
技术摘要:
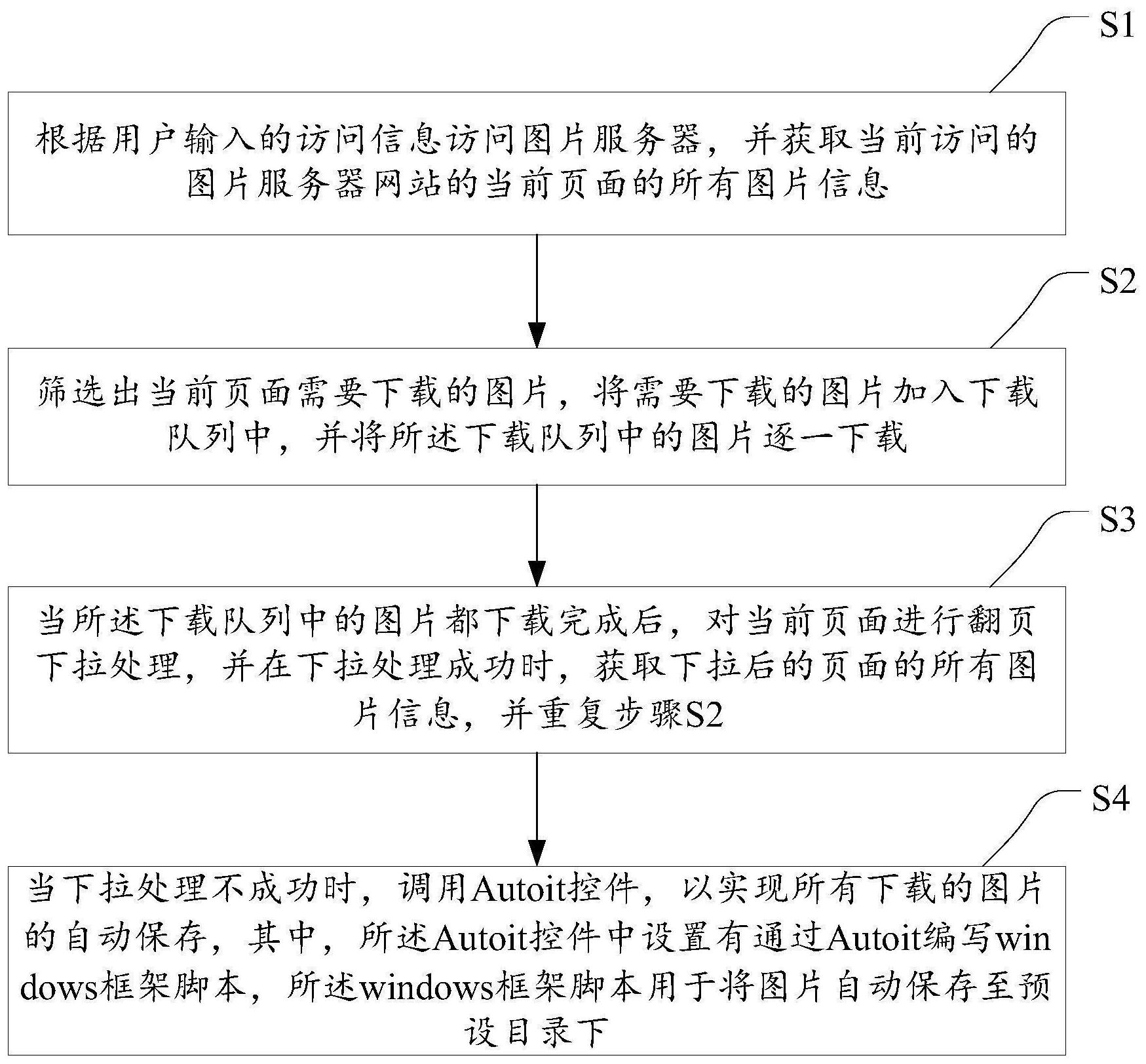
本发明公开了一种实现网站图片爬虫的方法、装置、设备及存储介质,所述方法包括:S1、访问图片服务器,并获取当前访问的图片服务器网站的当前页面的所有图片信息;S2、筛选出当前页面需要下载的图片,将需要下载的图片加入下载队列中,并将所述下载队列中的图片逐一下 全部
背景技术:
python(一种跨平台的计算机程序设计语言)爬虫是一种按照一定规则,自动抓取 网络数据的程序或脚本,但是现在很多互联网网站为了保护自己的服务器,都增加反爬虫 策略,阻止python爬虫的继续采集,导致目前使用的python爬虫在互联网上进行数据抓取 时,经常会遇见各种奇怪的封禁问题,使得爬虫功能失效,工作无法正常进行。 因而现有技术还有待改进和提高。
技术实现要素:
鉴于上述现有技术的不足之处,本发明的目的在于提供一种实现网站图片爬虫的 方法、装置、设备及存储介质,可通过代替和模拟操作人员的动作将网站上的图片下载,无 法再担心网络爬虫带来的封禁风险。 为了达到上述目的,本发明采取了以下技术方案: 第一方面,本发明提供了一种实现网站图片爬虫的方法,包括如下步骤: S1、根据用户输入的访问信息访问图片服务器,并获取当前访问的图片服务器网 站的当前页面的所有图片信息; S2、筛选出当前页面需要下载的图片,将需要下载的图片加入下载队列中,并将所 述下载队列中的图片逐一下载; S3、当所述下载队列中的图片都下载完成后,对当前页面进行翻页下拉处理,并在 下拉处理成功时,获取下拉后的页面的所有图片信息,并重复步骤S2; S4、当下拉处理不成功时,调用Autoit控件,以实现所有下载的图片的自动保存, 其中,所述Autoit控件中设置有通过Autoit编写windows框架脚本,所述windows框架脚本 用于将图片自动保存至预设目录下。 第二方面,本发明提供了一种实现网站图片爬虫的装置,包括: 图片信息获取模块,用于根据用户输入的访问信息访问图片服务器,并获取当前 访问的图片服务器网站的当前页面的所有图片信息; 图片下载模块,用于筛选出当前页面需要下载的图片,将需要下载的图片加入下 载队列中,并将所述下载队列中的图片逐一下载; 页面下拉模块,用于当所述下载队列中的图片都下载完成后,对当前页面进行翻 页下拉处理,并在下拉处理成功时,获取下拉后的页面的所有图片信息,并下载下拉后的页 面中的需要下载的图片; 图片保存模块,用于当下拉处理不成功时,调用Autoit控件,以实现所有下载的图 片的自动保存,其中,所述Autoit控件中设置有通过Autoit编写windows框架脚本,所述 4 CN 111597421 A 说 明 书 2/7 页 windows框架脚本用于将图片自动保存至预设目录下。 第三方面,本发明提供了一种实现网站图片爬虫的设备,其特征在于,包括处理器 和存储器; 所述存储器上存储有可被所述处理器执行的计算机可读程序; 所述处理器执行所述计算机可读程序时实现如上所述的实现网站图片爬虫的方 法。 第四方面,本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质 存储有一个或者多个程序,所述一个或者多个程序可被一个或者多个处理器执行,以实现 如上所述的实现网站图片爬虫的方法中的步骤。 相较于现有技术,本发明提供的实现网站图片爬虫的方法、装置、设备及存储介 质,通过完全代替和模拟操作人员的动作,可以将网站上的所有图片都下载下来,并且不需 要再担心网络爬虫带来的封禁风险,此外,还能够高效的完全数据的获取,减轻工作量,有 效提高工作效率。 附图说明 图1为本发明提供的实现网站图片爬虫的方法的一较佳实施例的流程图; 图2为本发明提供的实现网站图片爬虫的方法中所述步骤S2的一较佳实施例的流 程图; 图3为本发明提供的实现网站图片爬虫的方法中所述步骤S3的一较佳实施例的流 程图; 图4为本发明提供的实现网站图片爬虫的装置的一较佳实施例的结构框图; 图5为本发明安装实现网站图片爬虫的程序的较佳实施例的运行环境示意图。











