
技术摘要:
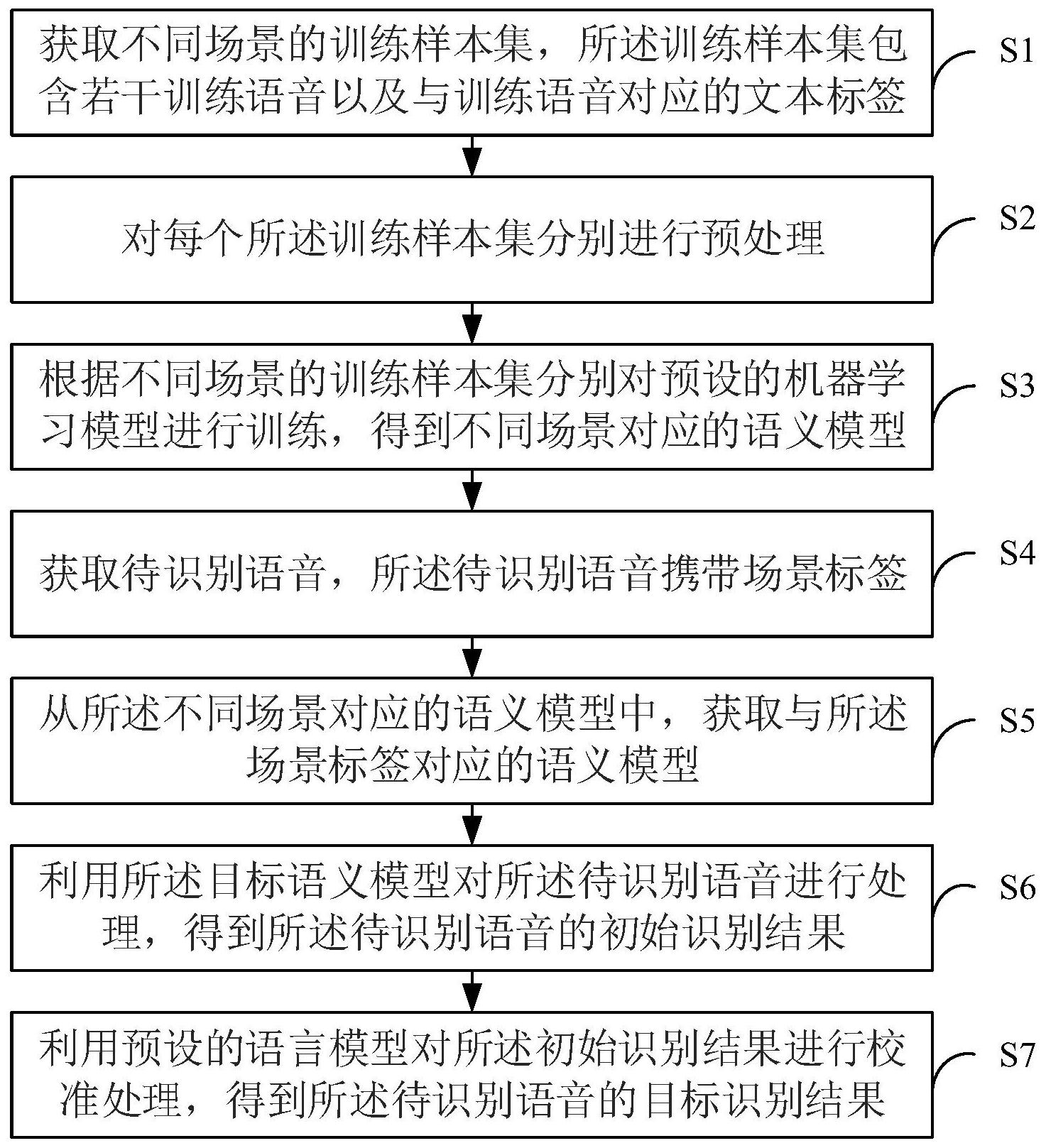
本发明提供一种语音识别方法、系统、电子设备和存储介质,该方法包括:获取不同场景的训练样本集,所述训练样本集包含若干训练语音以及与所述训练语音对应的文本标签;根据不同场景的训练样本集分别对预设的机器学习模型进行训练,得到不同场景对应的语义模型;获取待 全部
背景技术:
目前,随着各公司的业务发展需要,语音识别技术的应用场景越来越多,尤其是在 呼叫中心领域,例如智能语音客服、客服录音质检、外呼失败原因分析等场景下,被广泛应 用。而在不同应用场景下,相同发音的词,含义可能是不一样的。 传统的语音识别技术一般依赖各种复杂的模型设计,包括声学模型和隐马尔可夫 模型(HMM)等。这些模型需由专门的公司为企业用户进行搭建,不仅搭建成本高,限制特殊 的语音格式,而且最重要的是,仅能提供通用语音识别,无法针对用户的特定业务场景进行 针对性识别,识别准确性不高。
技术实现要素:
针对上述现有技术的不足,本发明的目的在于提供一种改进的语音识别方法、系 统、电子设备和存储介质,以解决无法针对用户的特定业务场景进行针对性语音识别,识别 准确性不高的问题。 为了实现上述目的,本发明提供一种语音识别方法,包括: 获取不同场景的训练样本集,所述训练样本集包含若干训练语音以及与所述训练 语音对应的文本标签; 根据不同场景的训练样本集分别对预设的机器学习模型进行训练,得到不同场景 对应的语义模型; 获取待识别语音,所述待识别语音携带场景标签; 从所述不同场景对应的语义模型中,获取与所述场景标签对应的语义模型; 利用所述目标语义模型对所述待识别语音进行处理,得到所述待识别语音的初始 识别结果; 利用预设的语言模型对所述初始识别结果进行校准处理,得到所述待识别语音的 目标识别结果。 在本发明一个优选实施例中,所述根据不同场景的训练样本集分别对预设的机器 学习模型进行训练,得到不同场景对应的语义模型的步骤包括分别针对每个所述场景执行 以下步骤: 按预定比例将目标场景的训练样本集划分为训练集和测试集; 根据所述训练集,对所述机器学习模型进行训练; 根据所述测试集,对训练得到的机器学习模型进行测试,当测试通过时,将训练得 到的机器学习模型作为目标场景对应的语义模型。 在本发明一个优选实施例中,所述根据所述训练集,对所述机器学习模型进行训 4 CN 111613212 A 说 明 书 2/7 页 练的步骤包括: 将所述训练集划分为多个批次; 利用各批次的训练集依次对所述机器学习模型进行训练,直至满足训练完成条 件。 在本发明一个优选实施例中,所述将所述训练集划分为多个批次的步骤包括: 将频谱特征相同或相近的训练语音划分至同一批次。 在本发明一个优选实施例中,所述将所述训练集划分为多个批次的步骤包括: 获取时长相近的多段训练语音; 通过静默音填充方式将所述多段训练语音调整为时长一致; 将所述时长调整为一致的多段训练语音划分至同一批次。 在本发明一个优选实施例中,所述机器学习模型为循环神经网络模型;和/或所述 语言模型为N-grams模型。 在本发明一个优选实施例中,所述根据不同场景对应的训练样本集对预设的机器 学习模型进行训练,得到不同场景对应的语义模型的步骤之前,所述方法还包括对每个所 述训练样本集分别进行预处理,所述预处理包括: 提取每个训练样本集中所述训练语音的频谱特征; 对每个训练样本集中所述文本标签进行分词处理。 为了实现上述目的,本发明提供一种语音识别系统,包括: 样本获取模块,用于获取不同场景的训练样本集,所述训练样本集包含若干训练 语音以及与所述训练语音对应的文本标签; 模型训练模块,用于根据不同场景的训练样本集分别对预设的机器学习模型进行 训练,得到不同场景对应的语义模型; 语音获取模块,用于获取待识别语音,所述待识别语音携带场景标签; 语义模型确定模块,用于从所述不同场景对应的语义模型中,获取与所述场景标 签对应的语义模型; 模型处理模块,用于利用所述目标语义模型对所述待识别语音进行处理,得到所 述待识别语音的初始识别结果; 校准模块,用于利用预设的语言模型对所述初始识别结果进行校准处理,得到所 述待识别语音的目标识别结果。 在本发明一个优选实施例中,所述模型训练模块包括: 样本划分单元,用于按预定比例将目标场景的训练样本集划分为训练集和测试 集; 训练单元,用于根据所述训练集,对所述机器学习模型进行训练; 测试单元,用于根据所述测试集,对训练得到的机器学习模型进行测试,当测试通 过时,将训练得到的机器学习模型作为目标场景对应的语义模型。 在本发明一个优选实施例中,所述训练单元包括: 批次划分子单元,用于将所述训练集划分为多个批次; 分批训练子单元,用于利用各批次的训练集依次对所述机器学习模型进行训练, 直至满足训练完成条件。 5 CN 111613212 A 说 明 书 3/7 页 在本发明一个优选实施例中,所述批次划分子单元用于: 将频谱特征相同或相近的训练语音划分至同一批次。 在本发明一个优选实施例中,所述分批训练子单元用于: 获取时长相近的多段训练语音; 通过静默音填充方式将所述多段训练语音调整为时长一致; 将所述时长调整为一致的多段训练语音划分至同一批次。 在本发明一个优选实施例中,所述机器学习模型为循环神经网络模型;和/或所述 语言模型为N-grams模型。 在本发明一个优选实施例中,所述系统还包括预处理模块,用于对每个所述训练 样本集分别进行预处理,所述预处理模块包括: 频谱特征提取单元,用于提取每个训练样本集中所述训练语音的频谱特征; 分词单元,用于对每个训练样本集中所述文本标签进行分词处理。 为了实现上述目的,本发明还提供一种电子设备,包括存储器、处理器以及存储在 存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现前述 方法的步骤。 为了实现上述目的,本发明还提供一种计算机可读存储介质,其上存储有计算机 程序,所述计算机程序被处理器执行时实现前述方法的步骤。 通过采用上述技术方案,本发明具有如下有益效果: 本发明首先利用不同场景的训练样本集分别训练得到不同场景对应的语义模型; 而后根据待识别语音携带的场景标签选择对应的语义模型对待识别语音进行针对性识别 处理,识别准确性高;最后,通过预设的语言模型对识别结果进行校准,进一步提高识别准 确性。此外,本发明不限定语音格式,适用范围广,并且模型搭建成本低。 附图说明 图1为本发明实施例1中语音识别方法的流程图; 图2为本发明实施例2中语音识别系统的结构框图; 图3为本发明实施例3中电子设备的硬件架构图。











