
技术摘要:
本发明涉及一种基于Hadoop平台的大数据语音分类方法,包括以下步骤:步骤1、进行语音库的构建;步骤2、在此语音库基础上,基于Hadoop平台,采用Map函数对大数据语音分类问题进行细分,用多节点并行、分布式地对子问题进行语音分类求解,得到相应的语音分类结果;步骤3 全部
背景技术:
(1)运动性构音障碍研究现状: 运动性构音障碍(dysarthria)是指由于中枢神经系统或周围神经系统损害导致,肌肉 的控制紊乱而形成的一组言语障碍。运动性构音障碍常表现为言语相关肌肉组织运动减 慢、减弱、不精确、不协调,也可能影响到呼吸、共鸣、喉发声的控制、构音和韵律,临床上常 简称为构音障碍。运动性构音障碍常见病因包括脑外伤、脑瘫、肌萎缩性侧索硬化、多发性 硬化、脑卒中、帕金森病、脊髓小脑共济失调等。构音障碍根据神经解剖和言语声学特点可 以分为弛缓型、痉挛型、失调型、运动过弱型、运动过强型和混合型。在与脑损伤相关的交流 障碍中, 构音障碍发病率高达54%。目前临床可以通过对嗓音、共鸣、韵律等方面的检查可 从主观和客观两个方面反应构音障碍的言语声学特点,有利于提供针对性的治疗和全面科 学地阐明构音障碍的言语声学病理机制。 对于运动性构音障碍总体的发病率国内外研究报道均较少,Miller等对125例帕 金森病患者研究显示,有69.6%的患者的言语清晰度均值比正常对照组低,其中51.2%的患 者低一个标准差,表明在帕金森患者中构音障碍的发病率较高。Bogousslavsky等对1000例 初次卒中患者进行筛选,发现有言语障碍的患者高达46%,其中12.4%确诊为构音障碍患者。 Hartelius等研究也发现多发性硬化患者中构音障碍发病率为51%。由此可见构音障碍的发 病率较高。构音障碍的评定,目前国内尚无统一的评定方法,运动性构音障碍更无专门评定 标准,多数采用Frenchay构音障碍评价法或改良法和中国康复研究中心构音障碍检查表, 由临床医师或康复科医师检查、评分、记录、评价构音障碍程度、类型。 (2)国内语音库研究现状: 随着信息技术与计算机科学的发展,语音技术使机器行为与人类自然语言的交互成为 可能,不论是语音合成、语音识别还是语音辨认研究,都必定依靠于后端优秀语音语料库的 建设。目前国外语音库的发展较为成熟,中国的语音库研究也已在近十几年间突飞猛进,语 音库的研究与建立已在不同的语言和文化语境中落地。但是针对运动性构音障碍语音库的 建设目前还处于研究状态。 国内的构音语音功能评估研究主要集中在主观评估方面,而且只有少数的研究者 将构音与语音的概念有所区分。黄昭鸣等提出了《汉语构音能力测验词表》,该词表包含50 个字,言语康复师通过评价被试的50个字的构音语音,能够全面评价被试对21个声母和4种 声调的构音能力,同时,通过18项音位对比、37个最小语音对来评估被试的音位对比能力。 陈三定等人对50名聋儿进行了汉语普通话声母、韵母和声调的评价,揭示了说汉语普通话 的聋儿构音语音的发展规律,还进一步提出了及早、顺序、容错和巩固”的言语康复教育原 则。华东师范大学的张晶博士研究了听障儿童在个辅音构音时的主要错误走向,分析成因, 并相应的提出了听障儿童辅音音位治疗框架。 4 CN 111583914 A 说 明 书 2/7 页 (3)大数据在医疗领域研究现状: 目前,对大数据定义比较流行的是:超过典型数据库软件工具所能撷取、储存、处理和 分析能力的资料。大数据区别于超大规模数据、海量数据等传统数据概念,其具有四个基本 特征:大量、多样、时效、价值。国务院在《关于积极推进“互联网+”行动的指导意见》指出, 大力发展以互联网为载体,线上线下互动的新兴模式,加快发展互联网的医疗健康等新兴 业务。Kayyali B等研究了大数据在美国医疗行业的影响,指出随着时间推移,大数据对医 疗行业的价值将越来越显著。目前医疗领域内的大数据主要来自制药企业,临床诊断数据, 患者就医数据,健康管理、社交网络数据。例如药物研发是一个相对密集的过程,即使对中 小型企业而言,一项药物研发的数据也在TB以上;医院的数据每天增长也非常快,一个病人 的双源CT检查一次成像在3000张,大概产生1.5GB影像资料,一个标准病理检查图像有将近 5GB图像,加上患者就医、电子病历等数据,每天都在快速增长。基于海量大数据分析的研究 方法引发了人们对于科学方法论的思考。研究无需直接接触研究对象,而通过直接分析和 挖掘海量数据便可获得新的研究发现,这或许催生了一种新的科研模式。 语音语料库的建立是一个繁琐复杂的问题,对于语音语料库的后期完善还有待改 进的问题,例如充分利用现有的词间变调规则,尽量体现变调和轻声的实际情况。对于语料 的不足,可以在预处理环节提高现有语料利用率。鉴于以上原因,语音库应采取开放型数据 库,以便可以随时添加、修改,以便完善该数据库。由于语音情况不尽相同,因而具体的语音 语料库的建立也会碰到各种各样的困难,我们在这里所讨论的问题,只是对于建立语音语 料库的一种探讨,希望可以为语音的研究提供数据支持,为更好的发展语言,完善语音语料 库起着重要作用。 此外,数据量大毫无疑问是网络大数据分析技术的一大优势,但如何保证海量数 据的质量,以及如何实现对海量数据进行清洗、管理和分析等问题,也成为本课题研究的一 大技术难点。海量的网络大数据具有多源异构、交互性、时效性、突发性和高噪声等特点,因 而导致了网络大数据虽然价值巨大但噪声也大,价值密度低的特征。这对保证网络大数据 分析研究中的数据质量则构成了巨大挑战。
技术实现要素:
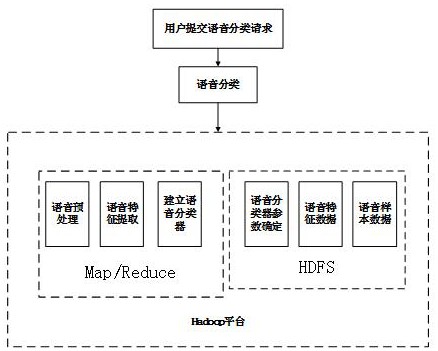
本发明设计了一种基于Hadoop平台的大数据语音分类方法,其解决的技术问题是 数据量大毫无疑问是网络大数据分析技术的一大优势,但如何保证海量数据的质量,以及 如何实现对海量数据进行清洗、管理和分析等问题,也成为一大技术难点。 为了解决上述存在的技术问题,本发明采用了以下方案: 一种基于Hadoop平台的大数据语音分类方法,包括以下步骤: 步骤1、进行语音库的构建; 步骤2、在此语音库基础上,基于Hadoop平台,采用Map函数对大数据语音分类问题进行 细分,用多节点并行、分布式地对子问题进行语音分类求解,得到相应的语音分类结果; 步骤3、最后利用Reduce函数对子问题的语音分类结果进行组合,以适应大数据语音分 类的在线要求。 优选地,所述步骤2包括以下内容:(1)Client向Hadoop平台的Job Tracker提交一 个语音分类任务,Job Tracker将语音特征数据复制到本地的分布式文件处理系统中; 5 CN 111583914 A 说 明 书 3/7 页 (2)对语音分类的任务进行初始化,将任务放入任务队列中,Job Tracker根据不同节 点的处理能力将任务分配到相应的节点上,即Task Tracker上; (3)各Task Tracker根据分配的任务,采用支持向量机拟合待分类语音特征与语音特 征库之间的关系,得到语音相应的类别; (4)将语音相应的类别作为 Key/Value,保存到本地文件磁盘中; (5)如果语音分类中间结果的Key/Value相同,则对其进行合并,将合并的结果交给 Reduce进行处理,得到语音分类的结果,并将结果写入到分布式文件处理系统中; (6)Job Tracker将任务状态进行清空处理,用户从分布式文件处理系统中得到语音分 类的结果。 优选地,步骤1、进行语音库的构建包括以下步骤:步骤11、发音文本的设计;步骤 12、语音录制;步骤13、语音文件的标注;步骤14、对语音文件的声学参数分析;步骤15、数据 库管理系统的建立。 优选地,所述步骤11中发音文本的设计包括发音文本的选择,所述发音文本的语 料库的选择原则包括以下一种或多种: a、语料库中的单字要求尽量包含所有的声韵现象,能够更好更方便的反映不同患者语 音的音系特征; b、语料库中的词汇依据汉语调查常用表为基础,所以能方便的与汉语普通话进行比 较; c、语料库中的句子主要是根据几个相关主题,与患者进行对话所得,所以更符合语音 识别面对的真实情形;“几个相关主题”包括日常生活主题或病史主题,例如询问首次发病 时间及病史情况。 d、语料库中的句子在内容和语义上都是完整的,所以能够尽可能的反映一个句子 的韵律信息; e、对三音子不进行归类的挑选,这样能够有效的解决训练数据稀疏的问题。 优选地,所述步骤11中所述发音文本的设计还包括发音文本的编制,所述发音文 本的编制原则包括以下一种或多种: a、单字部分:将调查字表中列举的声母韵母以及声调的一些常用字作为本次语音库的 主要录音所用语料; b、词汇部分:以至少一个四千词词表为基础,根据原来关于相关音系的结论记录相关 词语,力求能够全面反映其语音特点,包括音质和超音质特点,针对一些很有特色的语音现 象,可增加例词来反映其特征;“相关音系的结论记录相关词语”指的是,根据在同一语言中 使用的音,组合规律以及节律和语调的特点,总结的常用词汇。“特色的语音现象”指的是方 言中容易读错的,比如平舌音翘舌音难区分的,f和h不分等情况。 c、语句材料部分:根据不同发音人的语言掌握程度决定语料数量,选取时既要保 证语料的范围尽可能广,还需使其具有一定的代表性;“代表性”在此指的是可以体现运动 性构音障碍语言特点,具有普遍性的语句。 d、自然对话部分:日常生活为题,采用回答问题和自由谈话的形式,录制发音人 20-40分钟的语音材料,涉及日常口语中和普通话说法不同的词汇,要求发音人用方言说出 来。 6 CN 111583914 A 说 明 书 4/7 页 优选地,所述步骤12的语音录制包括发音人的确定,所述发音人的选取原则是挑 选口齿清晰、语速适中(“语速适中”是指语速适中,控制在120-150字/分钟)、熟练使用本地 语且愿意主动配合调查的母语发音人,还要保证其所处的语言环境比较稳定,同时又要有 文化程度; 或者/和,所述语音录制还包括通过语音采集器进行的语音采集,所述语音采集采用两 种方式:一种是具有提示文本的朗读,提示是汉语的文字材料,发音人将其转换成自己的母 语并朗读;另一种是自然语音,发音人利用提示讲述民间故事、民族生活状况以及当地民歌 的哼唱。 优选地,步骤14中所述对语音文件的声学参数分析包括语音库的语音标注,基本 的语音标注包括各个音节的声韵母切分和对齐,以及声韵调的标注,包括两个部分: 第一部分是文字标注,汉字 pinyin即字音转写,将语音信息用汉字记录下来,以便提 供给识别系统使用,也能为语言学的研究提供素材;文字标注必须标明基本文字信息以及 副语言学现象,基本标注中的副语言学现象可用通用副语言学符号表示; 第二部分是音节标注,普通话音节标注采用标准普通话音节标注,音节标注为有调标 注;声调标注中0表示轻声,1表示阴平,2表示阳平,3表示上声,4表示去声。 优选地,步骤14中所述对语音文件的声学参数分析还包括声学参数的提取; 首先对所录制的语音进行切分和消除静音段的处理,以保证分析的对象为单个字词、 词组、语句、对话;然后在语音波形数据中对于语音信号的起止段做出判定,对语音进行标 注;最后再根据自相关算法得到相应的基频和共振峰声学分析参数数据。 优选地,步骤15中所述数据库管理系统的建立包括数据库的选取,选用较易实现 的sql数据库管理系统; 或者/和,步骤15中所述数据库管理系统的建立中需存储四种素材:一是发音人属性素 材;二是发音文本素材,录入和存储患者发音素材及其对应的发音和普通话国际音标等文 本材料;三是实际语音数据材料,用于保存录制好的语音波形图形的原始参数;四是声学分 析参数数据,即对处理后的语音波形提取的声学参数的保存。 该基于Hadoop平台的大数据语音分类方法具有以下有益效果: (1)本发明基于Hadoop平台的大数据语音分类方法解决了大数据语音分类耗时长、实 时性差等技术问题。采用基于Hadoop平台的大数据语音分类机制利用云计算技术的优点, 以获得理想的大数据语音分类结果为目标,较好地克服了当前语音分类机制存在的弊端, 大幅度缩短了语音分类的时间,分类速度可适应大数据语音分类的在线要求,且语音分类 的整体效果明显优于当前其他语音分类机制。 (1)本发明旨在研究神经系统疾病引起的运动性构音障碍的患者语音特性,依托 于开放网络平台的优势,可以实现覆盖大规模群体的测量以及相关信息的收集,实现普通 话、方言、健康人语音、患者语音等语音库的建立,并在此基础上,建立满足运动性构音障碍 患者病情诊断的词库。 (2)本发明在语音库不断扩充下,最终分别根据普通话、方言、不同病史、不同病情 等信息建立丰富的数据资源中心,为神经系统疾病患者提供一种网络自主诊断的途径,也 可辅助医生进行临床诊疗,为神经系统疾病病情的量化提供丰富精准的数据平台。 (3)本发明在语音库基础上,基于Hadoop平台,采用Map函数对大数据语音分类问 7 CN 111583914 A 说 明 书 5/7 页 题进行细分,用多节点并行、分布式地对子问题进行语音分类求解,得到相应的语音分类结 果;最后利用Reduce函数对子问题的语音分类结果进行组合,以适应大数据语音分类的在 线要求。 附图说明 图1:本发明实施例中“bao”的语音标注示例。 图2:本发明实施例中“bao”语音的共振峰数据。 图3:本发明实施例中Hadoop平台的基本框架。 图4: 本发明基于Hadoop平台的大数据语音分类流程。











