
技术摘要:
本发明公开了一种密度峰值聚类算法的簇中心的选取方法以及设备,本方法首先选取多个截断距离,并根据多组截断距离计算出对应的多组簇中心,然后为选定的簇中心执行邻近簇迭代合并过程,使簇数量逐渐接近真实值,当合并后的簇数量不变,则以选定的簇中心作为最终的簇中 全部
背景技术:
聚类算法作为一种无监督学习,在数据集先验参数不足时,仍可将数据集划分为 若干簇,因此被广泛应用于图像分割、生物信息、模式识别、信息检索、数据挖掘等领域。 经典的聚类算法主要有基于划分的K-means、Fuzzy K-means,基于层次的AGNES、 BIRCH与CURE,基于密度的DBSCAN与OPTICS,基于网格的STING,基于统计的CMM。其中,基于 划分的K-means与Fuzzy K-means对初始聚类中心的选取极其敏感,且需先验地设置簇个数 K;基于层次的聚类算法不仅需要预先确定数据集中簇个数K,而且对簇间距离度量公式的 选择十分敏感;基于密度的DBSCAN、OPTICS以及基于网格的聚类算法,自动确定簇个数但均 需对预设参数epsilon和minpts进行大量调整,以获取较优聚类结果,且这两类算法在簇边 界处生成噪声;基于统计的CMM需选取一个或多个合适的概率模型以拟合数据集。 2014年发表在《Science》中的密度峰值聚类算法,通过确定合适阈值(截断距离, 简称为dc),人工选取各簇中心,对比传统聚类算法具有高效查找聚类中心、参数少、无迭 代、边界无噪声等优点,而被广泛应用于图像识别、计算机视觉、文本挖掘等领域。但目前密 度峰值聚类算法的簇中心主要是通过人工选取,人工选取簇中心无法满足时效性要求高的 真实系统,而且簇真实数量较大时,人工选取簇中心操作困难。
技术实现要素:
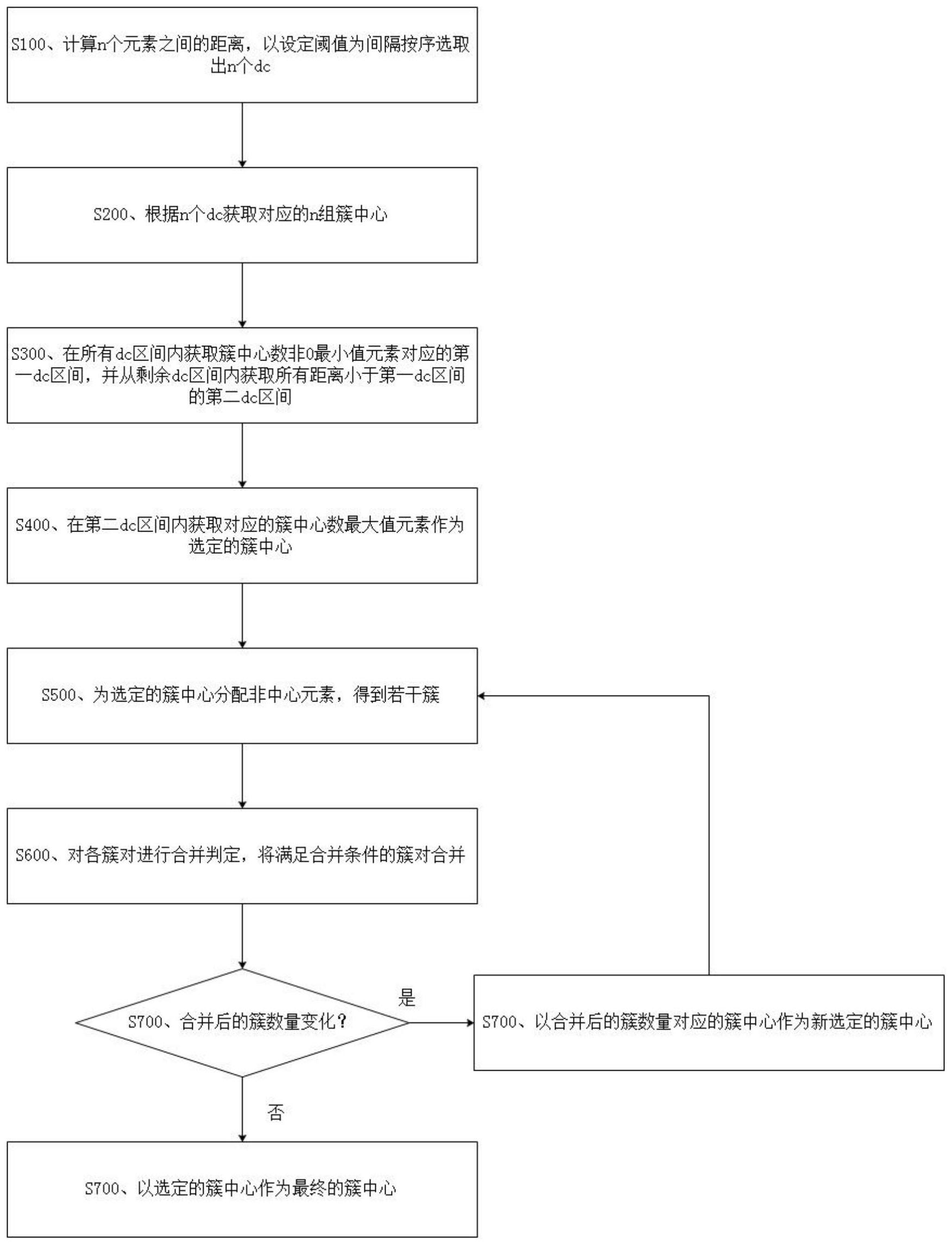
本发明旨在至少解决现有技术中存在的技术问题之一。为此,本发明提出一种密 度峰值聚类算法的簇中心的选取方法,包括以下步骤: S100、计算n个元素之间的距离,以设定阈值为间隔按序选取出n个dc; S200、根据所述n个dc获取对应的n组簇中心; S300、在所有dc区间内获取簇中心数非0最小值元素对应的第一dc区间,并从剩余 dc区间内获取所有距离小于所述第一dc区间的第二dc区间; S400、在所述第二dc区间内获取对应的簇中心数最大值元素作为选定的簇中心; S500、为选定的簇中心分配非中心元素,得到若干簇; S600、对各簇对进行合并判定,将满足合并条件的簇对合并; S700、若合并后的簇数量不变,则以选定的簇中心作为最终的簇中心;若合并后的 簇数量发生变化,则以合并后的簇数量对应的簇中心作为新选定的簇中心,跳转至步骤 S500。 根据本发明的一些实施例,所述对各簇对进行合并判定,将满足合并条件的簇对 合并,包括以下步骤: S601、获取每一簇对之间的无邻簇边界与有邻簇边界,根据所述无邻簇边界和所 3 CN 111582326 A 说 明 书 2/7 页 述有邻簇边界计算每一簇对的合并阈值; S602、若在每一簇对的所述有邻簇边界中,均存在有密度大于所述合并阈值的元 素,则将两簇合并。 根据本发明的一些实施例,所述根据所述n个dc获取对应的n组簇中心,包括以下 步骤: S201、计算所述n个dc对应的n组元素决策值; S202、计算n组所述元素决策值的均值与标准差之和,将各组的所述元素决策值大 于所述均值与标准差之和的元素选作各组的簇中心。 根据本发明的一些实施例,所述计算n个元素之间的距离,包括: 计算n个元素之间的欧式距离,或计算n个元素之间的杰卡德距离,或计算n个元素 之间的柯西相似性。 本发明提供了一种密度峰值聚类算法的簇中心的选取设备,包括:至少一个控制 处理器和用于与所述至少一个控制处理器通信连接的存储器;所述存储器存储有可被所述 至少一个控制处理器执行的指令,所述指令被所述至少一个控制处理器执行,以使所述至 少一个控制处理器能够执行如上述的一种密度峰值聚类算法的簇中心的选取方法。 本发明提供了一种计算机可读存储介质,其特征在于,所述计算机可读存储介质 存储有计算机可执行指令,所述计算机可执行指令用于使计算机执行如上述的一种密度峰 值聚类算法的簇中心的选取方法。 根据本发明的实施例,至少具有如下技术效果: 本实施例提供的方法,首先选取多个截断距离,并根据多个截断距离计算出对应 的多组簇中心,然后为选定的簇中心执行邻近簇迭代合并过程,使簇数量逐渐接近真实值, 当合并后的簇数量不变,则以选定的簇中心作为最终的簇中心,当合并后的簇数量发生变 化,则以合并后簇数量对应的簇中心作为新选定的簇中心,再进行合并迭代过程,直至合并 后的簇数量不变,得到最终的簇中心。本方法无需人工选取簇中心,能够实现自动确定合适 的簇中心。 本发明还提供了一种密度峰值聚类算法的簇中心的选取设备以及存储介质,实现 的有益效果与上述方法的有益效果相同。 本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变 得明显,或通过本发明的实践了解到。 附图说明 本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得 明显和容易理解,其中: 图1为本发明实施例提供的一种密度峰值聚类算法的簇中心的选取方法的流程示 意图; 图2为图1中步骤S200的进一步流程示意图; 图3为图1中步骤S600的进一步流程示意图; 图4为本发明实施例提供的Aggregation数据集的二维分布示意图; 图5为本发明实施例提供的dc与中心个数的关系示意图; 4 CN 111582326 A 说 明 书 3/7 页 图6为本发明实施例提供的通过本方法选取的Aggregation数据集各簇中心与聚 类结果的示意图; 图7为本发明实施例提供的一种密度峰值聚类算法的簇中心的选取设备的结构示 意图。











