
技术摘要:
本发明公开了一种基于空时特征的视频行为分类方法,涉及视频识别技术领域,其构建的双通道网络结构包括空间特征提取网络、时间特征提取网络、特征融合网络以及softmax网络,空间特征提取网络与时间特征提取网络并联后,与特征融合网络和softmax网络依次串联,所述空间 全部
背景技术:
目前,视频行为分类方法主要包括基于多通道的视频行为分类方法和基于三维卷 积的视频行为分类方法。 基于多通道的视频行为分类方法主要以two stream模型为典型代表,该模型主要 包括三个部分:以提取空间特征为主要任务的空间流,以提取运动信息为主要特征的时间 流以及融合两部分特征的融合层。空间流将视频的RGB帧作为输入,利用卷积神经网络的多 层网络结构,局部特征提取,逐层提取深度语义信息和特征选择等特点提取输入的RGB帧中 所包含的物品信息。时间流将连续的光流作为输入,利用二维卷积核将对连续的光流进行 特征提取,提取出光流中可能存在的动作特征,利用产生的运动特征进行视频行为分类。融 合层主要是将空间流生成的空间特征和时间流生成的动作特征寻找合适的权重进行融合, 最终对视频进行行为分类,生成对应的行为得分,将最高的得分类别作为输出类别。 基于多通道的视频行为分类方法存在以下缺陷: 1)使用原始的VGG网络提取光流特征,其无法充分的提取光流特征。 2)使用传统的光流计算方法,由于传统的光流计算方法不仅需要巨大的计算力而 且还需要大量的时间,导致基于多通道的模型速度受到光流计算方法的速度限制低于 14fps。 基于三维卷积的视频行为分类方法是使用三维卷积核对视频行为分类,如C3D网 络,其使用8个卷积层逐步提取视频中空间特征和时间特征,再使用8个卷积层来减少特征 的维度,减少计算量,最后使用两个全连接层和softmax层来综合空时特征进行分类。网络 中所使用的的所有三维卷积核都是3x3x3的大小,在时间维度和空间维度上的步长都是1。 每个框中表示过滤器的数量,从pool1到pool5的池化层都是三维池化层,除了pool1的池化 核大小为1x2x2之外所有的池化核的尺寸都是2x2x2。在网络中,所有的全连接层的神经元 都为4096个。C3D通过三维卷积可以直接对视频进行行为分类,这使它的速度大大提升,可 以达到600帧每秒,并且准确率在UCF101上可以达到85.2%。 基于三维卷积的视频行为分类方法存在以下缺陷: 由于3D卷积操作相对于原始的二维卷积多出了一个维度,因此C3D参数量规模相 比于传统的基于二维卷积的模型更大,对于数据集要求更加的严格,需要大量的数据来训 练网络,这将花费更多计算力和计算时间。
技术实现要素:
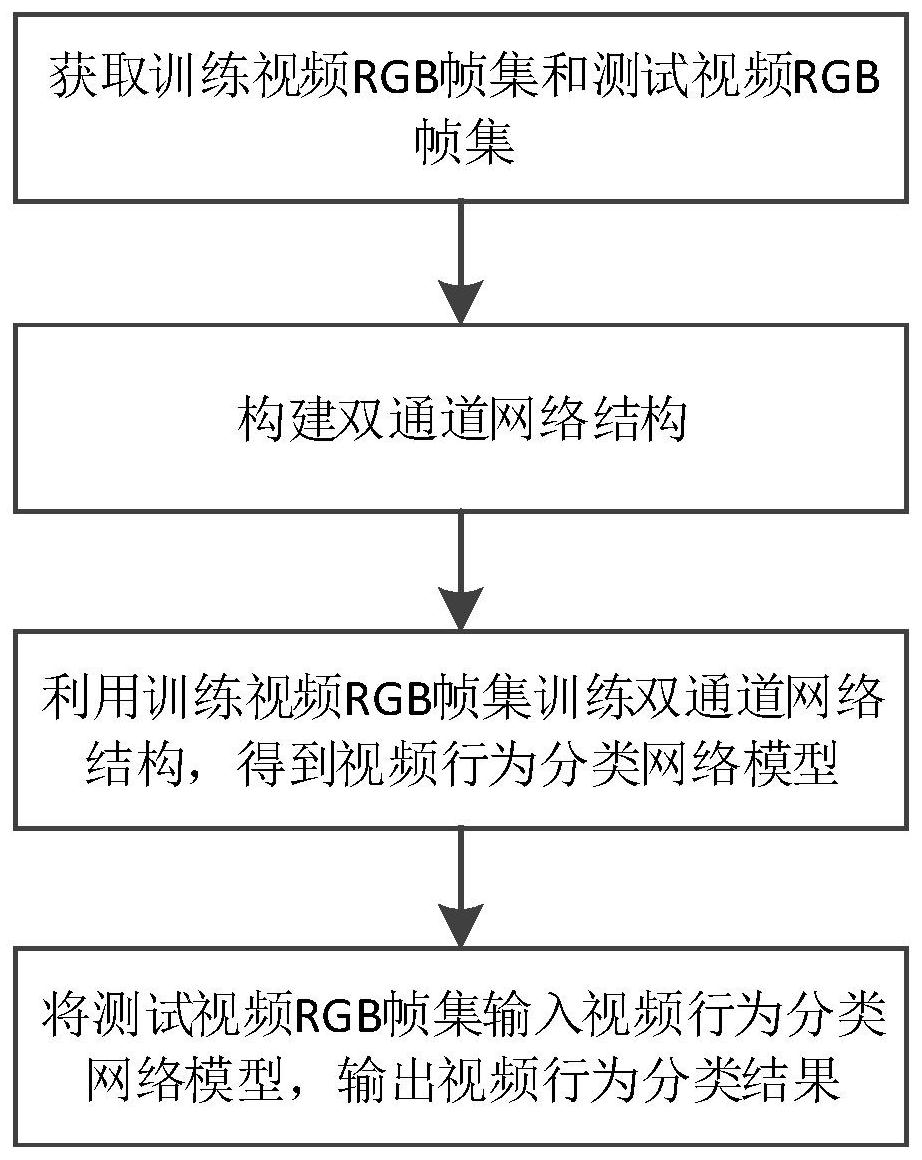
本发明在于提供一种基于空时特征的视频行为分类方法,其能够缓解上述问题。 为了缓解上述的问题,本发明采取的技术方案如下: 4 CN 111582230 A 说 明 书 2/12 页 一种基于空时特征的视频行为分类方法,包括: S1、获取视频数据集,将其分成训练集和测试集,对训练集进行预处理后从中提取 得到训练视频RGB帧集,对测试集进行预处理后从中提取测试视频RGB帧集; S2、构建双通道网络结构,其包括空间特征提取网络、时间特征提取网络、特征融 合网络以及softmax网络,空间特征提取网络与时间特征提取网络并联后,与特征融合网络 和softmax网络依次串联,所述空间特征提取网络为inception网络,所述时间特征提取网 络包括依次串联的Motionnet网络、带OFF子网络的inception网络,所述Motionnet网络包 括下采样网络和上采样网络,所述下采样网络包括若干卷积层,所述上采样网络包括若干 反卷积层; S3、利用训练视频RGB帧集训练若干轮双通道网络结构,每轮训练过程中所采用的 训练视频RGB帧不相同,保存最后一轮得到的网络结构参数,得到视频行为分类网络模型; S4、将测试视频RGB帧集输入所述视频行为分类网络模型,输出视频行为分类结 果。 本技术方案的技术效果是:使用新的神经网络MotionNet代替传统的光流计算方 法,大幅度提高时间流的光流提取速度;将OFF子网络加入到原本处理光流特征的 inception网络中,进一步提取特征,能更充足的提取光流特征。通过特征融合网络将空间 特征和时间特征融合后,利用空时特征进行视频分类,提高了视频分类正确率。 进一步地,所述步骤S1中,预处理包括:使用拉伸或者压缩方法将视频RGB帧大小 处理为224x224。 本技术方案的技术效果是:保证输入大小与网络输入大小一致。 进一步地,对于双通道网络结构的每一轮训练,其训练过程包括: 将训练视频RGB帧输入空间特征提取网络,提取得到行为空间特征; 将训练视频RGB帧输入Motionnet网络,计算得到光流; 将计算得到的光流输入到带OFF子网络的inception网络中,提取得到行为光流特 征; 利用特征融合网络,将行为空间特征和行为光流特征进行加权融合,得到空时特 征; 将空时特征输入softmax网络中,得到训练分类结果,根据训练分类结果和训练视 频RGB帧,对空间特征提取网络、时间特征提取网络、特征融合网络以及softmax网络进行梯 度更新。 本技术方案的技术效果是:可以充分的迭代网络参数,让网络可以学习到正确的 空时特征提取方式。 更进一步地,所述行为空间特征的提取方法具体为: 将训练视频RGB帧分成多段; 对于每段训练视频RGB帧,将其第一帧输入空间特征提取网络提取空间特征; 将从各段训练视频RGB帧提取到的空间特征进行融合,得到所述行为空间特征。 本技术方案的技术效果是:分段采样可以减少视频输入的数据量,并且增强网络 对视频整体的理解。 更进一步地,所述Motionnet网络的下采样网络包括6个卷积层,上采样网络包括5 5 CN 111582230 A 说 明 书 3/12 页 个反卷积层,所述训练视频RGB帧的帧数量为11。 本技术方案的技术效果是:能先对RGB中的空间特征进行提取深层语义信息,再分 析其语义信息更好的计算出光流。 更进一步地,所述Motionnet网络包括三个损失函数,各损失函数的权重值不同, 且该三个损失函数插入所述MotionNet网络的最后一层,且分别为针对重构后的两帧图像 之间的像素级错误而生成的损失函数、平滑度损失函数和结构相似损失函数。 本技术方案的技术效果是:可以使Motionnet网络能够更加全面准确和高效的生 成光流。 更进一步地,所述针对重构后的两帧图像之间的像素级错误而生成的损失函数如 下: 其中,vx和vy分别是光流中x和y方向的速度,n是输入的视频RGB帧。 本技术方案的技术效果是:其中使用了凸误差函数减少异常值的影响,可以帮助 神经网络在细节上更正错误,针对像素级的差异进行调节,使生成的光流更加的逼近与原 本的真实的光流。 更进一步地,所述平滑度损失函数如下: 其中,Lam代表平滑度损失函数, 分别代表光流中x方向对于x,y方向上的 变化量, 分别代表光流中y方向上对于x,y方向上的变化量。 本技术方案的技术效果是:不会出现孔径问题。 更进一步地,所述结构相似损失函数如下: 其中,I1代表真实图像,I′1代表计算出的图像,SSIM函数如下: SSIM(x,y)=(l(x,y))α (c(x,y))β (s(x,y))γ 其中x,y分别指代两张图片,并且α>0,β>0,γ>0,其中l(x,y)是亮度比较,c(x, y)是对比度比较,s(x,y)是结构比较, 其中,u_x和u_y分别代表x,y的平均值,σx和σy分别代表x,y的标准差,σxy代表x,y 的协方差,c1,c2,c3分别代表常数。 本技术方案的技术效果是:SSIM函数可以帮助网络学习全面的结构而不是只局限 6 CN 111582230 A 说 明 书 4/12 页 于局部的相似。 更进一步地,所述步骤S3中,双通道网络结构的训练次数为15000次。 本技术方案的技术效果是:使用较大额训练次数可以缓慢的寻找到网络的参数的 最优值,确定网络学习到正确的特征。 为使本发明的上述目的、特征和优点能更明显易懂,下文特举本发明实施例,并配 合所附附图,作详细说明如下。 附图说明 为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附 图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对 范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这 些附图获得其他相关的附图。 图1是实施例中所述基于空时特征的视频行为分类方法流程图; 图2是实施例中所述Motionnet网络的结构示意图; 图3是实施例中所述双通道网络结构的示意图; 图4是实施例中所述空间特征提取网络的结构示意图; 图5是实施例中所述特征融合网络的结构示意图。











