
技术摘要:
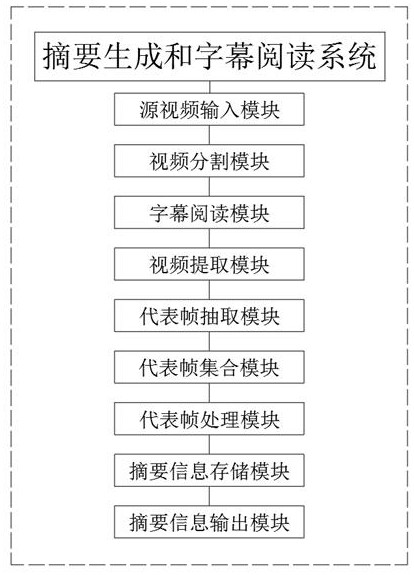
本发明公开了基于多设备体验的智能摘要生成和字幕阅读系统,包括源视频输入模块、视频分割模块、字幕阅读模块、视频提取模块、代表帧抽取模块、代表帧集合模块、代表帧处理模块、摘要信息存储模块和摘要信息输出模块,本发明在生成视频摘要信息时能够快速的通过对各段 全部
背景技术:
数字电视时代已经到来,而它与传统电视的重要区别是具有交互性,在传统电视 时代,用户只能观看每个电视台播放的固定节目,而在交互电视中,用户可以自己选定感兴 趣的节目,视频摘要可以用于为用户提供特定节目的预览信息,以供用户决定是否观看该 节目,并且现在一些用户在用手机、电视观看视频时,只能通过设备听到界面内容或看到显 示的内容,因此为了帮助他们更好的了解内容,需要分析出视频中的内容并生成摘要信息, 而现在用户可以在大部分设备上借助辅助功能来无障碍的使用手机上的功能及阅读手机 上的内容,但仅限于在当前设备中显示及播放; 在现有技术中,关于生成视频摘要信息的方法主要有:1、简单的生成方法,该方法的原 理是基于时间对视频段进行采样,即每隔一定的时间抽取--个或者若干个图像帧作为代表 帧,并以生成的代表帧集合作为相应视频的摘要;2、基于视觉信息的生成方法,该方法是基 于内容分析的方法,它根据视频中的颜色、纹理、形状、运动等视觉信息,运用各种视频和图 像处理技术对视频进行镜头转换边界检测、关键帧提取、场景聚集分类、代表帧提取等一系 列处理;3、基于多特征融合的方法,这种方法就是在基于视觉信息的生成方法的基础上融 入其他媒体中提供的信息,来生成视频的摘要; 而现有技术中,以上三种视频摘要信息生成方法,均存在不同方面的不足之处,如:方 法1中,无法考虑视频的内容,生成的摘要信息没有代表性,效果不理想;方法2中,需要运用 各种视频和图像处理技术来对视频进行一系列的处理,该生成方式,操作繁杂,投入成本 大;方法3中,通用的局限性太大,不利于推广使用,由此可见,需要通过一种更加适合现状 的生成方法来获取视频摘要信息。
技术实现要素:
本发明提供基于多设备体验的智能摘要生成和字幕阅读系统,可以有效解决上述











