
技术摘要:
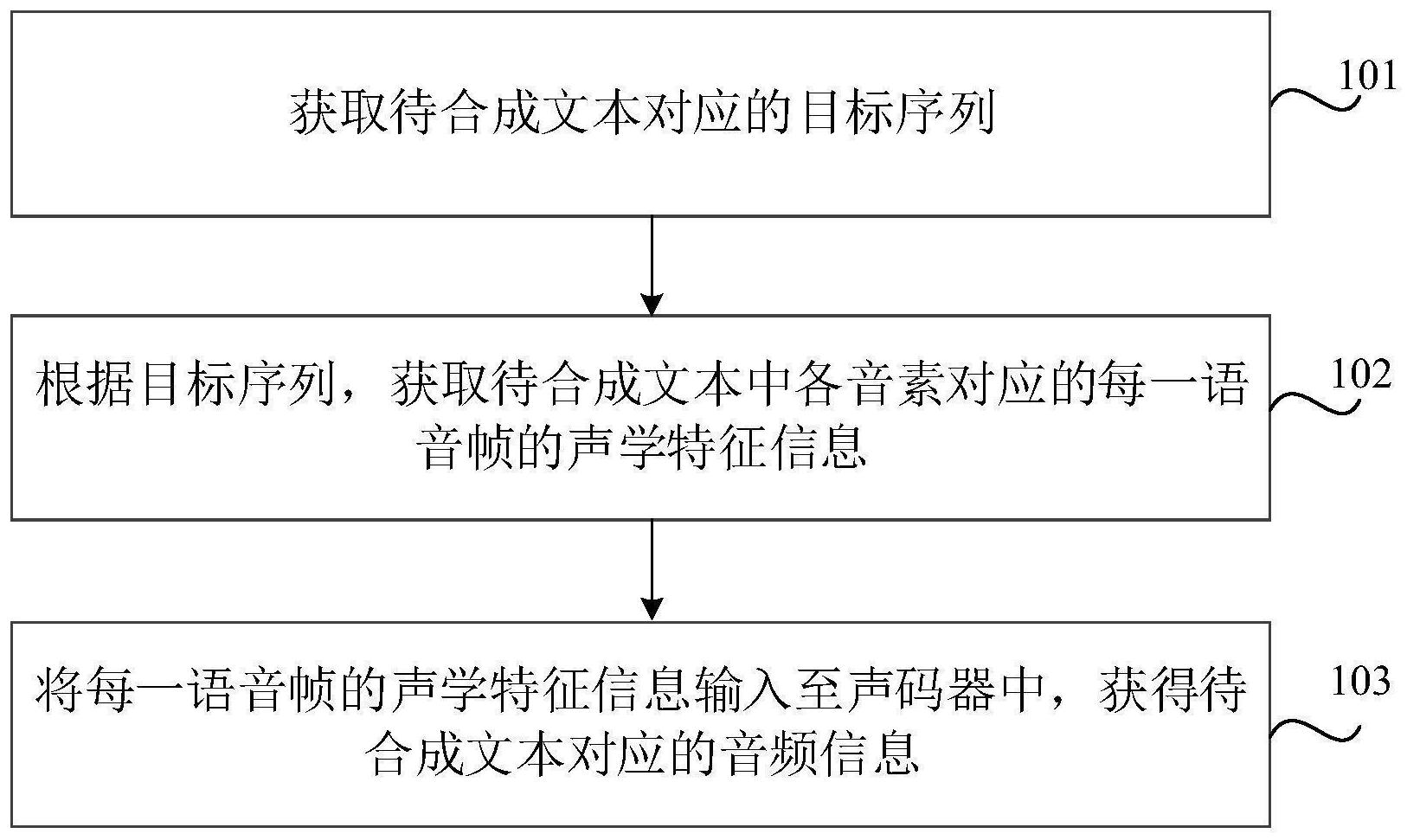
本公开涉及一种语音合成方法、装置、存储介质及电子设备。方法包括:获取待合成文本对应的目标序列,其中,目标序列由待合成文本中各音素对应的第一子序列按照相应音素在待合成文本中的先后顺序排列而成,音素对应的第一子序列中的各元素均为该音素的编码,第一子序列 全部
背景技术:
现阶段通常采用端到端的语音合成模型(例如,Tacotron2)进行语音合成,该模型 主要包括用于预测待合成文本的声学特征(例如,梅尔频谱)的声学模型和用于根据声学模 型预测的声学特征进行语音合成的声码器。其中,声学模型包括编码网络、注意力网络和解 码网络,其中,编码网络根据待合成文本,得到相应的表示序列,之后,注意力网络和解码网 络根据该表示序列生成对应的声学特征。由于解码网络是自回归模型,它基于表示序列自 回归(下一帧的输出结果依赖于历史输出结果)得到最终的输出(即声学特征),因此,输出 声学特征的长度与表示序列的长度不一致,即声学特征与表示序列并不是一一对应的,这 样,可能会出现丢字、重复、错发音的情况,使得语音合成的准确度和稳定性受到影响。
技术实现要素:
提供该部分内容以便以简要的形式介绍构思,这些构思将在后面的











