
技术摘要:
本发明涉及一种基于特征自匹配迁移学习的纺纱全流程能耗监测方法,该方法通过深度卷积神经网络从旧厂历史数据集中学习知识规律,并迁移到新厂纺纱能效的异常趋势识别中,以弥补新厂异常样本不足的问题。同时,针对迁移过程中由于源域、目标域之间数据特征不匹配造成的 全部
背景技术:
纺纱是典型的能耗密集型民生行业,中国2018年纺纱耗电量达到约700亿度,但有 效利用率不足75%,其中有大量能耗浪费在滞后的异常发现。在纱线生产过程中,由于生产 事件或生产环境的变化,吨纱耗电量时常出现远远偏离正常值的异常现象,滞后的发现导 致了大量的能源浪费。在生产过程中进行能效监测是抑制这种情况的最有效的手段之一, 及时监测发现纺纱过程中的能效异常,对于节能降耗、降低纺纱成本具有重要意义! 随着数据感知和人工智能技术的发展,部分学者开始使用深度神经网络通过实时 感知的能效时间序列数据来侦测能效的异常趋势。但是,其有效性需要两个先决条件:(1) 训练数据与测试数据具有相同的工况和生产环境。(2)具有足够的历史异常数据。但在实际 纱线生产过程中,纺纱车间具有复杂而实时变化的生产环境,例如原棉的更换,罗拉部件受 飞花的缠绕以及车间内温、湿度的变化等,这往往导致训练数据和测试数据的不同特征分 布。同时,能效异常的历史数据样本相对有限,不足以覆盖纺纱车间复杂多变的能效异常模 式和规律。这将会降低异常侦测模型的泛化能力,甚至使该模型不再适用。 为了解决这一问题,有些学者提出了迁移学习方法,通过学习与目标数据相似的 其他辅助数据(源域)的知识,然后将学习到的知识迁移到目标域,以训练泛化能力强的分 类器。例如,张康教授团队将从ImageNet数据集预训练的网络迁移到糖尿病的诊断中,其识 别能力已经超过了专业医生。Fawaz做了大量实验来研究时间序列数据分类的迁移学习问 题,实验结果表明,通过迁移学习在85个数据集中提高了71个数据集的准确性。受以上研究 的启发,考虑从辅助时间序列数据集中学习知识,迁移到纺纱能效异常的识别中。
技术实现要素:
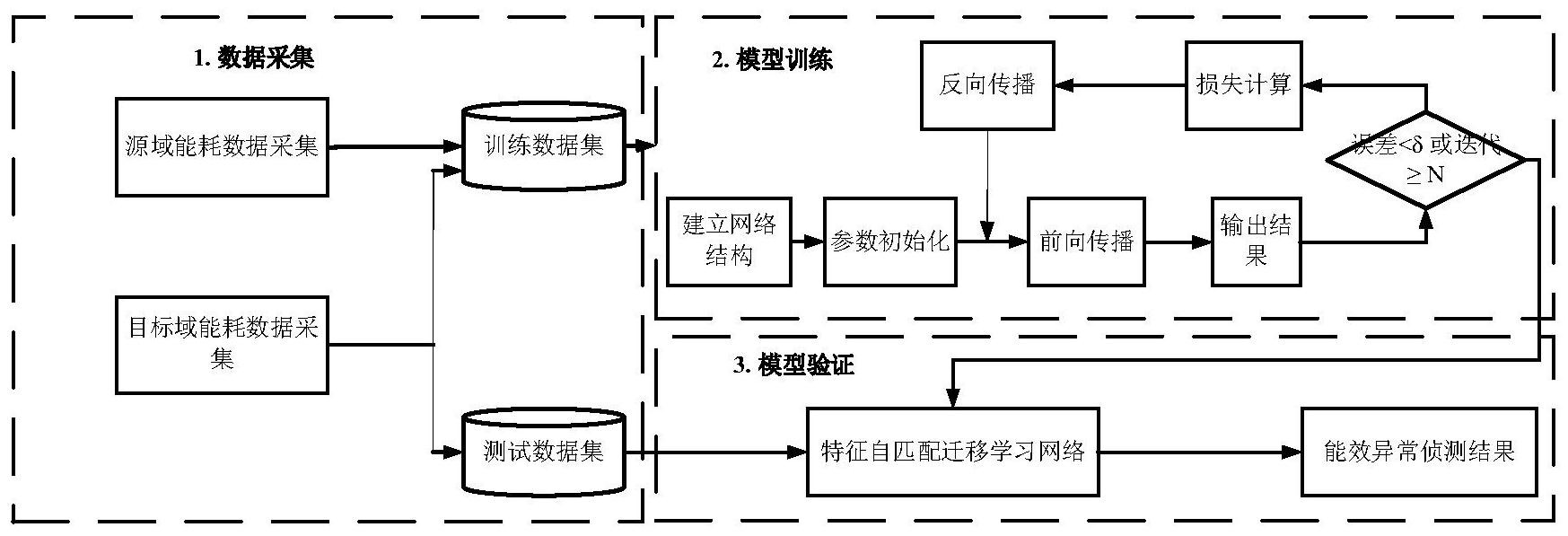
本发明的目的是:实现纺纱全流程能耗提前监测,通过迁移学习方法将旧厂历史 能耗数据迁移到新厂的能耗监测模型中,提高能耗征兆性侦测精度,解决新厂能耗监测冷 启动问题。 为了达到上述目的,本发明提出了基于特征自匹配迁移学习的深度神经网络。建 立了两个并行卷积神经网络作为纺纱车间旧厂历史能效数据集(源域)和新厂能效数据集 (目标域)上的特征提取器和分类器。在源域和目标域的并行网络之间,设计了特征自匹配 的适应层分别对源数据集和目标数据集的特征表示进行聚类,然后最小化源域和目标域的 最近邻特征之间的距离,聚拢匹配类特征促进积极迁移,剔除离群类特征抑制负迁移。与最 新方法相比,本发明提供的模型能够更准确地侦测纺纱能效的异常情况。 具体而言,本发明提供了一种基于特征自匹配迁移学习的纺纱全流程能耗监测方 法,其特征在于,包括以下步骤: 5 CN 111738413 A 说 明 书 2/9 页 步骤1、每台纺纱设备装有一个智能电表,每T秒钟读取一次智能电表的能耗数据 并每T秒钟从信息系统读取每台纺纱设备的纱线产量,每T秒钟获取一次每个纺纱设备的比 能效值,如下式(1)所示: 式(1)中, 表示从时间tn-1到时间tn生产单位纱线所消耗的电量, 代表一 台纺纱设备在时间tn的功耗, 代表一台纺纱设备在时间tn的纱线产量; 步骤2、采用下式(2)将不同支数的纱线产量转换为标准纱支数进行标准统一: 式(2)中,λ为转换系数;Tex表示实际纱线支数,V表示实际锭速,Tt表示纱线的实 际捻度;TexS表示标准纱线支数,VS表示标准锭速,Tt表示标准纱线捻度; 步骤3、收集历史的包括能耗数据、纱线产量、比能效值在内的能效时间序列数据 并标注正常类别和异常类别的对应标签,形成用于训练识别模型的训练数据集,标注正常 类别和异常类别的对应标签时,根据企业的标准建立能效异常判断规则的隶属度函数 如下式(3)所示对正常类别和异常类别进行判断: 式(3)中,tn~tn-k表示一个移位的时间区间;YS表示生产每单位纱线的标准功耗;η 表示容忍度;若 不小于预设的阈值,则能效时间序列数据中相应数据属于异常 类别,并依据不同的异常原因,进一步将异常类别划分为不同纺纱能效异常类型,依据纺纱 能效异常类型对相应能效时间序列数据进行对应标签的标注,否则能效时间序列数据中相 应数据属于正常类别,标注正常类别的对应标签; 步骤4、建立基于特征自匹配的深度神经网络结构作为识别模型,利用上一步得到 的训练数据集对识别模型进行训练,该深度神经网络结构由一个输入层、五个卷积层 COV.1-COV.5、三个全连接层FC.1-FC.3、一个基于特征自匹配的自适应层和一个输出层组 成,其中:每个卷积层通过执行卷积运算将输入层的输入转换为多元时间序列来学习输入 能效时间序列的特征图,每个卷积层之后是全局平均池化操作,该平均池化操作对时间轴 上的每个能效时间序列进行平均,用于对卷积层提取的特征进行欠采样,以减小特征图的 大小并抑制模型的过拟合;自适应层表示最小化源域和目标域的最近邻居聚类中心之间的 距离,该距离可以自动匹配不同类别的源域和目标域时间序列数据; 步骤5、将实时获得的能效时间序列数据输入训练后的识别模型,由识别模型对能 耗是否异常进行判断,若判断为异常,获得相应的纺纱能效异常类型。 优选地,步骤3中,所述纺纱能效异常类型包括渐变型、阶跃型、周期型及其他类 型,其中渐变型所对应的异常原因为牵伸、绕卷部件磨损,传动部件、皮辊受飞花阻塞导致 6 CN 111738413 A 说 明 书 3/9 页 阻力变大,车间温度、湿度变化,断头未及时处理;阶跃型所对应的异常原因为工艺变动,原 棉变动,皮辊、皮圈过热相对滑动,电表或传感器故障;周期型所对应的异常原因为纱线断 头频繁,电压、电流波动;其他类型所对应的是无法判断原因的异常情况。 优选地,步骤3中,一旦确定为异常,则查找当班生产过程记录,以进一步确定异常 发生的时间节点和异常原因,然后,在时间节点之前提取固定长度的能效时间序列数据,并 根据异常原因标定异常类别,其中时间序列数据的数量等于监测窗口的长度。 优选地,步骤4中,所述深度神经网络结构中: 所述输入层的输入x是具有固定长度的时间序列数据; 将所述自适应层中源域和目标域时间序列的特征表示聚类为CS和Ct,即CS表示源 域的类分布,Ct表示目标域的类分布,则所述输出层的输出y是源数据集和目标数据集中CS 类和Ct类的预测分布,|CS|>|Ct|,CS和Ct具有相同大小的占位符。 优选地,步骤4中,所述卷积层采用下式(4): 式(4)中,Sij是经过卷积运算后得到的特征图;H和W表示输入的高度和宽度;F表示 卷积核的高度和宽度大;S表示卷积核运动的步长;Wrc代表卷积核位于(r,c)位置的权重;B 表示偏差;δ表示非线性激活函数;Xrc代表该时刻的能效监测值。 优选地,步骤4中,每个所述全连接层执行下式(5)所示的非线性映射: 式(5)中, 表示第 个全连接层,δ表示非线性激活函数, 和 分别表示第 个全连接层的权重和偏差。 优选地,步骤4中,所述自适应层的设计包括以下步骤: 收集属于相同簇的x的特征表示,并有序地存储在聚类矩阵中,如下式(6)所示: 式(6)中, 表示矩阵 的转置,是一个|Cs|×|x|大小的矩阵,|x|表示每个批次 喂入识别模型中x的数量,x是所述输入层的输入,y是所述输出层的输出,CS表示源域的类 分布; 是一个 大小的矩阵,表示经过第 个全连接层后获得的x的特征表示, 第 个全连接层中有 个神经元;M是一个 大小的矩阵,该矩阵中每一行代表 具有相同簇的所有特征表示的总和,通过式(6)分别得到源域的特征聚集矩阵Ms和目标域 的特征聚集矩阵MT; 将基于特征自匹配的自适应层连接在源域和目标域之间的第二个全连接层; 计算Ms和MT之间的距离d(Ms,MT),并剔除与目标域类别不匹配的无关源数据,如下 式(7)所示: 7 CN 111738413 A 说 明 书 4/9 页 式(7)中,|xs|和|xt|分别表示源域和目标域中每批次喂入神经网络的时间序列样 本的数量;Ct代表目标域的类分布, 是一个 大小的矩阵,表示源域和 目标域的公共类特征之间的距离,其中不属于目标域类的无关特征被乘以零; 最小化计算得到的距离d(Ms,MT),并且同时最小化源域和目标域的预测误差,则识 别模型的损失函数loss由三部分组成,如下式(8)至式(11)所示: loss=Ls Lt Lc (8) Lc=d(Ms,MT) (11) 式(8)至式(11)中,Ls表示对源域数据错误分类的误差损失,Lt表示对目标域数据 错误分类的误差损失,Lc表示源域和目标域匹配聚类特征之间的距离。 本发明提出了一种基于特征自匹配的深度神经网络方法,该方法通过深度迁移学 习来监测纺纱过程中的能效异常。与传统利用迁移学习进行时间序列异常监测的研究不同 的是,传统方法建立在源域与目标域数据完全匹配的假设前提下,而本发明所提出的方法 自动匹配目标域与源域中的相似类别,同时过滤掉源域中的不匹配类别,以提高监测性能 并减少负迁移。在实际纺纱能效数据上的实验结果表明,所提出的方法表现出更高的准确 性,更少的异常漏报,意味着更大的节能潜力。此方法也可以应用到工况多变的类似工业场 景中,帮助制造企业节能降耗,实现绿色生产。 附图说明 图1是纺纱能效异监测过程; 图2是基于特征自匹配的深度神经网络结构; 图3是方法实现流程图。











