
技术摘要:
本发明公开了一种改进的多通道语音增强系统和方法,将采集的多麦信号输入训练的自适应波束形成网络生成单通道信号;将生成的单通道信号通过共享网络进行信息转换;将转换后的信号输入多目标学习网络的主任务网络得到增强后的语音信号;将转换后的信号输入多目标学习网 全部
背景技术:
随着现代工业的迅速发展和人们对于生活质量要求的不断提升,环境污染问题引 起了社会的广泛关注。其中噪声污染与水污染、大气污染被看成是世界范围内的三大污染。 噪声污染也如同其他污染一样,广泛的存在于日常生活的方方面面。噪声具有高强度和低 强度之分,其中低强度的噪声在一般情况下对人的身心健康没有什么大的害处,但是高强 度的噪声却极易影响人们的身心健康,会使人精神不振、身心疲劳、记忆力减退,在长时间 接触后甚至会引起疾病。在城市生活中噪声污染的来源主要有交通噪声、工业噪声、施工噪 声和社会生活噪声四种。 在上世纪的70年代,研究人员已经开始了对多通道语音增强进行相应的研究,在 90年代取得了对多通道语音增强技术研究的阶段性成果,且人们对麦克风阵列技术的应用 研究也越来越深,固定波束形成算法和自适应波束形成算法等多通道语音增强技术被相继 的提出。固定波束形成算法实现较为简单,但是为了得到较好的语音增强性能,通常需要较 多的麦克风阵元。此外,由于权值是固定的常数,其对环境的适应性不强,因此后续发展出 各种自适应波束形成算法。相比于固定波束形成,自适应波束形成能够根据环境的变化来 自适应的调整各个通道语音的权值。为了进一步的提高波束形成后的语音的信噪比,一些 专家学者将后置滤波算法引入到语音增强算法当中。通过在波束形成输出端加入自适应模 块,语音增强系统能够对非平稳的噪声产生更好的抑制作用。后续又有一些研究人员对后 置滤波技术进行相应的优化,将非线性运算加入到后置滤波算法当中。 最近几年,得益于人工智能技术的迅猛发展,许多专家学者开始将深度神经网络 应用于语音增强技术当中。通过神经网络的增强语音通常能够具有较好的语音清晰度和可 懂度,但是,由于神经网络存在梯度消失和梯度爆炸问题,因而训练得到的网络经常是不收 敛的,从而影响语音增强的效果。
技术实现要素:
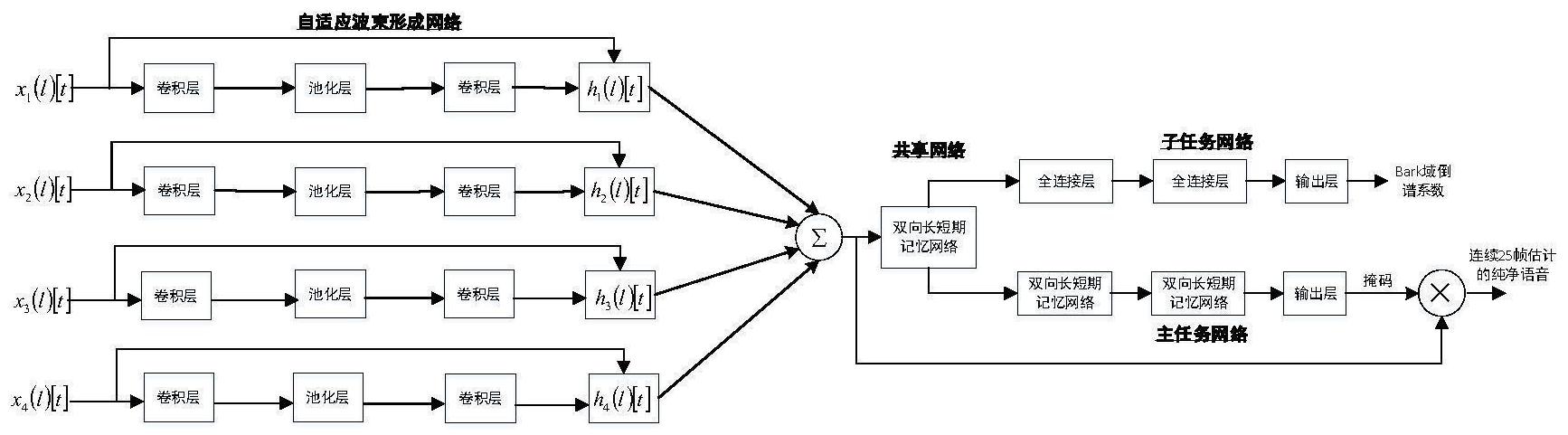
本发明所要解决的技术问题是针对上述现有技术的不足,提供一种改进的多通道 语音增强系统和方法,基于人工智能的思想,提出结合卷积神经网络和多目标学习的多通 道语音增强系统,能解决传统的多通道语音增强算法无法抑制非平稳噪声,且鲁棒性差的 问题,以及缓解神经网络中存在的梯度消失和梯度爆炸导致的网络不收敛的问题。 为实现上述技术目的,本发明采取的技术方案为: 一种改进的多通道语音增强系统,包括自适应波束形成网络、共享网络和多目标 学习网络; 所述自适应波束形成网络用于将采集的多麦信号转换为单通道信号; 4 CN 111583948 A 说 明 书 2/5 页 所述多目标学习网络包括主任务网络和子任务网络; 所述主任务网络用于以语音频谱的幅度掩蔽为目标进行训练,得到增强后的语音 信号; 所述子任务网络用于以语音的bark域倒谱系数为目标进行训练,表征语音信息的 特征; 所述共享网络用于将单通道信号通过双向长短期记忆网络,使得系统能够进行时 间序列预测,保证主任务网络和子任务网络之间的信息交换。 为优化上述技术方案,采取的具体措施还包括: 上述的自适应波束形成网络包括1层输入层、2层一维卷积层和1层平均池化层; 所述1层输入层、2层一维卷积层和1层平均池化层用于组成一个卷积神经网络,从 而将采集到的多麦信号转换为单通道信号; 其中,输入层的输入为每个麦克风的连续25帧时域信号; 第1层一维卷积层含有128个卷积神经元,第2层一维卷积层含有256个卷积神经 元; 第1层一维卷积层不使用丢弃技术,第2层卷积层一维使用丢弃技术来防止网络过 拟合,其中丢弃的概率设置为0.2。 上述的共享网络和主任务网络均包括多层双向LSTM层,用于缓解神经网络中可能 出现的梯度消失和梯度爆炸的问题。 上述的共享网络包含1层双向LSTM层,所述双向LSTM层含有832个神经元单元; 所述双向LSTM层用于使得系统能够进行时间序列预测,保证主任务网络和子任务 网络之间的信息交换。 上述的主任务网络包括2层双向LSTM层和1层输出层; 所述2层双向LSTM层和1层输出层用于以语音频谱的幅度掩蔽为目标进行训练;输 出层输出估计的语音频谱幅度掩蔽,用于转换得到连续25帧的纯净语音; 其中,第1层双向LSTM层含有832个神经元,第2层双向LSTM层含有512个神经元,输 出层为含有257个神经元的全连接神经元; 主任务网络的损失函数为: l1=|ypreSMM-ytarSMM| (1) 其中,ypreSMM是主任务估计的语音频谱幅度掩蔽,ytarSMM是参考语音的频谱幅度掩 蔽。 上述的子任务网络包括2层全连接层和1层输出层; 2层全连接层分别用于以语音的bark域倒谱系数为目标进行训练;1层输出层输出 估计的bark域倒谱系数; 其中,第1层全连接层含有512个神经元,第2层全连接层含有256个神经元,输出层 为含有39个神经元的全连接神经元; 子任务网络的损失函数为: 其中,ypreFEA是子任务估计的bark域倒谱系数,ytarFEA是参考语音的bark域倒谱系 5 CN 111583948 A 说 明 书 3/5 页 数。 上述的多目标学习网络的总损失函数为: lall=(1-α)l1 α·l2 (3) 其中,α是权重系数。 上述的一种改进的多通道语音增强系统的语音增强方法,所述方法包括: a)自适应波束形成网络将采集的多麦信号转换为单通道信号; b)共享网络将生成的单通道信号进行信息转换; c)转换后的信号输入多目标学习网络的主任务网络,主任务网络以语音频谱的幅 度掩蔽为目标进行训练,得到增强后的语音信号; d)转换后的信号输入多目标学习网络的子任务网络,子任务网络以语音的bark域 倒谱系数为目标进行训练,表征语音信息的特征。 本发明具有以下有益效果: 相较于传统算法,本发明避免了声源定位算法,并可以有效的抑制非平稳噪声。本 发明在神经网络中加入了LSTM层,能够在一定程度上缓解梯度消失和梯度爆炸问题,减少 训练结果不收敛的情况,从而改善语音增强的效果。同时,由于引入多任务学习策略,增加 了算法的鲁棒性,提升了算法性能,具有良好的应用前景。 附图说明 图1是本发明系统模型结构框图。 图2是算法性能对比图。











