
技术摘要:
本发明公开了一种基于GBP的CF方法,上述方法能解决现有技术中的推荐系统没有基于基因维度来进行推荐,只保证在BP维度方面,没有办法从高维度进行匹配推荐的问题,该推荐方法适用于物品数明显小于用户数的场合,新用户只要对一个物品产生行为,就能推荐相关物品给他,但 全部
背景技术:
随着电子商务网站的快速发展,推荐系统已经被广泛研究和应用,推荐系统通过 提取分析用户的资料、行为、评分等信息,获得用户的喜好,来帮助电商找到特定的用户为 其推荐可能购买的产品,增加商品的销售量。 推荐系统通过收集用户的历史评分、交互(浏览、收藏、“点赞”,“踩”等交互行为)、 用户肖像(年龄、职业、性别等)、社交网络和上下文(时间、位置、活动状态、周围人员等)等 数据,对用户的历史兴趣及偏好进行分析,挖掘出用户喜欢的项目(视频、音频、书籍、菜品、 Web服务等信息),然后主动地将相关信息推荐给用户,满足用户的个性化需求。推荐算法是 推荐系统的核心,很大程度上决定了推荐系统的性能。目前主要的推荐算法包括基于内容 的推荐、基于知识的推荐、基于关联规则的推荐、协同过滤推荐和组合推荐等。 目前被广泛研究的推荐系统有的是采用基于内容的推荐算法、协同过滤推荐算法 等。基于内容的推荐算法是通过用户购买过的产品的特征,为用户推荐与其相似的产品。这 种算法的优点是可以处理冷启动问题,处理新加入的产品,并且这种算法不会受到打分稀 疏性的问题,因为它不依赖于用户对产品的评分。但是它的缺点是无法处理像图形、视频和 音乐这种难以分析提取内容特征的商品。 协同过滤算法则是利用用户-产品评分矩阵,计算用户或产品之间的相似度,利用 相似度较高的邻居对其他产品进行评分预测,并根据预测评分的高低为目标用户进行推 荐。但是每一个用户购买的产品数量通常不到产品总数的1%,所以造成用户-产品评分矩 阵非常稀疏,从而使得推荐结果不佳;而基于邻域的协同过滤推荐算法是应用最早的协同 过滤推荐技术,代表性算法为基于用户的协同过滤推荐和基于项目的协同过滤推荐。然而 随着用户规模和项目数量的快速增长,基于邻域的协同过滤推荐算法的计算量大规模增 大,同时产生了严重的评分数据稀疏性问题,即评分稀疏性问题。为了处理可扩展性和评分 稀疏性问题,一些研究学者提出采用基于矩阵分解模型的推荐算法。矩阵分解模型假定“用 户—项目”评分矩阵可以被分解为低维的潜在特征矩阵的乘积,其中潜在特征用于表示用 户偏好或项目特征,如在电影推荐中,这些特征可能为喜剧、悬疑剧、爱情剧因素等。多次国 际性比赛和大量研究都验证了矩阵分解模型具有抗数据稀疏性、易编程、较低的时空复杂 度、较高的推荐精度和良好的可扩展性等优点。 虽然上述推荐方法各有优势,但是,上述推荐方法没有详细对现有用户行为与购 买期望商品进行匹配,匹配度不高;导致需要大量的硬匹配,没有形成完成回路;计算量巨 大,占用大量服务器资源,同时,上述推荐方法也无法实现对新用户进行新商品的匹配。 3 CN 111581527 A 说 明 书 2/4 页
技术实现要素:
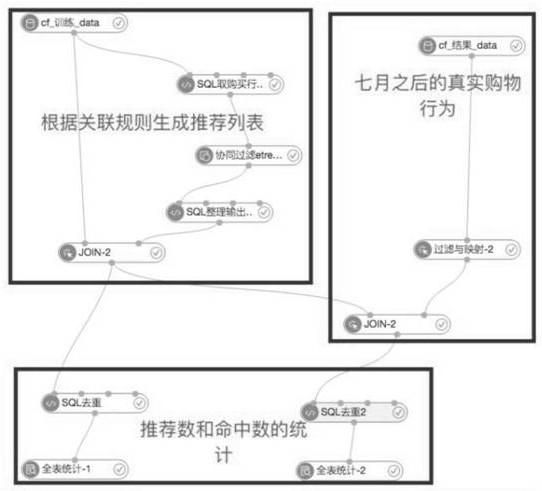
本发明所要解决的技术问题在于针对上述现有技术中的不足,提供一种基于基因 检测的的协同过滤推荐方法,该算法在CF的基础上,通过将用户的基因(Gene),行为 (Behavior),表型(Phenotypic)这三类信息称之为用户的GBP数据,将这些数据进行标签 化,进而形成以用户为基础的GBP标签;将用户的GBP信息进行标签化后,再将内容(商品、文 章、视频、图片等)信息进行标签化,进而将用户的GBP标签和内容的标签进行算法层面的匹 配;本发明中将上述算法称为GBP-CF算法,上述的GBP-CF算法是依据传统协同过滤算法进 行改进。简单来说是利用某兴趣相投、拥有共同经验之群体的喜好来推荐用户感兴趣的信 息,个人通过合作的机制给予信息相当程度的回应(如评分)并记录下来以达到过滤的目的 进而帮助用户筛选商品信息,该算法适用于物品数明显小于用户数的场合,新用户只要对 一个物品产生行为,就能推荐相关物品给他,但无法在不离线更新物品相似度表的情况下 将新物品推荐给用户;用户有新行为,一定会导致推荐结果的实时变化;可以根据用户历史 行为归纳推荐理由。 为实现上述发明目的,本发明采用如下的技术方案: 一种基于基因检测的的协同过滤推荐方法,包含以下步骤: 1)根据用户的GBP数据对用户进行标签化,每个用户就都拥有了各自的GBP标签, 每个标签代表一个不同的item; 2)对内容进行手动打标签,使内容也拥有了一个或多个标签: 3)根据用户的标签和内容标签进行初步的匹配,经过用户使用、反馈和算法校准, 用户已经对一些item做出了喜好判断,喜欢其中的一部分item,不喜欢其中的另一部分; 4)通过用户过去的喜好判断,为用户形成一个用户集合,后续根据用户的实习操 作的数据反馈进行标签权重系数的调整进而优化推荐系统的推荐机制: 5)商品推荐,从上述用户集合中找到和目标用户兴趣相似的用户集合,找到这个 用户集合中用户喜欢的,且目标用户没有听说过的物品推荐给目标用户; 其中,所述的内容为文章、视频、商品、图片等; 其中,在找到和目标用户兴趣相似的用户集合的步骤中,其关键在于计算两个用 户的兴趣相似度;可以通过Jaccard(杰卡德)公式或者通过余弦相似度计算;代码中主要使 用了余弦相似度: 具体算法场景描述: CF算法在大数据中台应用来说是利用某兴趣相投、拥有共同经验之群体的喜好来 推荐用户感兴趣的信息,个人通过合作的机制给予信息相当程度的回应(如评分)并记录下 来以达到过滤的目的进而帮助安我用户筛选信息; 这个矩阵对应的是每一个user的向量同时也对应着每一个item的向量。通过user 的向量之间余弦的计算数据库相对最大值就可以度量出user之间的相似度了; CF典型的就是匹配商品的时候,一定是找用户身边和相似的人来推荐,就是一个 相似的群体。在用户行为上它们的余弦值就非常大(相似度非常高)。 4 CN 111581527 A 说 明 书 3/4 页 本发明中的基于基因检测的的协同过滤推荐方法,上述推荐系统能解决现有技术 中的推荐系统没有基于基因维度来进行推荐,只保证在BP维度方面,没有办法从高维度进 行匹配推荐的问题,该推荐方法适用于物品数明显小于用户数的场合,如果物品很多,计算 物品相似度矩阵的代价较大;新用户只要对一个物品产生行为,就能推荐相关物品给他,但 无法在不离线更新物品相似度表的情况下将新物品推荐给用户;用户有新行为,一定会导 致推荐结果的实时变化;可以根据用户历史行为归纳推荐理由; 附图说明 图1为本发明中整体协同过滤推荐流程示意图; 图2为本发明中的协同过滤流程示意图; 图3为本发明中的购物行为数据示意图; 图4为本发明中的协同过滤结果示意图; 图5为本发明中的推荐示意图; 图6为本发明中结果统计示意图;











