模,下 一层使用Triplet loss方式进行网络训练; S243:对于文档A和文档B,训练结束后得到Context层的结果C(A)和C(B),分别计 算|C(A)-C(B)|和C(A)#C(B),#代表哈达玛积,|C(A)-C(B)|的意思为对向量的每一维,计算 |c(A)-c(B)|,C(A)#C(B)的意思为对向量的每一维,计算c(A)*c(B); 5 CN 111581379 A 说 明 书 3/5 页 S244:拼接|C(A)-C(B)|和C(A)#C(B)得到的两个向量为此顶点的特征向量。 进一步的,步骤S3具体包括以下子步骤: S31:图的权重邻接矩阵为A∈RN*N,其中Aij=wij,wij指顶点i和顶点j之间边的权 重,D是对角矩阵,即D =∑ A ,图神经网络的输入层为H(0)ii j ij =X,X指初始的图顶点特征向 量, 代表隐含层第l层的矩阵特征; S32:使用如下公式根据上一层矩阵计算下一层的矩阵: 其中 IN代表单位矩阵, 是对角矩阵,其中 W(l)代表第l层 的可训练矩阵,σ(.)代表激活函数包括sigmoid激活函数和ReLU激活函数; S33:采用三个隐含层,使用由图上局部频谱滤波器的一阶逼近所推动的图卷积规 则,递归地应用来提取顶点之间的交互模式。 进一步的,步骤S4具体包括以下子步骤: S41:经过图神经网络训练后,得到十个图顶点的特征向量,取十个特征向量的平 均值,作为输入层向量输入到多层感知机中; S42:添加三个全连接层,中间的激活函数采用Relu函数; S43:最终的输出层激活函数采用Sigmoid函数,输出标签为文档A和文档B的相似 度标签,当文档A和文档B为相似文本时,标签为0,当文档A和文档B为不相似文本时,标签为 1; S44:训练结束后将中间网络层参数保存; S45:对于待测试文本M和文本N,经过前面所有步骤的处理和所保存网络层参数计 算,得到最终两个文本的语义匹配相似度;其中M对应于训练过程中的文档A,N对应于训练 过程中的文档B。 本发明的有益效果: (1)本发明提出了将作文扣题程度应用在自动作文评分领域,实现对非扣题作文 的检测和发现。作文参考范文和学生作答作文的文本匹配程度是作文评分的一个重要特 征,通过一种新颖的方式构建了图神经网络,综合了各个句子的相似度计算作文扣题度。 (2)通过一种新颖的方式构建了图神经网络,综合了各个句子的相似度计算文档 相似度,提高了模型准确性和鲁棒性。使用Triplet network引入第三个文档建模句子间相 似度。传统方法一般使用孪生网络进行两个句子的相似度匹配,Triplet Network网络训练 时损失函数得到的信息更多,得到的向量表示更好。 附图说明 图1为本发明一种基于作文扣题度的自动作文评分计算方法的流程图; 图2为本发明一种基于作文扣题度的自动作文评分计算方法的结构框图。











