
技术摘要:
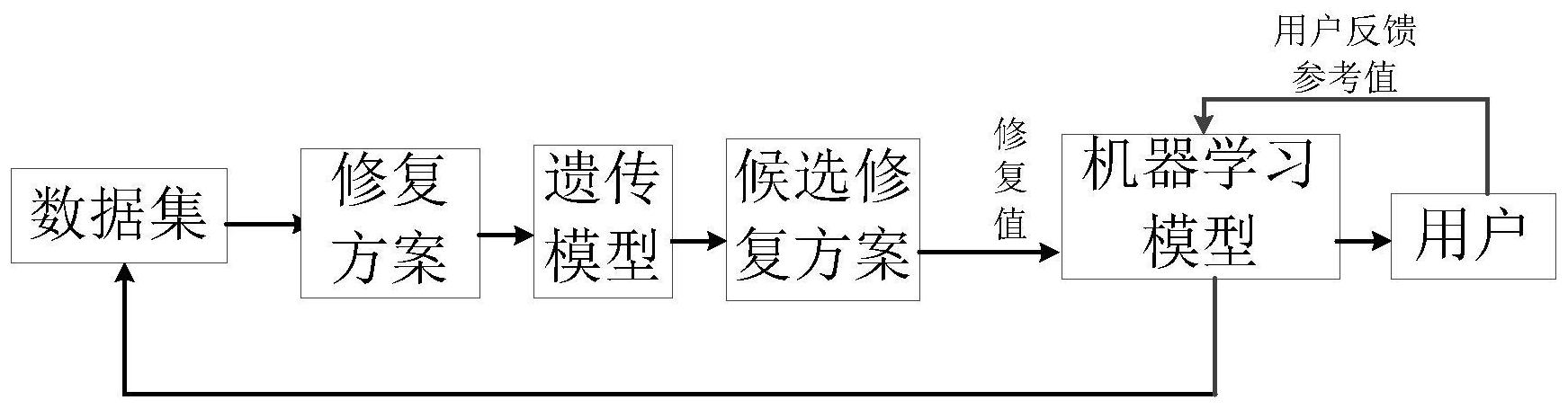
本发明公开了一种大数据修复模型的构建方法和模型构建装置,包括从备选修复方案中选择候选修复方案;利用预先构建多个机器学习模型根据候选修复方案针给出的修复值进行初步训练;利用初步训练完成的各机器学习模型给出预测修复值,并根据各机器学习模型的预测修复值确 全部
背景技术:
当今信息化时代,随着以微博、社交网络等为代表的新型信息发布方式的不断涌 现,人类社会的数据种类和规模正以前所未有的速度在不断的增加和累积,同步数据的爆 发式增长与社会化趋势,将视角瞄准大量的碎片化信息、用户行为、用户关系,并将焦点汇 聚在由此产生的实时数据、非结构化数据及机器数据。由于数据存在规模性(Volume)、高速 性(Velocity)、多样性(Variety)、价值稀疏性(Value)的特征,不可避免的会产生粗糙的、 错误的数据。由于大数据存在错误,并且这些错误会带来严重的后果,需要对大数据中的错 误进行检测与修复,从而确保基于大数据各种应用的有效实施。 目前大部分存在的基于依赖的数据修复方法主要集中在使用不同启发式方法选 择对数据产生最小改变的修复来自动产生答案。但是这些启发式算法不能保证修复的正确 性,并且算法的时间复杂度太高,若果将其应用到重要数据会产生相当大的风险。
技术实现要素:
本发明旨在解决目前数据修复方法正确性不能保证且算法的时间复杂度太高的 技术问题,提出一种大数据修复模型的构建方法和模型构建装置。 为实现上述技术目的,本发明采用了以下技术方案。 一方面,本发明提供了一种大数据修复模型的构建方法,所述大数据修复模型用 于给出待修复数据的修复值,所述大数据修复模型的构建方法包括以下步骤: 从备选修复方案中选择候选修复方案;利用预先构建多个机器学习模型根据候选 修复方案针给出的修复值进行初步训练; 利用初步训练完成的各机器学习模型给出预测修复值,并根据各机器学习模型的 预测修复值确定各机器学习模型的不确定得分,对不确定得分进行排序;获取用户反馈参 考值,并将用户反馈参考值构成新的训练集对不确定得分最高的设定个数的机器学习模型 进行再训练直至满足精度要求;训练完成的机器学习模型就为最终的大数据修复模型。 进一步地,从备选修复方案中选择候选修复方案的方法为采用遗传模型,所述遗 传模型的代价函数如下: Cost(C)=∑t∈Cu(t) 其中u(t,A)表示给定一个修复u,它用来将元组t的A属性值从v修复到v′的评估, Ri表示第i个属性集,C表示元组集合,u(t,A)的表达式如下: (v,v′)表示v和v′的距离。 4 CN 111738442 A 说 明 书 2/7 页 进一步地,所述机器学习模型采用贝叶斯分类器。 进一步地,用户反馈参考值采用众包方式获得。 进一步地,所述候选修复方案给出修复值要满足三个约束条件,第一个约束条件 为:两个元组满足若干特定属性的值相同,由该若干特定属性决定的其它特定属性的值需 要相同的,则其它特定属性的修复值必须要跟另一元组该属性的值相同; 对两个表中的元组必须有特定属性值相同,则修复值必须要满足该约束; 若两个元组在特定属性上的相似度大于该属性阈值,则与该属性关联的其它特定 属性的相似度大于该属性阈值或者特定属性值相等。 进一步地,机器学习模型的不确定得分的计算方法如下: Uscore(I)=∑prlog(pr), 其中pr为机器学习模型给出预测修复值r的频率, 第二方面,本发明提供了一种大数据修复模型的构建装置,包括:所述大数据修复 模型用于给出待修复数据的修复值,所述大数据修复模型的构建装置包括候选修复方案选 择模块和机器学习训练模块: 所述候选修复方案选择模块,用于从备选修复方案中选择候选修复方案; 所述机器学习训练模块,用于利用预先构建多个机器学习模型根据候选修复方案 选择模块确定的候选修复方案针给出的修复值进行初步训练;利用初步训练完成的各机器 学习模型给出预测修复值,并根据各机器学习模型的预测修复值确定各机器学习模型的不 确定得分,对不确定得分进行排序;获取用户反馈参考值,并将用户反馈参考值构成新的训 练集对不确定得分最高的设定个数的机器学习模型进行再训练直至满足精度要求;训练完 成的机器学习模型就为最终的大数据修复模型。 进一步地,所述装置还包括与众包平台对接的接口,用于所述机器学习训练模块 从平台通过众包方式获取用户反馈参考值。 本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算 机程序,其特征在于,所述计算机程序被处理器执行时实现如以上技术方案所提供的方法 的步骤。 本发明还提供了一种计算机程序,包括用于执行以上技术方案所提供的一种大数 据修复模型的构建方法的计算机程序代码,所述计算机程序基于Map-Reduce程序设计模 型,以实现高效计算,以支持大规模数据。 有益技术效果:本发明引入遗传模型来产生候选修复为了减少时间复杂度。利用 机器学习模型给出修复值,保证了修复的正确性;在此基础上对于修复结果不确定的机器 学习模型进行再训练,通过用户参与进来确认候选修复的正确性,这样能进一步改善学习 模型的正确性。 说明书附图 图1是本发明实施例系统框架图; 图2是本发明实施例中引入用户反馈参考值的效率; 图3是本发明实施例中不确定得分机制评估结果对比图。 5 CN 111738442 A 说 明 书 3/7 页











