
技术摘要:
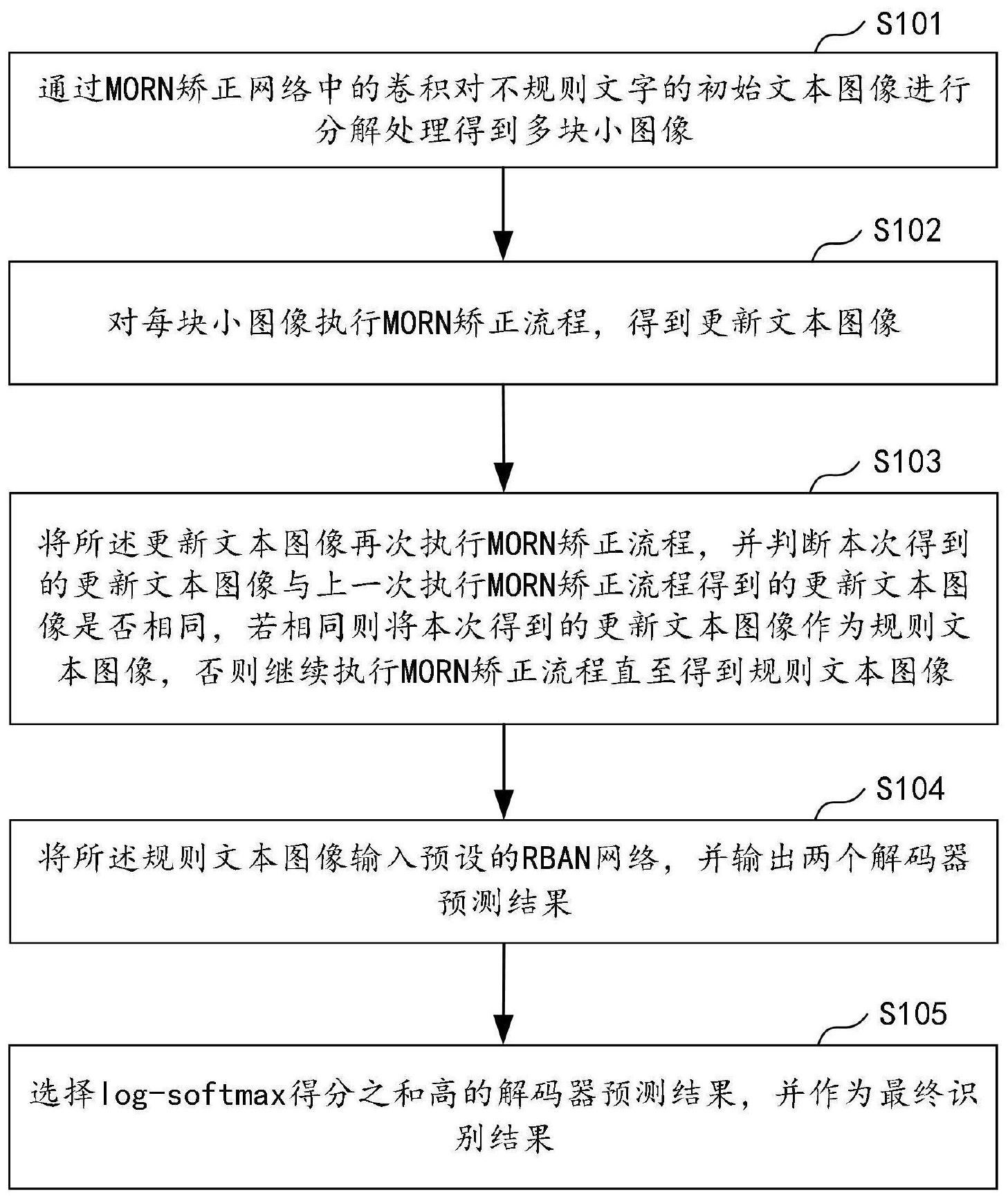
本发明公开了一种不规则文字的识别方法、装置、计算机设备及存储介质,其方法包括:对不规则文字的初始文本图像进行分解处理得到多块小图像;对每块小图像执行MORN矫正流程,得到更新文本图像后将其再次执行MORN矫正流程,并判断本次得到的更新文本图像与上一次得到的 全部
背景技术:
随着智能化的应用,大众和企业对图像或视频中文字识别的需求越来越多,但自 然场景文本识别的难度极高,其原因在于文本的布局可能存在弯曲、褶皱、换向等问题,其 中的文字也可能存在字体多样、字号字颜色不一的问题。 经典的基于深度学习的文字识别方法采用卷积循环网络(CRNN)模型,其以卷积特 征作为输入,通过双向长短期记忆网络(BiLSTM)进行序列处理,可以使得文字识别的效率 大幅提升;但是其只在规则和规范的文字上识别准确率较好,在不规则文字上应用十分有 限。 现有技术中,为解决对不规则文字的识别,各种基于深度神经网络的文字识别模 型也在不断的迭代和发展;其中,多目标矫正注意力网络(MORAN)由矫正子网络MORN (multi-object rectificationnetwork,简称MORN)和识别子网络ASRN(attention-based sequence network,简称ASRN)组成,MORN中设计了一种新颖的像素级弱监督学习机制用于 不规则文本的形状纠正,大大降低了对不规则文本的识别难度。 但是,该多目标矫正注意力网络仅仅对变形角度较小的不规则文字的识别效果较 好,当文字变形角度较大时,识别率仍然有待提高。
技术实现要素:
本发明的目的是提供一种不规则文字的识别方法、装置、计算机设备及存储介质, 旨在解决现有技术对不规则文字的识别率不高的问题。 第一方面,本发明实施例提供一种不规则文字的识别方法,包括: 通过MORN矫正网络中的卷积对不规则文字的初始文本图像进行分解处理得到多 块小图像; 对每块小图像执行MORN矫正流程,得到更新文本图像; 其中,所述MORN矫正流程包括:对每块小图像进行回归偏移量计算,获得偏移量并 对所述偏移量进行平滑操作;然后在所述初始文本图像上进行采样,将采样点与所述偏移 量进行映射操作,得到更新文本图像; 将所述更新文本图像再次执行MORN矫正流程,并判断本次得到的更新文本图像与 上一次执行MORN矫正流程得到的更新文本图像是否相同,若相同则将本次得到的更新文本 图像作为规则文本图像,否则继续MORN执行矫正流程直至得到规则文本图像; 将所述规则文本图像输入预设的RBAN网络,并输出两个解码器预测结果; 其中,所述RBAN网络包括一个编码器和一个带注意力机制的双向解码器; 选择log-softmax得分之和高的解码器预测结果,并作为最终识别结果。 4 CN 111598087 A 说 明 书 2/8 页 第二方面,本发明实施例还提供一种不规则文字的识别装置,其包括: 获取单元,用于通过MORN矫正网络中的卷积对不规则文字的初始文本图像进行分 解处理得到多块小图像; 第一矫正单元,用于对每块小图像执行MORN矫正流程,得到更新文本图像; 其中,所述MORN矫正流程包括:对每块小图像进行回归偏移量计算,获得偏移量并 对所述偏移量进行平滑操作;然后在所述初始文本图像上进行采样,将采样点与所述偏移 量进行映射操作,得到更新文本图像; 第二矫正单元,用于将所述更新文本图像再次执行MORN矫正流程,并判断本次得 到的更新文本图像与上一次MORN执行矫正流程得到的更新文本图像是否相同,若相同则将 本次得到的更新文本图像作为规则文本图像,否则继续执行MORN矫正流程直至得到规则文 本图像; 输出单元,用于将所述规则文本图像输入预设的RBAN网络,并输出两个解码器预 测结果; 其中,所述RBAN网络包括一个编码器和一个带注意力机制的双向解码器; 选择单元,用于选择log-softmax得分之和高的解码器预测结果,并作为最终识别 结果。 第三方面,本发明实施例又提供了一种计算机设备,其包括存储器、处理器及存储 在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序 时实现上述第一方面所述的不规则文字的识别方法。 第四方面,本发明实施例还提供了一种计算机可读存储介质,其中所述计算机可 读存储介质存储有计算机程序,所述计算机程序当被处理器执行时使所述处理器执行上述 第一方面所述的不规则文字的识别方法。 本发明实施例提供一种不规则文字的识别方法、装置、计算机设备及存储介质,其 中方法包括:通过MORN矫正网络中的卷积对不规则文字的初始文本图像进行分解处理得到 多块小图像;对每块小图像执行MORN矫正流程,得到更新文本图像;其中,所述MORN矫正流 程包括:对每块小图像进行回归偏移量计算,获得偏移量并对所述偏移量进行平滑操作;然 后在所述初始文本图像上进行采样,将采样点与所述偏移量进行映射操作,得到更新文本 图像;将所述更新文本图像再次执行MORN矫正流程,并判断本次得到的更新文本图像与上 一次执行MORN矫正流程得到的更新文本图像是否相同,若相同则将本次得到的更新文本图 像作为规则文本图像,否则继续执行MORN矫正流程直至得到规则文本图像;将所述规则文 本图像输入预设的RBAN网络,并输出两个解码器预测结果;其中,所述RBAN网络包括一个编 码器和一个带注意力机制的双向解码器;选择log-softmax得分之和高的解码器预测结果, 并作为最终识别结果。该方法针对不规则文字图像利用MORN方法进行多次矫正得到规则文 字图像,再把规则文字图像输入RBAN网络中进行文字识别,提高了对不规则文字识别的识 别率。 附图说明 为了更清楚地说明本发明实施例技术方案,下面将对实施例描述中所需要使用的 附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普 5 CN 111598087 A 说 明 书 3/8 页 通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。 图1为本发明实施例提供的不规则文字的识别方法的流程示意图; 图2为本发明实施例提供的不规则文字的识别方法的子流程示意图; 图3为本发明实施例提供的不规则文字的识别方法的原理框图; 图4为本发明实施例提供的不规则文字的识别方法的又一子流程示意图; 图5为本发明实施例提供的不规则文字的识别方法的又一子流程示意图; 图6为本发明实施例提供的不规则文字的识别装置的示意性框图; 图7为本发明实施例提供的计算机设备的示意性框图。











