
技术摘要:
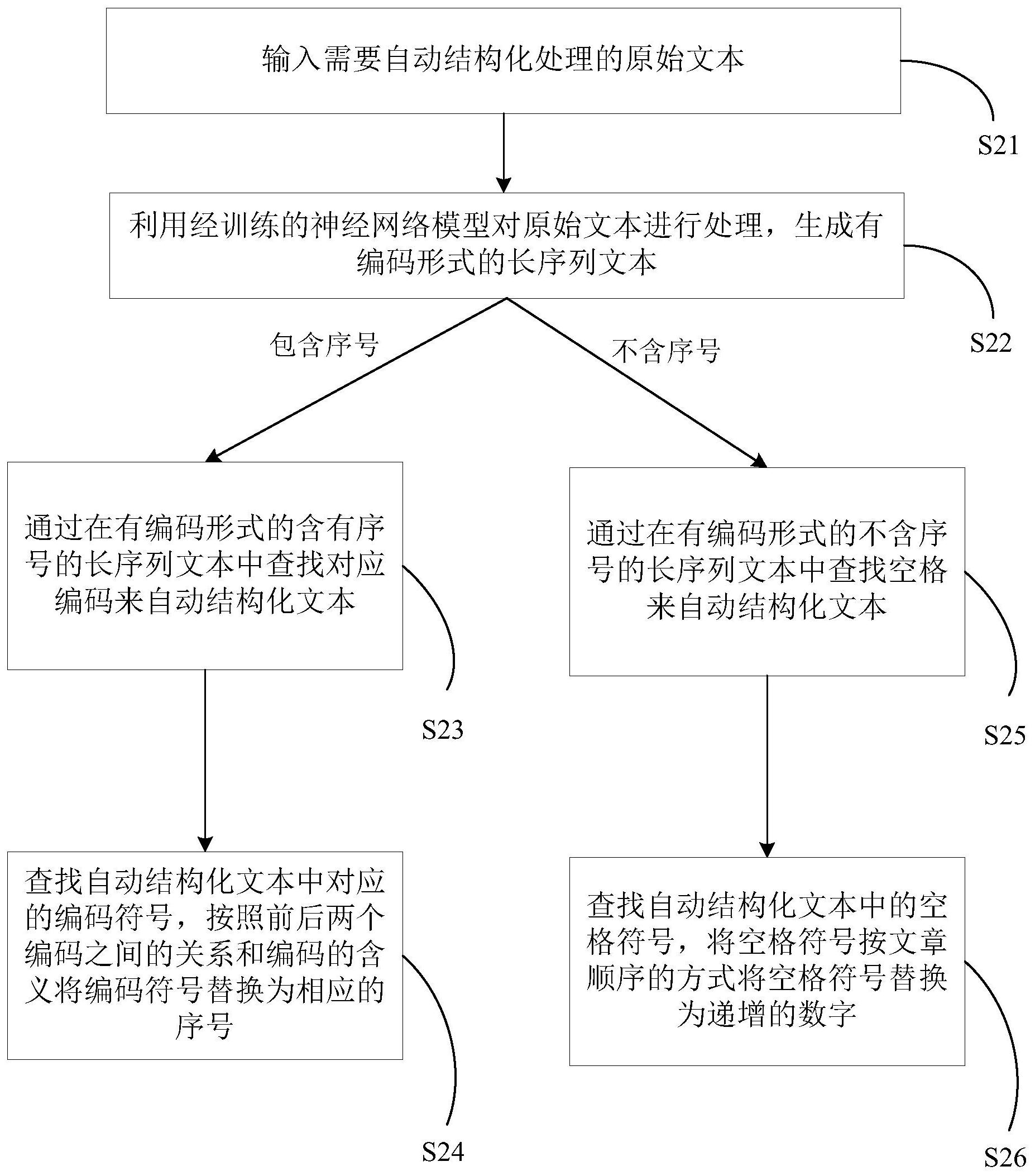
本发明公开了一种基于自然语言处理的文本自动结构化方法和系统,能够将文本文档的内容(包括文档自带序号标注错误甚至文档没有自带序号)进行自动结构化处理以转化成结构化的知识体系。其技术方案为:输入需要自动结构化处理的原始文本;利用经训练的神经网络模型对原始 全部
背景技术:
以结构化的知识体系为基础的知识分享平台或者学习系统是目前的主流方案。而 诸如电子书、文章、报告等文本文档的内容文字并不是以结构化方式来组织的。 目前也有一些将普通的文本文档自动结构化的方法,但这些方法只能应用于原本 就在文本中标注有序号的文档。这会带来两个问题,其一是文本文档在利用自身自带序号 进行自动结构化时,如果遇到手误标错的序号,则自动结构化处理就无法顺利展开;其二是 对于逻辑结构清晰但并没有自带标注序号的文本文档,现有的自动结构化的方法无法将文 档内容结构化。
技术实现要素:
以下给出一个或多个方面的简要概述以提供对这些方面的基本理解。此概述不是 所有构想到的方面的详尽综览,并且既非旨在指认出所有方面的关键性或决定性要素亦非 试图界定任何或所有方面的范围。其唯一的目的是要以简化形式给出一个或多个方面的一 些概念以为稍后给出的更加详细的描述之序。 本发明的目的在于解决上述问题,提供了一种基于自然语言处理的文本自动结构 化方法和系统,能够将文本文档的内容(包括文档自带序号标注错误甚至文档没有自带序 号)进行自动结构化处理以转化成结构化的知识体系。 本发明的技术方案为:本发明揭示了一种基于自然语言处理的文本自动结构化方 法,包括: 输入需要自动结构化处理的原始文本; 利用经训练的神经网络模型对原始文本进行处理,生成有编码形式的长序列文 本; 通过在有编码形式的含有序号的长序列文本中查找对应编码来自动结构化文本; 查找自动结构化文本中对应的编码符号,按照前后两个编码之间的关系和编码的 含义将编码符号替换为相应的序号。 根据本发明的基于自然语言处理的文本自动结构化方法的一实施例,有编码形式 的长序列文本中包含的序号包括正确的序号和错误的序号。 根据本发明的基于自然语言处理的文本自动结构化方法的一实施例,方法还包 括: 通过在有编码形式的不含序号的长序列文本中查找空格来自动结构化文本; 查找自动结构化文本中的空格符号,将空格符号按文章顺序的方式将空格符号替 换为递增的数字。 4 CN 111597801 A 说 明 书 2/10 页 根据本发明的基于自然语言处理的文本自动结构化方法的一实施例,神经网络模 型的训练过程包括: 收集样本数据; 对收集到的样本数据进行数据标注; 对经标注的数据进行数据清洗和预处理,得到无编码形式的长序列样本作为神经 网络模型训练的输入; 搭建PyTorch框架; 建立神经网络模型,神经网络模型中包含指示不同层级标题序号之间的关系的编 码规则; 利用无编码形式的长序列样本训练神经网络模型; 对神经网络模型进行测试与优化; 确定神经网络模型。 根据本发明的基于自然语言处理的文本自动结构化方法的一实施例,神经网络模 型是seq2seq模型,seq2seq模型结构中的编码器将所有的输入序列都编码成一个统一的语 义向量,再由解码器进行解码,解码过程中不断将前一个时刻解的输出作为后一个时刻的 输入,循环编码直至输出停止符为止。 本发明还揭示了一种基于自然语言处理的文本自动结构化系统,包括: 文本输入模块,输入需要自动结构化处理的原始文本; 模型处理模块,利用经训练的神经网络模型对原始文本进行处理,生成有编码形 式的长序列文本; 编码查找模块,通过在有编码形式的含有序号的长序列文本中查找对应编码来自 动结构化文本; 编码替换模块,查找自动结构化文本中对应的编码符号,按照前后两个编码之间 的关系和编码的含义将编码符号替换为相应的序号。 根据本发明的基于自然语言处理的文本自动结构化系统的一实施例,有编码形式 的长序列文本中包含的序号包括正确的序号和错误的序号。 根据本发明的基于自然语言处理的文本自动结构化系统的一实施例,系统还包 括: 空格查找模块,通过在有编码形式的不含序号的长序列文本中查找空格来自动结 构化文本; 空格替换模块,查找自动结构化文本中的空格符号,将空格符号按文章顺序的方 式将空格符号替换为递增的数字。 根据本发明的基于自然语言处理的文本自动结构化系统的一实施例,模型处理模 块中包括模型训练子模块,其中模型训练子模块进一步包括: 样本收集单元,收集样本数据; 数据标注单元,对收集到的样本数据进行数据标注; 数据清洗和预处理单元,对经标注的数据进行数据清洗和预处理,得到无编码形 式的长序列样本作为神经网络模型训练的输入; 框架搭建单元,搭建PyTorch框架; 5 CN 111597801 A 说 明 书 3/10 页 模型建立单元,建立神经网络模型,神经网络模型中包含指示不同层级标题序号 之间的关系的编码规则; 模型训练单元,利用无编码形式的长序列样本训练神经网络模型; 模型测试与优化单元,对神经网络模型进行测试与优化; 模型确定单元,确定神经网络模型。 根据本发明的基于自然语言处理的文本自动结构化系统的一实施例,神经网络模 型是seq2seq模型,seq2seq模型结构中的编码器将所有的输入序列都编码成一个统一的语 义向量,再由解码器进行解码,解码过程中不断将前一个时刻解的输出作为后一个时刻的 输入,循环编码直至输出停止符为止。 本发明还揭示了一种基于自然语言处理的文本自动结构化系统,包括: 处理器;以及 存储器,所述存储器被配置为存储一系列计算机可执行的指令以及与所述一系列 计算机可执行的指令相关联的计算机可访问的数据, 其中,当所述一系列计算机可执行的指令被所述处理器执行时,使得所述处理器 进行如前所述的方法。 本发明还揭示了一种非临时性计算机可读存储介质,其特征在于,所述非临时性 计算机可读存储介质上存储有一系列计算机可执行的指令,当所述一系列可执行的指令被 计算装置执行时,使得计算装置进行如前所述的方法。 本发明对比现有技术有如下的有益效果:本发明利用pytorch框架,基于自然语言 处理领域中的seq2seq模型,利用循环神经网络进行模型训练。然后将训练得到的模型进行 文本自动结构化处理,可以将文本文档的内容(包括文档自带序号标注错误甚至文档没有 自带序号)进行自动结构化处理以转化成结构化的知识体系。 附图说明 在结合以下附图阅读本公开的实施例的详细描述之后,能够更好地理解本发明的 上述特征和优点。在附图中,各组件不一定是按比例绘制,并且具有类似的相关特性或特征 的组件可能具有相同或相近的附图标记。 图1示出了本发明的基于自然语言处理的文本自动结构化方法的第一实施例的流 程图。 图2示出了本发明的基于自然语言处理的文本自动结构化方法的第二实施例的流 程图。 图3示出了图1和图2所示的方法实施例中的模型训练过程的流程图。 图4示出了本发明的基于自然语言处理的文本自动结构化系统的第一实施例的原 理图。 图5示出了本发明的基于自然语言处理的文本自动结构化系统的第二实施例的原 理图。 图6示出了图3和图4所示的系统实施例中的模型训练子模块的细化原理图。 图7示出了seq2seq模型结构的简单原理示意图。 6 CN 111597801 A 说 明 书 4/10 页











