
技术摘要:
本发明属于视觉图像处理领域,尤其涉及人脸表情识别技术领域,具体涉及一种基于变分自编码器的人脸表情识别方法。本发明首先利用卷积神经网络预测输入人脸图像的面部姿势,并且通过改进损失函数和调整人脸边界框的边距大小提高面部姿势估计的准确度,然后将经过处理的 全部
背景技术:
人脸表情识别是人脸识别技术的重要组成部分,现已广泛应用于处理各种计算机 视觉任务。人脸表情识别是指利用计算机技术获取人脸表情图像、检测人脸表情区域、提取 表情特征和对表情特征进行分类的过程。目前,人脸表情识别的方法主要分为两大类,即传 统的人脸表情识别方法和基于深度学习的人脸表情识别方法。 传统的人脸表情识别方法主要包括主成分分析法(PCA)、独立分量分析法(ICA)、 几何法、光流法、模型法。传统的人脸表情识别方法主要根据人脸产生表情时的人脸形状和 纹理的不同来区分不同的面部表情,具有易于理论证明和实现简单等优点,然而识别精度 并不理想,不能很好地推广到现实的各种应用场景中。 基于深度学习的人脸表情识别方法在计算机视觉处理方面不断取得突破,由于深 度学习中的神经网络,特别是卷积神经网络(CNN),能够有效地从人脸表情图像中提取表情 特征信息,并且对于提取的表情特征能够进行有效地预测分类,大大提高了人脸表情识别 的效率和准确率。目前,基于深度学习的人脸表情识别研究中,还可以通过对网络层的卷积 神经网络层,递归神经网络层和全连接层等进行组合形成新的网络形式。 然而,现有的人脸表情识别研究面临着五大难题,它们分别是面部姿势的偏转、面 部的配准误差、面部上有遮挡物、光照的变化和不同身份的差异。其中,面部姿势的偏转是 造成配准误差和面部遮挡的一个重要原因。但是大多数方法在解决人脸表情识别时没有考 虑到非正面人脸图像的特殊性,当涉及到人脸检测和面部姿势估计时又分开进行处理,无 法构成一个统一的完整系统,不是一种端到端的方法。并且在非正面的人脸表情识别模型 的训练过程中,由于缺乏足够的训练样本,容易导致过度拟合问题。
技术实现要素:
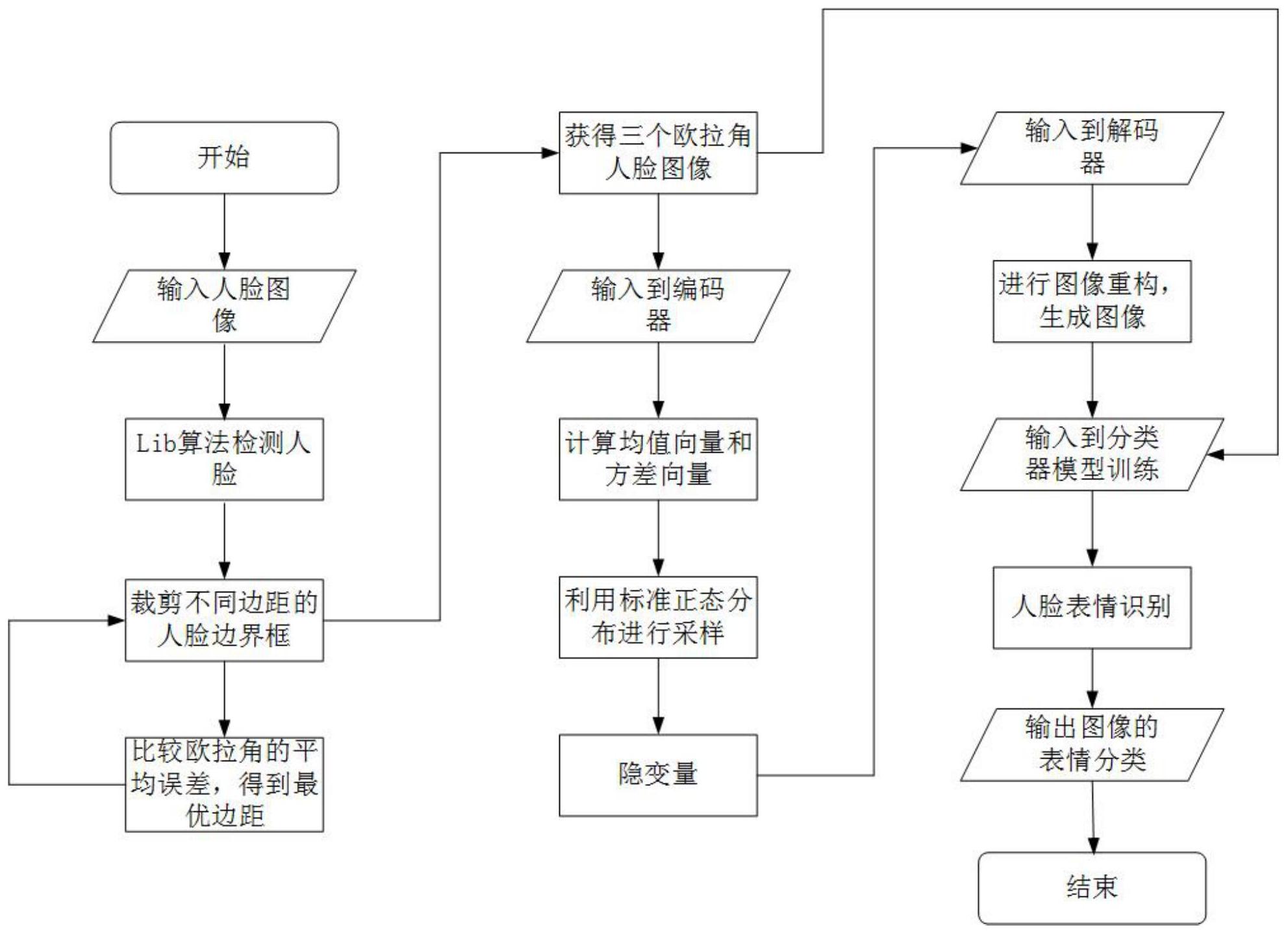
本发明的目的在于提供解决非正面人脸表情识别研究过程中由于头部姿势偏转、 配准误差带来人脸信息的缺失以及缺乏足够的训练样本而造成的过拟合问题,提高人脸表 情识别的准确度的一种基于变分自编码器的人脸表情识别方法。 本发明的目的通过如下技术方案来实现:包括以下步骤: 步骤1:输入待识别的人脸图像数据集,取部分人脸图像构建训练集; 步骤2:通过Lib人脸检测算法对训练集中人脸图像进行处理,获得每幅图像中人 脸的方形边界框; 步骤3:从训练集中选择一幅带有方形边界框的人脸图像,在边界框的基础上基于 不同的边距对人脸图像进行裁剪,获得不同边距的人脸方形边界框图像; 步骤4:将不同边距的人脸方形边界框图像输入到预先训练好的卷积神经网络模 4 CN 111582059 A 说 明 书 2/7 页 型中,卷积神经网络模型输出人脸图像的三个欧拉角,即左右翻转角、平面旋转角、上下俯 仰角; 步骤5:通过组合损失函数,比较不同边距下人脸图像欧拉角的平均误差,确定最 优的边距K;将最优边距K时卷积神经网络模型输出的三个欧拉角作为人脸图像的面部姿 势; 步骤6:判断是否完成训练集中全部人脸图像的面部姿势提取;若未完成,返回步 骤3; 步骤7:将训练集中的人脸图像输入到变分自编码器中进行训练; 步骤8:变分自编码器训练完成后,在正态分布N(0,I)下进行采样,将采样到的隐 变量向量输入到变分自编码器的解码器中进行重构,生成不同姿势和表情的人脸图像; 步骤9:将步骤8中生成的图像与步骤7中训练集的原始图像共同作为训练样本输 入到分类器模型中进行训练,学习不同姿势和表情的人脸图像的特征信息; 步骤10:将待识别的人脸图像数据集中其他人脸图像输入到训练好的分类器模型 中,通过分类器模型中的全连接层对特征信息进行分类,实现非正面条件下不同姿势的人 脸表情识别。 本发明还可以包括: 所述的步骤7中将训练集中的人脸图像输入到变分自编码器中进行训练的方法具 体为: 步骤7.1:通过变分自编码器对人脸图像的特征进行学习,获得人脸图像的均值向 量和方差向量; 步骤7.2:将人脸图像的均值向量和方差向量按照正态分布N(0,I)进行采样,得到 包含不同姿势和表情潜在属性的隐变量向量; 步骤7.3:构建模型的反向传播;计算生成的隐变量向量的数据分布与正态分布N (0,I)的距离,同时计算生成数据与原始数据间的交叉熵损失;将两种损失值放在一起,通 过Adma的随机梯度下降算法来实现在训练中的优化参数。 所述的步骤4中预先训练好的卷积神经网络模型为在ImageNet数据集上预先训练 的ResNet50卷积神经网络,在最后的平均池化层后面放置3个模块,分别用于输出翻转角, 偏转角和俯仰角三个欧拉角的预测;将[-90°, 90°]区间分为181类,每一类对应一个角度 值;ResNet50对图像中人脸姿势的翻转角,偏转角和俯仰角分别使用离散数和连续数来预 测同一个角度,三个模块都从ResNet50的平均池化层接收相同的输出1×1×2048;通过使 用2048×1的全连接层FC1将从ResNet50获得的输出映射成单个连续的数字,使用2048× 181的全连接层FC181将输出通过激活函数softmax分别获得181个类别的概率。 所述的步骤5中的组合损失函数具体为: 其中,α是权衡两个损失的权重;回归损失函数LMSE表示的是均方误差;LMSE的公式 如下所示: 5 CN 111582059 A 说 明 书 3/7 页 其中,yi是第i个样本的真实角度; 是第i个样本的预测角度; 分类损失函数LS采用温度缩放的方式使得每个类的分数分布更广;LS的公式如下 所示: 其中,Wj是最后一个全连接层的第j列;T是温度缩放参数。 本发明的有益效果在于: 本发明首先利用卷积神经网络预测输入人脸图像的面部姿势,并且通过改进损失 函数和调整人脸边界框的边距大小提高面部姿势估计的准确度,然后将经过处理的人脸图 像输入到变分自编码器中,通过给定人脸图像中姿势和表情属性的概率分布,生成不同姿 势和表情的人脸图像来扩充表情识别模型的训练集,从而解决模型在训练的过程中,由于 头部姿势偏转造成的识别精度不高和缺乏足够的训练数据造成的过拟合问题。最后利用生 成图像和原始图像一起作为训练数据对分类器模型进行训练,实现非正面人脸表情识别。 附图说明 图1为一种基于变分自编码器的人脸表情识别方法的框架图。 图2为一种基于变分自编码器的人脸表情识别方法的流程图。 图3为一种基于变分自编码器的人脸表情识别方法的裁剪示例图。 图4为一种基于变分自编码器的人脸表情识别方法中实现人脸姿势估计的架构 图。 图5为一种基于变分自编码器的人脸表情识别方法中变分自编码器生成图像的原 理图。











