
技术摘要:
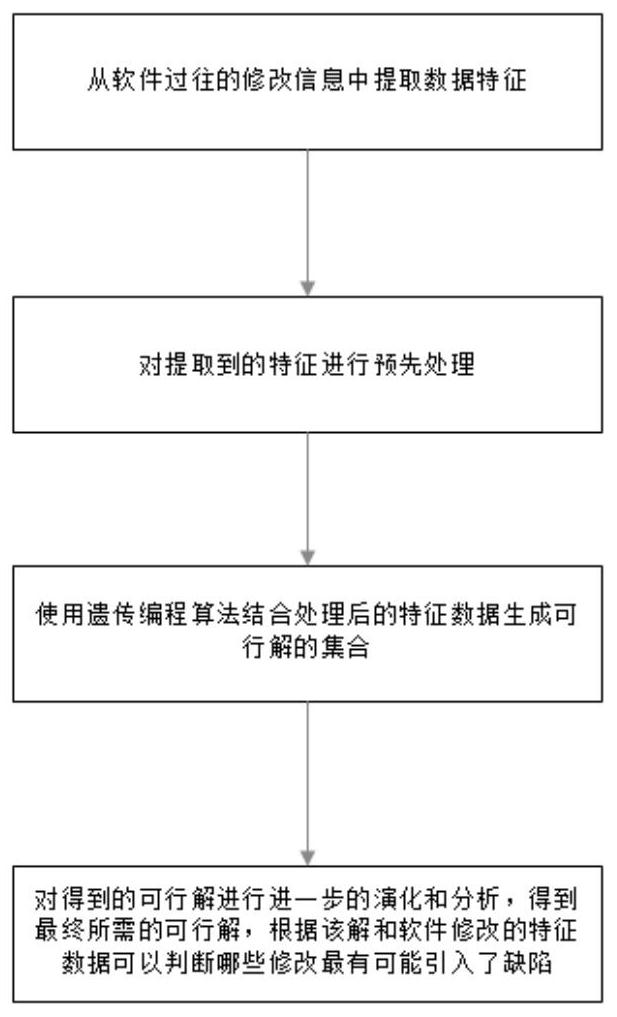
本发明公开了一种代码修改实时缺陷预测的可解释方法,包括以下步骤:1)采集软件代码的历史修改信息;2)从采集的信息中提取存在修改的特征数据和该特征数据对应的具体特征数值;3)结合提取处理后的特征生成初始可行解种群,设置适应度函数,对初始可行解种群进行进一步 全部
背景技术:
目前的社会高度信息化,软件无处不在,无论是跨国企业还是小公司也充斥着大 大小小的软件,为了运行效率,如何保证软件质量是他们重点关注的问题之一。在软件的整 个生命周期,会为了修改功能或修复缺陷等原因对软件进行多次修改,而每次修改都有引 入缺陷的风险。修复缺陷是一个人工成本高昂的工作,如果能较早的发现潜藏的缺陷,修复 它会比较容易,但如果发现的比较晚,定位引发缺陷的代码会比较困难,修复起来也更加不 易。因此,如果能够预测修改是否引入了缺陷,就能够缩小定位缺陷的范围,可以很大程度 上节省成本。 目前在缺陷预测领域,实时缺陷预测(just-in-time defect prediction)显露出 自身的优势。实时缺陷预测相对于非实时缺陷预测,其特点在于,在对软件进行修改后,利 用修改信息及时预测修改是否引入了缺陷。这项技术的优势在于能够很早地发现缺陷,缩 小定位缺陷的范围,帮助程序员去定位缺陷的位置,进一步节省人力,同时也力求在限定成 本内找出最多的缺陷。因此,该技术具有广阔的应用前景,也受到诸多互联网公司的青睐, 譬如Cisco已经将该技术引入了自家的软件开发中。 虽然实时缺陷预测有着上述优点,但是目前市面上的实时缺陷预测技术均不具备 很好的可解释性,这限制了实时缺陷预测的应用。本专利提供了一种可解释方法:使用遗传 编程算法提升可行解对环境的适应度,进而找出合适的最优解,利用该最优解找出最有可 能引入缺陷的修改推荐给开发者检查。其中可行解为:按一定概率选择代码修改的特征、运 算符或-1到1的常数值,组成一个具有数学意义的数学表达式;适应度为:利用可行解和修 改的具体特征数值计算修改的得分,按照得分对所有修改进行升序排列,引入缺陷的修改 的序列号之和即为适应度。不同于黑盒一样的机器学习,本专利利用基于生物学理论的遗 传算法,得到了一个最优解(数学表达式),得到的最优解和运算结果能让开发者更好地理 解具有哪些特征的修改更可能引入缺陷,这使得算法具有很好的可解释性,易于被开发者 所接受。
技术实现要素:
本发明要解决的技术问题在于针对现有技术中的缺陷,提供一种代码修改实时缺 陷预测的可解释方法。 本发明解决其技术问题所采用的技术方案是:一种代码修改实时缺陷预测的可解 释方法,包括以下步骤: 1)采集软件代码的历史修改信息;从代码托管系统,如CVS、SVN或Git中获得软件 代码的历史修改信息; 3 CN 111611010 A 说 明 书 2/4 页 所述历史修改信息包括以下特征数据:NS,修改涉及到的子系统数;NF,修改的文 件总数;entropy,修改在文件中的分布情况;LT,修改前文件的行数;LA,修改增加的行数; LD,修改删除的行数;FIX,本次修改是否有修复缺陷的意图;NEDV,参与修改文件的开发者 总人数;AGE,本次修改与上次修改的时间间隔;NUC,本次修改涉及到而未被上次修改涉及 到的文件数;EXP,开发者的经验;SEXP,开发者对被修改文件所在子系统的开发经验; 2)从采集的信息中提取存在修改的特征数据和该特征数据对应的具体特征数值; 3)结合提取处理后的特征生成初始可行解种群,设置适应度函数,对初始可行解 种群进行进一步的演化和分析,不断的交叉变异,淘汰适应度低的可行解; 3.1)对所有特征数据和加减乘除四则运算符,随机选取多个特征(不少于2个,可 重复选取),结合相应数量的四则运算符,组成一个具有数学意义的数学表达式作为可行 解,依此生成由一堆可行解组成的初代种群; 3.2)根据具体特征数值和该数学表达式计算每个修改的得分,按照得分的大小升 序排列所有修改,计算引入了缺陷的修改的序列号之和,和越大,适应度越高; 3.3)种群不断交叉变异,淘汰适应度低的解,选出最后一代中适应度最高的解作 为最优可行解 4)迭代至最后一代,选出适应度最高的解为最优解,根据最优解和要预测的修改 的具体特征数值计算修改得分,除以对应的检查成本(该修改的增删行数之和),按商降序 排列修改,选出最前端的设定数量的修改返回给开发者,作为所要检查的修改。 按上述方案,所述步骤2)中得到的已被打好标签(是否引入缺陷)数据作为训练 集,并进行如下处理:为避免数量较多的一类(没有引入缺陷的修改)造成数据倾压(训练集 中某类数量过多会使结果产生偏差),随机删除没有引入缺陷的修改,使其数量与引入了缺 陷的修改数量相同;对于特征,将LT替换为LT/NF,再将LA替换为LA/LT、LD替换为LD/LT,最 后将除FIX外的所有特征的数值加1后取2的对数。 按上述方案,所述步骤4)中选出最前端的设定数量的修改返回给开发者,具体如 下: 将最优解下的所有修改的得分排序,选出得分的中位数作为门槛值; 根据特征的具体数据和最优解计算训练数据中每个修改的得分,得分大于门槛值 的修改置预测值defect为1,否则置defect为0,依据defect/(LA LD)的值对修改进行降序 排序,从前往后选出一部分修改,使得这部分修改的总行数占所有修改总行数的20%,选出 的修改即为需要检查的修改。 本发明产生的有益效果是: 本发明利用基于生物学理论的遗传算法,得到了一个最优解(数学表达式),得到 的最优解和运算结果能让开发者更好地理解具有哪些特征的修改更可能引入缺陷,这使得 预测的结果具有很好的可解释性,易于被开发者所接受。本发明提升了实时缺陷预测的可 解释性,使企业或公司在管理软件的过程中有效节省成本。 附图说明 下面将结合附图及实施例对本发明作进一步说明,附图中: 图1是本发明实施例的方法流程图; 4 CN 111611010 A 说 明 书 3/4 页 图2是本发明实施例的方法流程图。











