
技术摘要:
本发明涉及ICT供应链招投标项目与企业产品实体匹配方法,属于自然语言处理与机器学习领域。主要为了解决ICT领域招投标项目和企业产品之间由于描述角度不同而造成的匹配困难问题。本发明首先根据维基百科预训练所得的词向量表,查表获得目标实体词嵌入向量表示;将由词 全部
背景技术:
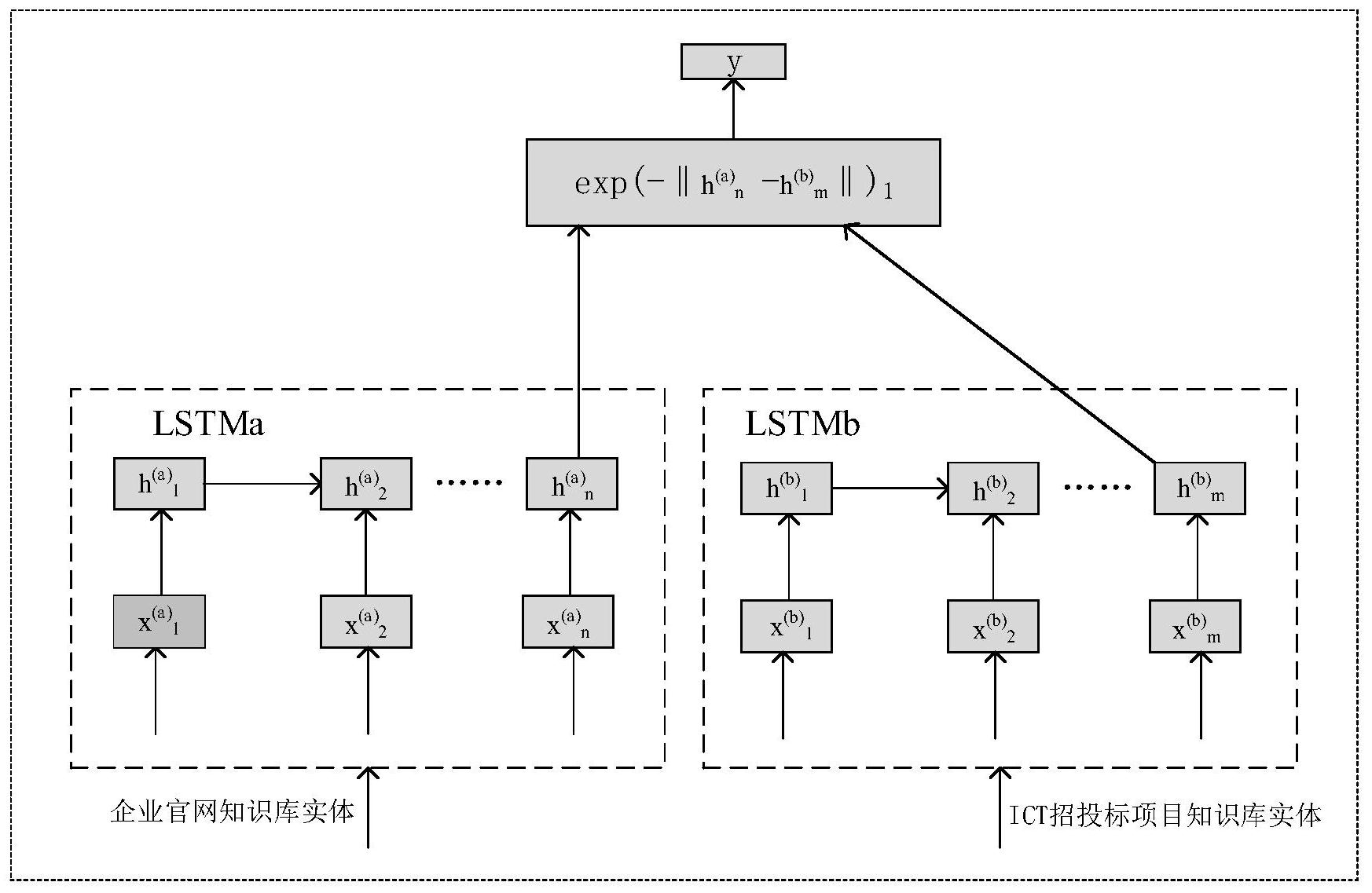
针对ICT招投标领域来说,招投标平台的招投标信息内容通常是由于招标方从客 户的视角、基于功能需求对所需的ICT招投标项目进行描述,而供应商往往依据研发过程中 产品的迭代情况,从技术的角度对企业产品进行描述,因此造成招投标项目和企业产品之 间匹配困难。 早期实体匹配研究大多采用基于字符串相似度的匹配方法,但仅仅考虑了字符串 的统计信息,忽略了文本语义信息,继而提出的基于知识库和语料库的相似度计算方法,借 助单词语义网络加入单词语义信息或从巨大的语料库中学习出语义信息,再到后来使用混 合相似度结合起来作为特征,但均存在需要人工抽取特征,依赖专家领域知识,人工成本高 的缺点。 针对以上困难,深度学习能够自动学习特征表示,避免了人工设计特征的缺陷,采 用孪生网络进行句子交互,可比较实体间深度语义信息。CNN可通过将不同窗口大小的差异 局部信息进行整合来推断句子的相似性,但是无法捕捉自然语言序列的时序信息,且需要 大量的标签数据来训练网络;RNN模型在序列信息的学习上已被证明具有完备的结构特性, 但其无法避免由梯度消失引起的权重矩阵优化困难;LSTM弥补了RNN梯度消失的缺陷,通过 使用可存储跨长输入序列信息的内存单元来学习远程依赖关系,可学习深度语义特征。因 此提出一种使用LSTM孪生网络作为编码器,基于曼哈顿距离的度量函数计算待匹配实体对 空间相似度的实体匹配方法。
技术实现要素:
本发明的目的是针对ICT领域招投标项目和企业产品之间由于描述角度不同而造 成的匹配困难的问题,构建一种基于LSTM孪生网络的实体匹配模型。 本发明的设计原理为:首先根据维基百科预训练所得的词向量表,查表获得目标 实体词嵌入向量表示;将由词嵌入向量序列表示的待匹配的实体对分别传递至LSTM孪生网 络,更新每个序列索引处隐藏状态,由模型最终隐藏状态编码得到实体对最终语义向量表 示;后使用基于曼哈顿距离的度量函数计算待匹配实体对的空间相似度;最后根据阈值得 到待匹配实体对的匹配结果。 本发明的技术方案是通过如下步骤实现的: 步骤1,根据维基百科预训练所得的词向量表,查表获得目标实体词嵌入向量表 示。 步骤2,将由词嵌入向量表示的待匹配的实体对分别传递至LSTM孪生网络,更新每 个序列索引处隐藏状态,由模型最终隐藏状态编码得到实体对最终语义向量表示。 3 CN 111597820 A 说 明 书 2/3 页 步骤3,使用基于曼哈顿距离的度量函数计算待匹配实体对的空间相似度。 步骤4,根据阈值判别得到待匹配实体对的实体匹配结果。 有益效果 相比于基于特征工程的实体匹配方法,本发明拥有更强语义特征学习能力,且 LSTM可更好的提供长距离依存关系,使之拥有更高的准确率和召回率。 相比于基于RNN的实体匹配方法,本发明使用可存储跨长输入序列信息的内存单 元来学习远程依赖关系,避免了RNN的缺陷。 相比于基于简单神经网络的实体匹配方法,本发明利用孪生网络抽取招投标项目 和企业产品之间的一致语义信息,更好地实现实体匹配。 附图说明 图1为本发明LSTM孪生网络模型原理图。











