
技术摘要:
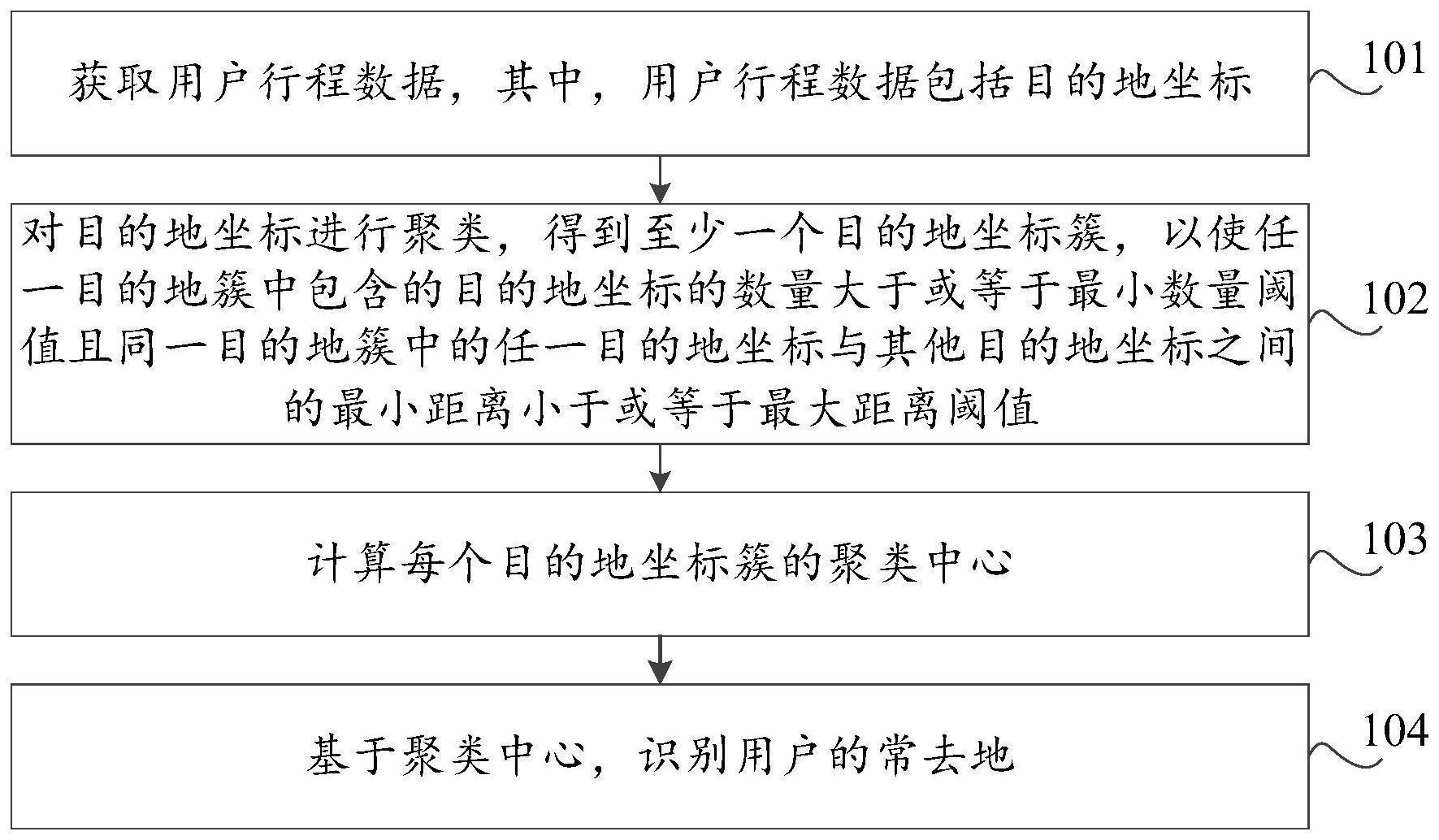
本申请公开了一种基于聚类的常去地识别方法及装置、存储介质、计算机设备,该方法包括:获取用户行程数据,其中,所述用户行程数据包括目的地坐标;对所述目的地坐标进行聚类,得到至少一个目的地坐标簇,以使任一所述目的地簇中包含的目的地坐标的数量大于或等于最小 全部
背景技术:
基于用户APP的GPS定位的数据,分析和推测用户的行为习惯、消费水平和家庭状 况等,进而据此为用户提供更加个性化的服务和推荐,是目前LBS的常规应用方式。包括百 度、阿里和腾讯在内的许多巨头,都在积极运用LBS类型的画像,强化客群的智能运营。在此 过程中,通过处理和分析GPS打点数据识别用户的常去地点,是极其重要的一环。能准确识 别客户的常去地点,对于改善用户画像的精准度,提升业务侧在用户运营方面的效率和满 意度,都有非常积极的作用。 在传统的用户常去地点识别方法中,一般需要先对单个用户的GPS打点区域进行 分块,统计各块内GPS坐标点数量并据此对分块排序,然后取TOPn的块作为用户常去的n个 地点块,最后再取块内中心点作为用户常去点坐标。 传统方法存在明显不足,结果准确性也相当有限:首先,对不同用户的打点区域分 块的粒度难以把握,过细则导致常去地一点多分的情况;过大则容易导致无法区分较近的 多个常去地点。其次,分块边界容易对GPS打点数据造成分割,且对于边界附近坐标点的归 属问题也没有很可靠解决方案,例如,高频打点的用户在常去地的打点数据非常容易被分 块边界影响,导致一个常去地点的GPS打点数据被分割至多个分块,进而造成一点多分。
技术实现要素:
有鉴于此,本申请提供了一种基于聚类的常去地识别方法及装置、存储介质、计算 机设备,得到的常去地与用户个体更加匹配,并且解决了现有技术中区域分块粒度难以把 握的问题。 根据本申请的一个方面,提供了一种基于聚类的常去地识别方法,包括: 获取用户行程数据,其中,所述用户行程数据包括目的地坐标; 对所述目的地坐标进行聚类,得到至少一个目的地坐标簇,以使任一所述目的地 簇中包含的目的地坐标的数量大于或等于最小数量阈值且同一所述目的地簇中的任一目 的地坐标与其他目的地坐标之间的最小距离小于或等于最大距离阈值; 计算每个所述目的地坐标簇的聚类中心; 基于所述聚类中心,识别用户的常去地。 具体地,所述对所述目的地坐标进行聚类,得到至少一个目的地坐标簇,具体包 括: 步骤1,利用全部所述目的地坐标建立目的地坐标集合D,并将所述目的地坐标集 合中的每个所述目的地坐标标记为未被访问; 步骤2,选取一个未被访问的所述目的地坐标p,并将所选取的所述目的地坐标p标 4 CN 111611500 A 说 明 书 2/10 页 记为已被访问; 步骤3,从所述目的地坐标集合中获取所述目的地坐标p的邻域目的地坐标,并统 计所述邻域目的地坐标中的所述目的地坐标的数量,其中,所述邻域目的地坐标与所述目 的地坐标p之间距离可达; 步骤4,若所述数量小于所述最小数量阈值,则将所述目的地坐标p标记为噪声点; 步骤5,若所述数量大于或等于所述最小数量阈值,则根据所述目的地坐标p及其 所述邻域目的地坐标建立候选集合N; 步骤6,建立所述目的地坐标p的目的地坐标簇C,并将所述候选集合N中未被访问 的所述目的地坐标加入所述目的地坐标簇C中; 步骤7,重复上述步骤2至步骤6,直至所述目的地坐标集合D中不包括未被访问的 目的地坐标。 具体地,所述计算每个所述目的地坐标簇的聚类中心,具体包括: 计算任一所述目的地坐标簇中的目的地坐标的平均值,将所述平均值作为所述目 的地坐标簇的聚类中心。 具体地,所述基于所述聚类中心,识别用户的常去地,具体包括: 统计任一所述目的地坐标簇中包含的所述目的地坐标数据的数量; 计算任一所述目的地坐标簇的目的地坐标的数量占所述目的地坐标总数量的第 一比重; 按照所述第一比重以及第一最小比重阈值和/或第一预设常去地数量,从所述聚 类中心中识别出常去地坐标。 具体地,所述基于所述聚类中心,识别用户的常去地之后,所述方法还包括: 输出所述常去地坐标及其对应的所述第一比重。 具体地,所述用户行程数据还包括与所述目的地坐标对应的停留时间;所述对所 述目的地坐标进行聚类,得到至少一个目的地坐标簇,具体包括: 获取停留时间大于或等于最小停留时间阈值的目标目的地坐标; 对所述目标目的地坐标进行聚类,得到至少一个所述目的地坐标簇。 具体地,所述基于所述聚类中心,识别用户的常去地,具体包括: 统计任一所述目的地坐标簇中包含的所述目的地坐标对应的停留时间之和; 计算任一所述目的地坐标簇对应的停留时间之和占所述目标目的地坐标对应的 停留时间总和的第二比重; 按照所述第二比重以及第二最小比重阈值和/或第二预设常去地数量,从所述聚 类中心中识别出常去地坐标。 根据本申请的另一方面,提供了一种基于聚类的常去地识别装置,包括: 行程数据获取模块,用于获取用户行程数据,其中,所述用户行程数据包括目的地 坐标; 目的地聚类模块,用于对所述目的地坐标进行聚类,得到至少一个目的地坐标簇, 以使任一所述目的地簇中包含的目的地坐标的数量大于或等于最小数量阈值且同一所述 目的地簇中的任一目的地坐标与其他目的地坐标之间的最小距离小于或等于最大距离阈 值; 5 CN 111611500 A 说 明 书 3/10 页 聚类中心计算模块,用于计算每个所述目的地坐标簇的聚类中心; 常去地识别模块,用于基于所述聚类中心,识别用户的常去地。 具体地,所述目的地聚类模块,具体包括: 坐标集合建立单元,用于执行步骤1,利用全部所述目的地坐标建立目的地坐标集 合D,并将所述目的地坐标集合中的每个所述目的地坐标标记为未被访问; 坐标选取单元,用于执行步骤2,选取一个未被访问的所述目的地坐标p,并将所选 取的所述目的地坐标p标记为已被访问; 邻域坐标获取单元,用于执行步骤3,从所述目的地坐标集合中获取所述目的地坐 标p的邻域目的地坐标,并统计所述邻域目的地坐标中的所述目的地坐标的数量,其中,所 述邻域目的地坐标与所述目的地坐标p之间距离可达; 噪声点标记单元,用于执行步骤4,若所述数量小于所述最小数量阈值,则将所述 目的地坐标p标记为噪声点; 候选集合建立单元,用于执行步骤5,若所述数量大于或等于所述最小数量阈值, 则根据所述目的地坐标p及其所述邻域目的地坐标建立候选集合N; 坐标簇建立单元,用于执行步骤6,建立所述目的地坐标p的目的地坐标簇C,并将 所述候选集合N中未被访问的所述目的地坐标加入所述目的地坐标簇C中; 聚类单元,用于执行步骤7,重复上述步骤2至步骤6,直至所述目的地坐标集合D中 不包括未被访问的目的地坐标。 具体地,所述聚类中心计算模块,具体用于计算任一所述目的地坐标簇中的目的 地坐标的平均值,将所述平均值作为所述目的地坐标簇的聚类中心。 具体地,所述常去地识别模块,具体包括: 数量统计单元,用于统计任一所述目的地坐标簇中包含的所述目的地坐标数据的 数量; 第一比重计算单元,用于计算任一所述目的地坐标簇的目的地坐标的数量占所述 目的地坐标总数量的第一比重; 第一识别单元,用于按照所述第一比重以及第一最小比重阈值和/或第一预设常 去地数量,从所述聚类中心中识别出常去地坐标。 具体地,所述装置还包括: 常去地输出模块,用于基于所述聚类中心,识别用户的常去地之后,输出所述常去 地坐标及其对应的所述第一比重。 具体地,所述用户行程数据还包括与所述目的地坐标对应的停留时间;所述目的 地聚类模块,具体用于: 获取停留时间大于或等于最小停留时间阈值的目标目的地坐标;以及 对所述目标目的地坐标进行聚类,得到至少一个所述目的地坐标簇。 具体地,所述常去地识别模块,具体包括: 时间统计单元,用于统计任一所述目的地坐标簇中包含的所述目的地坐标对应的 停留时间之和; 第二比重计算单元,用于计算任一所述目的地坐标簇对应的停留时间之和占所述 目标目的地坐标对应的停留时间总和的第二比重; 6 CN 111611500 A 说 明 书 4/10 页 第二识别单元,用于按照所述第二比重以及第二最小比重阈值和/或第二预设常 去地数量,从所述聚类中心中识别出常去地坐标。 依据本申请又一个方面,提供了一种存储介质,其上存储有计算机程序,所述程序 被处理器执行时实现上述基于聚类的常去地识别方法。 依据本申请再一个方面,提供了一种计算机设备,包括存储介质、处理器及存储在 存储介质上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述基于 聚类的常去地识别方法。 借由上述技术方案,本申请提供的一种基于聚类的常去地识别方法及装置、存储 介质、计算机设备,依据用户行程数据中包含的目的地坐标,进行聚类分析,将目的地坐标 划分为目的地坐标簇,使得每个目的地坐标簇中包含不小于最小数量阈值的目的地坐标, 并且同一个目的地坐标簇之间的目的地坐标是可达的,从而保证聚类分析粒度不会过细也 不会过粗,而后,分别求解每个目的地坐标簇的聚类中心,进而从聚类中心中识别出用户的 常去地。本申请实施例与现有技术中基于地图进行区域分块,进而统计各块内的目的地坐 标数量确定用户常去地的方法来说,通过对特定用户的目的地坐标聚类的方式划分坐标 簇,从而基于坐标簇的聚类中心确定用户常去地,所得到的常去地与用户个体更加匹配,并 且解决了现有技术中区域分块粒度难以把握的问题。 上述说明仅是本申请技术方案的概述,为了能够更清楚了解本申请的技术手段, 而可依照说明书的内容予以实施,并且为了让本申请的上述和其它目的、特征和优点能够 更明显易懂,以下特举本申请的











