
技术摘要:
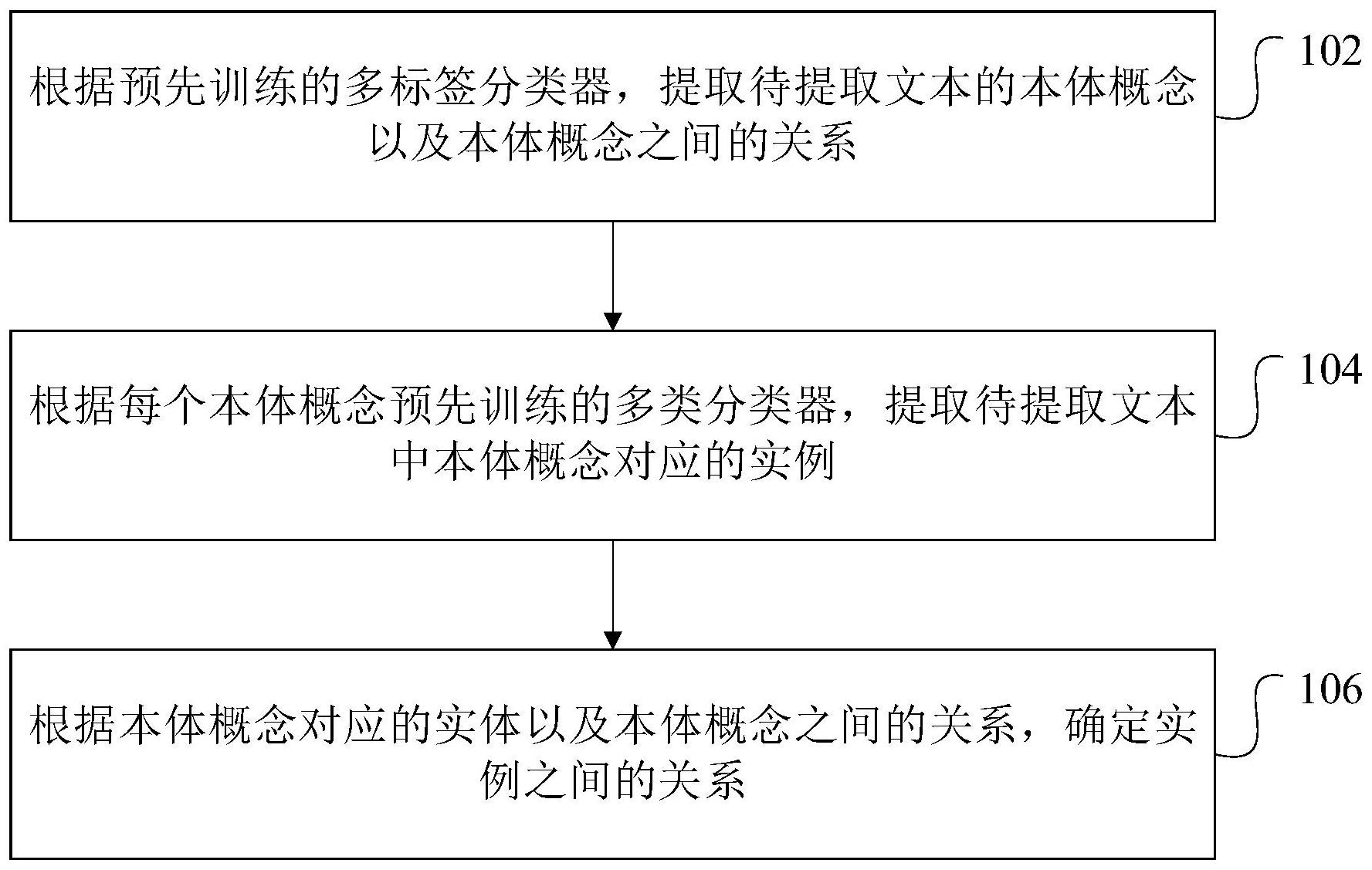
本申请涉及一种网络空间威胁知识抽取方法和装置。所述方法包括:根据预先训练的多标签分类器,提取待提取文本的本体概念以及本体概念之间的关系;根据每个本体概念预先训练的多类分类器,提取待提取文本中本体概念对应的实例;根据本体概念对应的实体以及本体概念之间 全部
背景技术:
全维度、多视角地感知网络空间威胁,特别是智能化、系统性地认知高级可持续威 胁攻击关联的战术、战技、漏洞及产品等,有助于提升国家及企业对网络威胁的科学防御能 力。为了全面认知网络空间威胁,STIX 2.0(结构化威胁信息表达)从攻击模式、攻击活动、 行动等12种构件方面来对网络空间威胁信息进行描述。针对STIX 2.0的结构化语言描述, MITRE公司分别构建了ATT&CK框架(A Globally Accessible Knowledge base of Cyber Adversary Tactics and Techniques)、CAPEC攻击模式(Common Attack Pattern Enumeration and Classification,通用攻击模式枚举和分类)、CWE(Common Weakness Enumeration,通用弱点枚举)等知识库,但是MITRE公司构建的知识库仅包括了约40种战 术、千级规模的技术与弱点、以及百级规模的攻击模式,忽略了网络空间威胁影响的产品和 漏洞等知识;另一方面,互联网中存在大量的开放漏洞库,如美国国家信息安全漏洞库 (NVD)、国家信息安全漏洞共享平台(CNVD)等;同时,网络空间产品大多数被通用平台枚举 (CPE,Common Platform Enumeration)收录。 目前已有的网络空间威胁知识图谱还不能完整描绘“威胁-弱点-资产”等复杂的 关联关系,且存在已收录的知识更新慢、实体关系不全面等问题,因此需要基于网络空间多 源情报数据抽取更加丰富的网络空间威胁知识。 目前已有的类如漏洞库(CVE,Common Vulnerability Enumeration,通用漏洞枚 举)、攻击模式库(CAPEC,Common Attack Pattern Enumeration and Classification,通 用攻击模式枚举和分类)等关联形成的网络空间知识图谱中的实例节点大多数采用统一编 码体系,如CAPEC-ID、CVE-ID等,不具备语义特性。 而维基百科、Freebase、DBpedia等开放知识图谱通常具备语义特性,比如实体“邱 勇”可以直接显式地从非结构化文本中抽取。但是,网络空间威胁知识图谱区别于开放知识 图谱在于实例节点不具备语义特性,而多由编码体系组成,且网络安全威胁报告中通常不 会直接提及具体的攻击模式编号(CAPEC-ID)或者漏洞编号(CVE-ID),而由一段非结构化文 本描述漏洞、攻击模式、以及漏洞与攻击模式的关系。因此,传统的结构化信息抽取技术不 能够很好地适用于网络空间威胁知识图谱的隐实体及关系抽取。
技术实现要素:
基于此,有必要针对上述技术问题,提供一种能够解决传统结构化信息抽取技术 不能够很好地适用于网络空间威胁知识图谱的隐实体及关系抽取问题的网络空间威胁知 识抽取方法和装置。 一种网络空间威胁知识抽取方法,所述方法包括: 4 CN 111597353 A 说 明 书 2/10 页 根据预先训练的多标签分类器,提取待提取文本的本体概念以及所述本体概念之 间的关系; 根据每个所述本体概念预先训练的多类分类器,提取所述待提取文本中本体概念 对应的实例; 根据本体概念对应的实体以及所述本体概念之间的关系,确定所述实例之间的关 系; 其中,根据预先设置的网络空间威胁知识库,获取概念三元组中头概念对应的头 概念ID以及尾概念对应的尾概念ID;从预先设置的开源数据库中搜索同时包含所述头概念 ID和所述尾概念ID的非结构化文本,得到文本训练集以及所述文本训练集中每个元素对应 的标记标签;从所述文本训练集中提取包含目标概念对的非结构化文本,构建目标概念对 对应的多标签分类器的概念训练集,根据所述概念训练集,训练所述多标签分类器;从所述 文本训练集中提取包含目标实例的非结构化文本,构建每个目标实例对应的实例训练集, 根据所述实例训练集,训练每个所述多分类分类器。 在其中一个实施例中,还包括:从预先设置的开源数据库中搜索同时包含所述头 概念ID和所述尾概念ID的非结构化文本,得到文本训练集为: x={D1,D2,…,Dn} 其中,x表示文本训练集,D表示非结构化文本;得到所述文本训练集中每个元素对 应的标记标签为: yi=[Chi,IDhi,Cti,IDti,G] 其中,i=1,2,…,k表示标记标签的总数,Chi表示第i个头概念,IDhi表示第i个头 概念ID,Cti表示第i个尾概念,IDti表示第i个尾概念ID,G表示关系判别式,G={0,1},取当G =0表示头概念ID和尾概念ID不存在关系,取G=1表示表示头概念ID和尾概念ID存在关系。 在其中一个实施例中,还包括:获取目标概念对,从所述文本训练集中提取包含目 标概念对的非结构化文本,构建概念数据集;根据所述标记标签,将概念训练集对应的概念 标签设置为: yj=[Chi,Cti,G]: 根据所述概念数据集和所述概念标签,构建目标概念对对应的多标签分类器的概 念训练集。 在其中一个实施例中,还包括:从所述文本训练集提取包含所述目标概念对中包 括头概念或者尾概念的非结构化文本,构建概念数据负集;根据所述概念数据集、所述概念 数据负集以及所述概念标签,构建目标概念对对应的多标签分类器的概念训练集。 在其中一个实施例中,还包括:从所述文本训练集中提取包含目标实例的非结构 化文本,构建实例数据集;根据所述实例数据集中实例的数量,构建1×n维标签集合为y= [1,1,1,…,1]n 根据所述实例数据集合所述标签集合,构建每个目标实例对应的实例训练集。 在其中一个实施例中,还包括:将待提取文本输入预先训练的多标签分类器的 BERT预训练模型,得到所述待提取文本中上下文相关的词向量;将所述词向量输入多标签 分类器的TextCNN模型,得到所述词向量的语义特征;将所述语义特征输入多标签分类器的 RNN模型,输出待提取文本的本体概念以及所述本体概念之间的关系。 5 CN 111597353 A 说 明 书 3/10 页 在其中一个实施例中,所述多分类器包括多个二分类器;所述多分类器为哑编码 的多分类器;还包括:根据每个所述本体概念预先训练的哑编码的多分类器,提取所述待提 取文本中本体概念对应的实例。 一种网络空间威胁知识抽取装置,所述装置包括: 本体概念提取模块,用于根据预先训练的多标签分类器,提取待提取文本的本体 概念以及所述本体概念之间的关系; 实例提取模块,用于根据每个所述本体概念预先训练的多类分类器,提取所述待 提取文本中本体概念对应的实例; 关系构建模块,用于根据本体概念对应的实体以及所述本体概念之间的关系,确 定所述实例之间的关系; 其中,根据预先设置的网络空间威胁知识库,获取概念三元组中头概念对应的头 概念ID以及尾概念对应的尾概念ID;从预先设置的开源数据库中搜索同时包含所述头概念 ID和所述尾概念ID的非结构化文本,得到文本训练集以及所述文本训练集中每个元素对应 的标记标签;从所述文本训练集中提取包含目标概念对的非结构化文本,构建目标概念对 对应的多标签分类器的概念训练集,根据所述概念训练集,训练所述多标签分类器;从所述 文本训练集中提取包含目标实例的非结构化文本,构建每个目标实例对应的实例训练集, 根据所述实例训练集,训练每个所述多分类分类器。 一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理 器执行所述计算机程序时实现以下步骤: 根据预先训练的多标签分类器,提取待提取文本的本体概念以及所述本体概念之 间的关系; 根据每个所述本体概念预先训练的多类分类器,提取所述待提取文本中本体概念 对应的实例; 根据本体概念对应的实体以及所述本体概念之间的关系,确定所述实例之间的关 系; 其中,根据预先设置的网络空间威胁知识库,获取概念三元组中头概念对应的头 概念ID以及尾概念对应的尾概念ID;从预先设置的开源数据库中搜索同时包含所述头概念 ID和所述尾概念ID的非结构化文本,得到文本训练集以及所述文本训练集中每个元素对应 的标记标签;从所述文本训练集中提取包含目标概念对的非结构化文本,构建目标概念对 对应的多标签分类器的概念训练集,根据所述概念训练集,训练所述多标签分类器;从所述 文本训练集中提取包含目标实例的非结构化文本,构建每个目标实例对应的实例训练集, 根据所述实例训练集,训练每个所述多分类分类器。 一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执 行时实现以下步骤: 根据预先训练的多标签分类器,提取待提取文本的本体概念以及所述本体概念之 间的关系; 根据每个所述本体概念预先训练的多类分类器,提取所述待提取文本中本体概念 对应的实例; 根据本体概念对应的实体以及所述本体概念之间的关系,确定所述实例之间的关 6 CN 111597353 A 说 明 书 4/10 页 系; 其中,根据预先设置的网络空间威胁知识库,获取概念三元组中头概念对应的头 概念ID以及尾概念对应的尾概念ID;从预先设置的开源数据库中搜索同时包含所述头概念 ID和所述尾概念ID的非结构化文本,得到文本训练集以及所述文本训练集中每个元素对应 的标记标签;从所述文本训练集中提取包含目标概念对的非结构化文本,构建目标概念对 对应的多标签分类器的概念训练集,根据所述概念训练集,训练所述多标签分类器;从所述 文本训练集中提取包含目标实例的非结构化文本,构建每个目标实例对应的实例训练集, 根据所述实例训练集,训练每个所述多分类分类器。 上述网络空间威胁知识抽取方法、装置、计算机设备和存储介质,将知识抽取过程 分为两个过程完成,第一个过程是通过多标签分类器,提取出待提取文本中的本体与本体 之间的关系,第二个过程是通过每个本体概念对应的多类分类器,提取待提取文本中本体 概念对应的实例。最后输出时,将本体的关系作为实例之间的关系输出,另外,在两个阶段 模型训练时,通过概念三元组中头概念对应的头概念ID和尾概念对应的尾概念ID,体现出 非结构化文本中的隐实体,并且通过头概念ID和尾概念ID,构建文本训练集以及标记标签, 从而联合隐实体以及本体关系很好的解决了非结构化文本中网络空间威胁知识的抽取。 附图说明 图1为一个实施例中网络空间威胁知识抽取方法的流程示意图; 图2为一个实施例中多标签分类器的示意性结构图; 图3为一个实施例中多分类器的示意性结构图; 图4为一个实施例中知识提取框架图; 图5为一个实施例中组合关系判断步骤的流程示意图; 图6为一个实施例中网络空间威胁知识抽取装置的结构框图; 图7为一个实施例中计算机设备的内部结构图。











