
技术摘要:
本发明公开一种样本模型训练方法、样本生成方法、装置、设备及介质。该方法包括:获取原始训练数据,原始训练数据包括样本标签和至少两个样本特征对应的特征数据;将原始训练数据输入到基于树模型构建的初始森林模型,获取原始高阶组合特征;基于样本标签和原始高阶组 全部
背景技术:
由于DeepFM算法有效结合因子分解机与神经网络在特征学习中的优点,可以同时 提取到低阶组合特征与高阶组合特征,使其在不同领域被广泛使用。例如,可以采用用户访 问系统或者其他场景形成的用户画像数据作为模型训练样本,将模型训练样本输入DeepFM 模型进行模型训练,更新DeepFM模型的模型参数,构建基于DeepFM的用户画像分析模型,使 得该用户画像分析模型可以同时提取低阶组合特征和高阶组合特征,使其分析结果更准 确。 当DeepFM模型训练过程中,每一模型训练样本包括至少两个样本特征对应的数据 域,每一数据域中的数值采用One-Hot编码,且每一数据域的大小依据样本特征的特征数据 确定。作为一示例,针对年龄这一样本特征,可以将年龄数值进行二进制转换,以获取相应 的One-Hot编码,此时,年龄这一样本特征的数据域的大小为最大年龄对应的One-Hot编码 的长度。又例如,针对年龄这一样本特征,可以依据预设的年龄段划分,从而确定One-Hot编 码,此时,年龄这一样本特征的数据域的大小为年龄段数量。针对城市这一样本特征,包括 北京、上海、天津、重庆和广东这几个特征数据,可以分别转换为10000、01000、00100、00010 和00001,此时,城市这一样本特征的数据域的大小为预先设置的特征数据的数量。 当前DeepFM模型训练过程中,每一模型训练样本包括至少两个数据域,每一数据 域的大小依据样本特征的特征数据确定,在样本特征对应的特征数据存在时间跨度大、离 散程度高或者稳定性较差等情况,使得该样本特征的数据域的大小较大,从而形成的模型 训练样本的维度较高,在将模型训练样本输入DeepFM模型进行训练时,使得模型训练过程 所需系统资源较多且训练时间较长;而且,由于模型训练样本的维度较高,容易出现过拟 合,导致无法学习到稳定的DeepFM模型或者训练所得的DeepFM模型的输出结果准确性较 低。
技术实现要素:
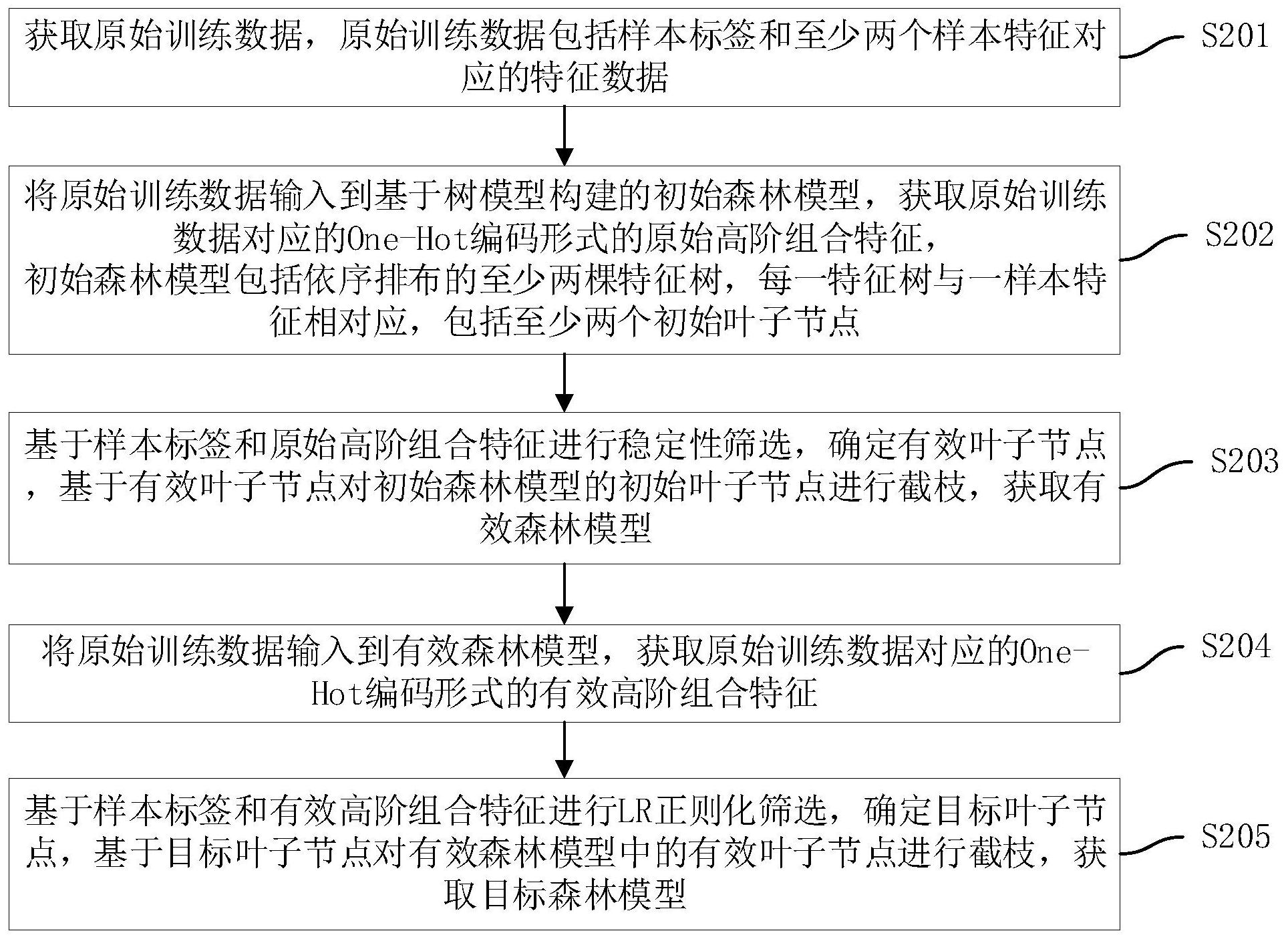
本发明实施例提供一种样本模型训练方法、样本生成方法、装置、设备及介质,以 解决当前DeepFM模型训练所获取的模型训练样本维度较高,导致模型训练所需系统资源较 多、训练时间较长及训练所得模型识别准确性较低的问题。 本发明实施例提供一种样本模型训练方法,包括: 获取原始训练数据,所述原始训练数据包括样本标签和至少两个样本特征对应的 特征数据; 将所述原始训练数据输入到基于树模型构建的初始森林模型,获取所述原始训练 数据对应的One-Hot编码形式的原始高阶组合特征,所述初始森林模型包括依序排布的至 5 CN 111581877 A 说 明 书 2/16 页 少两棵特征树,每一所述特征树与一所述样本特征相对应,包括至少两个初始叶子节点; 基于所述样本标签和所述原始高阶组合特征进行稳定性筛选,确定有效叶子节 点,基于所述有效叶子节点对所述初始森林模型的初始叶子节点进行截枝,获取有效森林 模型; 将所述原始训练数据输入到所述有效森林模型,获取所述原始训练数据对应的 One-Hot编码形式的有效高阶组合特征; 基于所述样本标签和所述有效高阶组合特征进行LR正则化筛选,确定目标叶子节 点,基于所述目标叶子节点对所述有效森林模型中的有效叶子节点进行截枝,获取目标森 林模型。 本发明实施例提供一种样本模型训练装置,包括: 原始训练数据获取模块,用于获取原始训练数据,所述原始训练数据包括样本标 签和至少两个样本特征对应的特征数据; 原始高阶组合特征获取模块,用于将所述原始训练数据输入到基于树模型构建的 初始森林模型,获取所述原始训练数据对应的One-Hot编码形式的原始高阶组合特征,所述 初始森林模型包括依序排布的至少两棵特征树,每一所述特征树与一所述样本特征相对 应,包括至少两个初始叶子节点; 有效森林模型获取模块,用于基于所述样本标签和所述原始高阶组合特征进行稳 定性筛选,确定有效叶子节点,基于所述有效叶子节点对所述初始森林模型的初始叶子节 点进行截枝,获取有效森林模型; 有效高阶组合特征获取模块,用于将所述原始训练数据输入到所述有效森林模 型,获取所述原始训练数据对应的One-Hot编码形式的有效高阶组合特征; 目标森林模型获取模块,用于基于所述样本标签和所述有效高阶组合特征进行LR 正则化筛选,确定目标叶子节点,基于所述目标叶子节点对所述有效森林模型中的有效叶 子节点进行截枝,获取目标森林模型。 一种计算机设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理 器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述样本模型训练方法。 一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计 算机程序被处理器执行时实现上述样本模型训练方法。 本发明实施例提供一种样本生成方法,包括: 获取待处理数据,所述待处理数据包括至少两个样本特征对应的特征数据; 将至少两个样本特征对应的特征数据输入上述样本模型训练方法确定的目标森 林模型,将所述目标森林模型输出的One-Hot编码形式的目标高阶组合特征,确定为DeepFM 模型的模型训练样本。 本发明实施例提供一种样本生成装置,包括: 待处理数据获取模块,用于获取待处理数据,所述待处理数据包括至少两个样本 特征对应的特征数据; 模型训练样本获取模块,用于将至少两个样本特征对应的特征数据输入上述样本 模型训练方法确定的目标森林模型,将所述目标森林模型输出的One-Hot编码形式的目标 高阶组合特征,确定为DeepFM模型的模型训练样本。 6 CN 111581877 A 说 明 书 3/16 页 一种计算机设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理 器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述样本生成方法。 一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计 算机程序被处理器执行时实现上述样本生成方法。 上述样本模型训练方法、装置、设备及介质中,训练所得的目标森林模型,可以实 现对原始训练数据中至少两个样本特征的特征数据转换成包括至少两个数据域的One-Hot 编码形式的高阶组合特征,使其可以输入DeepFM模型进行模型训练;而且,由于目标森林模 型是对初始森林模型中的初始叶子节点经过稳定性筛选和LR正则化筛选确定的森林模型, 经过二次筛选降维,使得形成的高阶组合特征的维度较低,使其输出到DeepFM模型进行模 型训练时,可以节省训练过程占用的系统资源,并缩短训练时长;而且,目标森林模型中的 目标叶子节点与DeepFM模型的模型训练目的相匹配,并过滤稳定性较低的叶子节点,减少 目标森林模型输出的模型训练样本在DeepFM模型训练过程中出现过拟合现象,节省模型训 练过程所占用的系统资源,有助于提高模型训练样本训练DeepFM模型的准确性。 上述样本生成方法、装置、设备及介质中,采用上述实施例确定的目标森林模型对 待处理数据至少两个样本特征的特征数据转换成包括至少两个数据域的One-Hot编码形式 的高阶组合特征,使其形成可以输入DeepFM模型进行模型训练的模型训练样本;而且,由于 目标森林模型是对初始森林模型中的初始叶子节点经过稳定性筛选和LR正则化筛选确定 的森林模型,经过二次筛选降维,使得形成的高阶组合特征的维度较低,使其输出的模型训 练样本输入到DeepFM模型进行模型训练时,可以节省训练过程占用的系统资源,并缩短训 练时长;而且,目标森林模型中的目标叶子节点与DeepFM模型的模型训练目的相匹配,并过 滤稳定性较低的叶子节点,减少目标森林模型输出的模型训练样本在DeepFM模型训练过程 中出现过拟合现象,节省模型训练过程所占用的系统资源,有助于提高模型训练样本训练 DeepFM模型的准确性。 附图说明 为了更清楚地说明本发明实施例的技术方案,下面将对本发明实施例的描述中所 需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施 例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图 获得其他的附图。 图1是本发明一实施例中计算机设备的一示意图; 图2是本发明一实施例中样本模型训练方法的一流程图; 图3是本发明一实施例中样本模型训练方法的另一流程图; 图4是本发明一实施例中初始森林模型中一特征树的一示意图; 图5是本发明一实施例中样本模型训练方法的另一流程图; 图6是本发明一实施例中样本模型训练方法的另一流程图; 图7是本发明一实施例中样本生成方法的另一流程图; 图8是本发明一实施例中样本模型训练装置的一示意图; 图9是本发明一实施例中样本生成装置的一示意图。 7 CN 111581877 A 说 明 书 4/16 页











