
技术摘要:
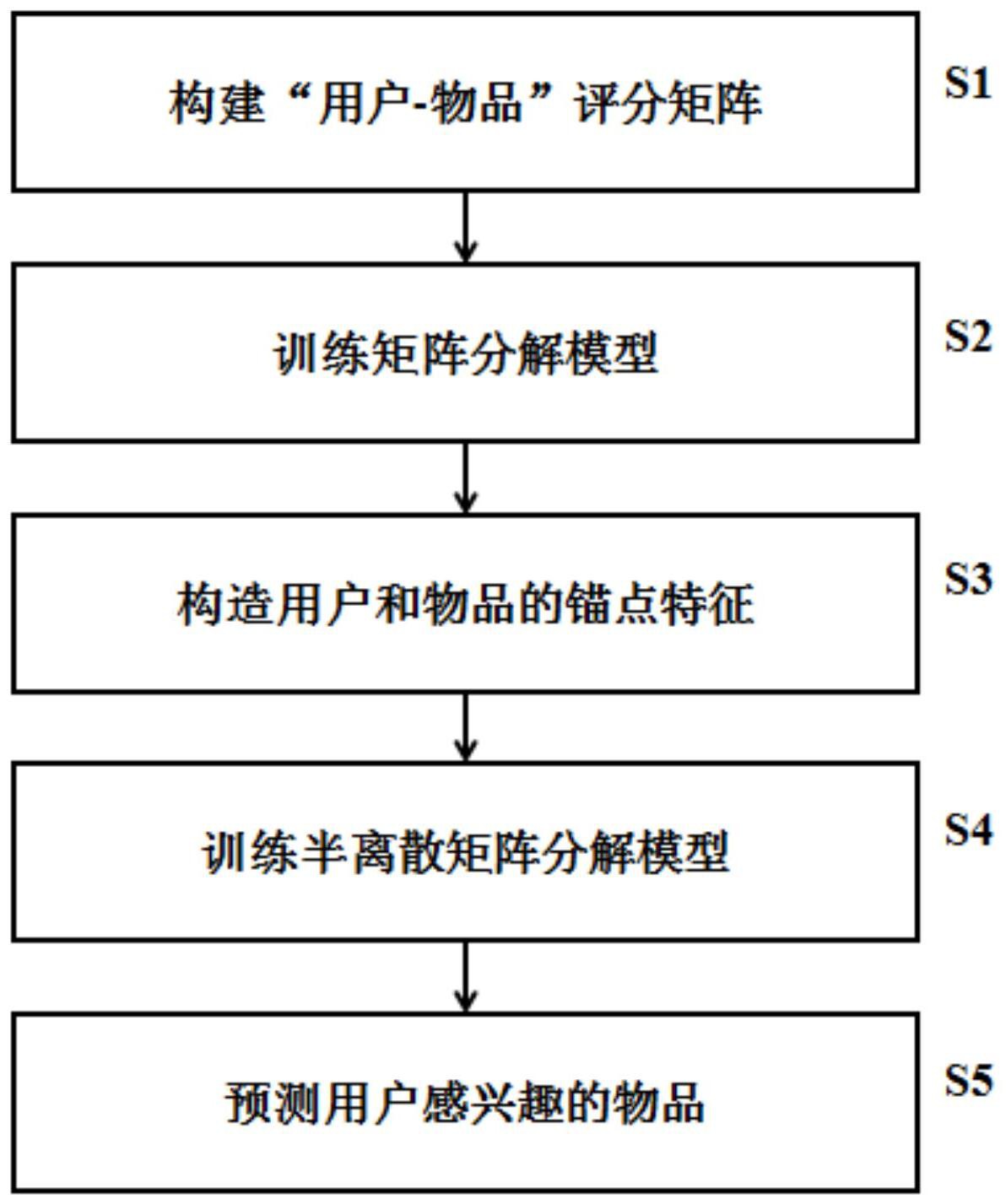
本发明公开一种基于半离散矩阵分解的物品推荐方法。该方法包括:构建用户‑物品评分矩阵R,根据用户‑物品评分矩阵R训练矩阵分解模型,获得用户的实值特征矩阵P和物品的实值特征矩阵Q;根据P对用户独立执行聚类分析,获得用户的锚点特征矩阵E,根据Q对物品独立执行聚类 全部
背景技术:
大数据时代,多元化网络平台与各类移动应用泛在互连,网络信息服务日益表现 出“以用户为中心”的特点。如何有效挖掘用户的网络足迹,并为其提供精准的个性化服务 已成为当下学术界和工业界共同关注的热点话题。在此背景下,推荐系统应运而生,在对抗 信息过载并提供个性化信息服务方面扮演着重要角色。 协同过滤是构建个性化推荐系统的核心技术之一。现有协同过滤技术中的一种主 流方法为MF(Matrix Factorization,矩阵分解)模型,通过分解“用户-物品”交互矩阵,构 建用户和物品共享的实值特征空间;基于该特征空间,所有用户和物品被表示为低维实值 向量。继而通过计算用户特征向量和物品特征向量内积的方式估计二者之间的相关性,并 将相关性较高的物品推荐给相应用户。 上述MF模型的缺点为:随着在线用户和物品数量迅猛增长,MF模型的在线预测效 率严重受限于在线用户和物品的数量,难以适用于大规模实时推荐任务。 MF模型的轻量化版本称为DMF(discrete matrix factorization,离散矩阵分解) 模型,通过分解“用户-物品”交互矩阵,构建用户和物品共享的海明特征空间;基于该特征 空间,该模型将向量空间下的用户、物品实值特征替换为海明空间内的二值编码,进而推荐 任务可借助逻辑运算高效执行。 上述DMF模型的缺点为:由于二值编码较之实值特征携带信息量较小,使其推荐准 确性严重受损。换言之,DMF模型以牺牲推荐精度为代价换取预测效率,使得DMF模型的推荐 精度严重衰减。
技术实现要素:
本发明的实施例提供了一种基于半离散矩阵分解的物品推荐方法,以克服现有技 术的问题。 为了实现上述目的,本发明采取了如下技术方案。 一种基于半离散矩阵分解的物品推荐方法,包括: 构建用户-物品评分矩阵R,用于记录用户对物品的评分行为; 根据用户-物品评分矩阵R训练矩阵分解模型,获得用户的实值特征矩阵P和物品 的实值特征矩阵Q; 根据用户的实值特征矩阵P对用户执行聚类分析,获得用户的锚点特征矩阵E,根 据物品的实值特征矩阵Q对物品执行聚类分析,获得物品的锚点特征矩阵F; 根据R、P、Q、E、F训练半离散矩阵分解模型,获得用户的二值编码矩阵B和物品的二 值编码矩阵D; 5 CN 111552852 A 说 明 书 2/9 页 根 据 用 户的 二值 编码矩阵 B 和物品的 二值 编码矩阵 D还原评分 矩阵 根据R将 中已观测评分位置的预估值置0,根据评分矩阵 将预测分值 最高的前设定数量个物品推荐给相应用户。 优选地,所述的构建“用户-物品”评分矩阵R,用于记录用户对物品的评分行为,包 括: 构建“用户-物品”评分矩阵,用于记录用户对物品的评分行为,其中m、n分别表示 用户、物品的数量,并对“用户-物品”评分矩阵R中的评分数据进行归一化处理,所述物品包 括产品或者服务。 优选地,所述的根据“用户-物品”评分矩阵R训练矩阵分解模型,获得用户的实值 特征矩阵P和物品的实值特征矩阵Q,包括: 根据“用户-物品”评分矩阵R训练矩阵分解模型,获得用户的实值特征矩阵 和物品的实值特征矩阵 P的第u列 表示用户u的特征向量,Q的 第列 表示物品i的特征向量,其中f为特征空间维数。 优选地,所述的根据用户的实值特征矩阵P对用户执行聚类分析,获得用户的锚点 特征矩阵E,根据物品的实值特征矩阵Q对物品执行聚类分析,获得物品的锚点特征矩阵F, 包括: 根据用户的实值特征矩阵P对用户执行聚类分析,获得用户的锚点特征矩阵 根据物品的实值特征矩阵Q对物品执行聚类分析,获得物品的锚点特征矩阵 E的第u列 表示用户u所在群组的簇中心,F的第列 表示物品i所在 群组的簇中心,所述簇中心为锚点特征。 优选地,所述的根据R、P、Q、E、F训练半离散矩阵分解模型,获得用户的二值编码矩 阵B和物品的二值编码矩阵D,包括: 所述半离散矩阵分解模型的目标函数定义如下: 其中 表示损失项, 和 分别为“点级”和“组级”平滑项, 用于异构空间下的 特征表示对齐, 用于保持原向量空间中“用户-用户”、“物品-物品”之间几何结构; 损失项 定义如下: s.t.B∈{±1}f×m,D∈{±1}f×n 其中Ω是由已观测评分对应的(u,i)索引组成的集合; “点级”平滑项定义为: 用于控制同一个用 户、物品的二值编码与其对应的实值特征之间的差异,据此实现异构空间下的表示对齐; “组级”平滑项定义为: 用于控制用户、物品的 二值编码与其对应的锚点特征之间的差异,据此保持原向量空间中数据点间的拓扑结构, 即原空间中处于同一群组的用户或物品应该具有相似的二值编码; 6 CN 111552852 A 说 明 书 3/9 页 正则项定义为: 用于控制编码平衡,以期最大化编码的 信息熵; 合并整理各项后,半离散矩阵分解模型的最终目标函数表示如下: 其中,α1,α2,β1,β2,γ>0为超参数,1m,1n表示m,n维全1向量。 所述半离散矩阵分解模型的训练过程包括如下步骤: S4-1:模型初始化;将用户特征矩阵B和物品特征矩阵D进行二值量化,作为半离 散矩阵分解模型的目标变量的初始值:B=sgn(P)和D=sgn(Q); S4-2:进入迭代训练过程,固定D,更新B;当固定D时,离散矩阵分解模型的目标函 数等价于如下优化问题: 其中Ωu表示已观测评分对应的(u,i)索引对中u所构成的集合; 采用离散坐标下降算法对bu进行逐位更新;设 其中buk表示bu的第k 位, 表示除buk以外其余二值编码所组成的向量;类似的, 具体buk的更新规则如下: 当α≠0时,K(a,b)=a,否则K(a,b)=b;如果 不对buk进行更新; S4-3:固定B,更新D;当固定B时,半离散矩阵分解模型的目标函数等价于如下优化 问题: 其中Ωi表示已观测评分对应的(u,i)索引对中i所构成的集合;采用离散坐标下 降算法对di进行逐位更新;设 具体dik的更新规则如下: 7 CN 111552852 A 说 明 书 4/9 页 同样,如果 更新dik,否则,不对dik进行更新; S4-4:重复S4-2到S4-3,直到满足迭代停止条件,模型收敛,输出所述半离散矩阵 分解模型的参数B和D。 优选地,所述的迭代停止条件包括:目标函数值小于某个预设定阈值,或B和D的每 一位都不再发生变化。 由上述本发明的实施例提供的技术方案可以看出,本发明实施例的基于半离散矩 阵分解模型SDMF的个性化服务推荐方法通过综合运用“点级”平滑和“组级”平滑技巧,有效 弥补了DMF模型的推荐准确性和推荐精度不高的缺点;其预测效率与DMF模型相当,推荐精 度大幅度提升。 本发明附加的方面和优点将在下面的描述中部分给出,这些将从下面的描述中变 得明显,或通过本发明的实践了解到。 附图说明 为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用 的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本 领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的 附图。 图1为本发明实施例提供的一种基于半离散矩阵分解模型的个性化服务推荐方法 的工作流程图; 图2为本发明实施例提供的一种半离散矩阵分解模型的训练工作流程图; 图3为本发明方法SDMF与离散矩阵分解模型DMF在MovieLens100K数据集上推荐精 度和预测效率的实验结果对比 图4为本发明方法SDMF与离散矩阵分解模型DMF在“豆瓣”数据集上推荐精度和预 测效率的实验结果对比。











