
技术摘要:
本发明公开了一种新的适用于自然场景下的全卷积单阶段的人体实例分割方法,该方法包括特征图提取、生成原型掩膜、掩膜系数计算、分类、位置回归、中心性计算、通过ROIAlign产生感兴趣区域以及原型掩膜和掩膜系数相结合得到最终的实例掩膜。在特征图提取时,采用ResNet 全部
背景技术:
自然场景下的人体实例分割是当前计算机视觉领域一个新的难题,实例分割在一 定程度上可以理解为目标检测和语义分割的结合,实例分割可以被广泛应用于无人驾驶、 医疗图像分析、智能机器人以及地理信息系统等领域,其中人体实例分割显得尤为重要。 当下,目标检测和语义分割任务的主流解决方案通过卷积神经网络实现,实例分 割也不例外,目前已经提出的性能较好的实例分割网络包括two-stage的Mask R-CNN和 FCIS以及one-stage的YOLACT等。Mask R-CNN缺点主要在于检测器采用Faster-RCNN,需要 设计大量的anchors,引入很多人工设计的尺度和比例参数,FCIS的主要缺点在于在第一阶 段需要通过RPN生成大量的候选框,YOLACT网络的缺点在于使用基于全图的原型掩膜和掩 膜系数做结合生成最终的实例掩膜,缺少对于感兴趣区域的提取。
技术实现要素:
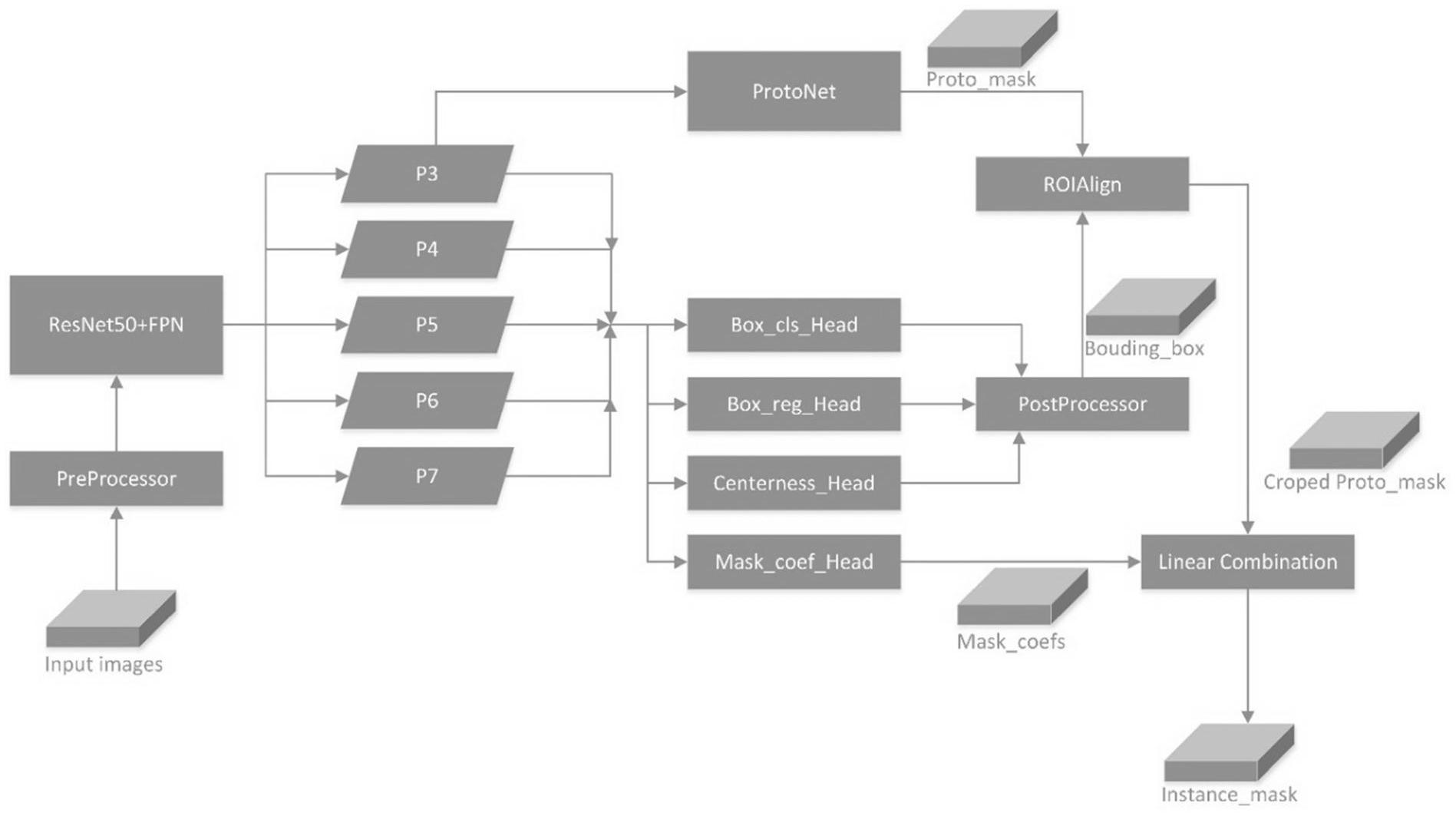
发明目的,本发明旨在解决现有方法需要设计大量锚点、具有双阶段架构、检测速 度较慢,缺少实时应用价值的缺点,针对自然场景下的人体实例分割问题,提出一种新的自 然场景下的全卷积单阶段实时人体实例分割方法,该方法应该是单阶段的、不需要使用锚 点的,可以实现实时的人体实例分割,同时具有较高的查准率。 为实现本发明的目的,本发明所采用的技术方案是:一种基于深度学习的自然场 景下全卷积单阶段人体实例分割方法,实现如下功能:对一张包含人体的自然场景下的图 片,通过深度卷积神经网络处理实现对所有人体实例的实时分割。 本方法生成实例掩膜的思路为:通过将由卷积神经网络预测得到的原型掩膜和掩 膜系数进行分段线性组合,得到最终的实例掩膜。 该方法的训练过程包括如下步骤: 步骤一:通过骨干网络从输入的包含人体的自然场景图像中实现特征图提取; 步骤二:基于骨干网络提取到的特征图,通过全卷积网络实现掩膜系数计算、中心 性指标计算、分类和回归计算; 步骤三:基于骨干网络提取到的特征图,通过全卷积网络生成原型掩膜,原型掩膜 是用来生成最终实例掩膜的组成元素之一; 步骤四:通过ROIAlign在生成的原型掩膜上截取感兴趣的区域; 步骤五:将原型掩膜中的感兴趣的区域和掩膜系数相结合得到最终的实例掩膜; 步骤六:根据分类结果、回归结果、中心性指标和计算得到的实例掩膜,进行分类 和回归的loss计算、中心性的loss计算以及实例掩膜的loss计算; 步骤七:在COCO-2017-train数据集上采用随机梯度下降方法不断迭代优化神经 5 CN 111597920 A 说 明 书 2/8 页 网络,最终得到训练好的网络; 步骤八:将训练好的网络用于自然场景下的人体实例分割和目标检测。 进一步的,所述步骤1中的特征图提取,采用与FCOS网络相同的残差网络 特征金 字塔网络作为骨干网络,从输入图片中提取到多尺度的特征图P3、P4、P5、P6、P7。 进一步的,所述步骤2中的基于提取到的特征图,通过全卷积网络实现掩膜系数、 中心性指标以及分类和回归的计算,具体而言是通过全卷积网络对步骤1中输出的特征图 逐点位地计算掩膜系数、中心性指标以及分类和回归结果。首先将通过骨干网络得到的金 字塔特征图P3、P4、P5、P6、P7,再将其送入四层3*3卷积层,保持特征图尺寸不变,计算得到 分类共享特征图,然后将分类共享特征图送入分类卷积层得到类别计算结果,将分类共享 特征图送入中心性计算卷积层得到中心性计算结果,将特征图P3、P4、P5、P6、P7送入回归卷 积层,即五层3*3卷积层,计算得到回归结果,将特征图P3、P4、P5、P6、P7送入掩膜系数计算 卷积层,即五层3*3卷积层,计算得到掩膜系数。 其中,中心性指标以及分类和回归结果与FCOS网络相同,得到的掩膜系数维度为H ×W×Ccoef,其中,H×W表示特征图的尺寸,Ccoef表示掩膜系数的通道数,且Ccoef=Scrop×Scrop ×k2,其中Scrop表示利用ROIAlign在原型掩膜上截取的感兴趣区域的尺寸,k表示实例掩膜 在水平和竖直两个方向上的分段组数,假设实例掩膜在水平和竖直两个方向上的分段组数 相同。 进一步的,所属步骤3中的原型掩膜生成,从生成的特征图P3、P4、P5、P6、P7中选择 P3送入原型掩膜生成网络,经过五层3*3卷积层后,再通过Sigmoid激活函数输出原型掩膜, 原型掩膜也是针对特征图P3上的每个点输出的。原型掩膜的维度为H×W×Ccoef,其中H×W 表示输入原型生成网络的特征图的尺寸,Cproto表示原型掩膜的通道数,且Cproto=Smask× Smask,其中Smask表示最终期望生成的实例掩膜尺寸。 进一步的,所述步骤4中的通过ROIAlign提取原型掩膜中感兴趣的区域,通过原型 掩膜生成网络得到原型掩膜,根据原型原膜和目标人体边界框的真实值,通过ROIAlign提 取原型mask中感兴趣的区域。其具体步骤包括: 1 .根据尺度对应关系,计算目标人体边界框的真实值对应到特征图上的区域,不 作任何量化; 2.将候选区域分割成Scrop×Scrop个单元,每个单元的边界也不做量化; 3.将每个单元按照十字形平分成四份,每一份取其中心点位置,根据每个中心点 四周的像素点取值,用双线性内插的方法计算出这四个中心点位置的值,然后进行最大池 化操作。 经过ROIAlign,得到的原型掩膜感兴趣区域维度为nobj×Scrop×Scrop×Cproto其中, nobj表示检测到的物体个数,Scrop表示得到的原型掩膜感兴趣区域的尺度,Cproto为得到的原 型掩膜通道数。 进一步的,所述步骤5中的原型掩膜和掩膜系数的结合,其方法为:采用分段线性 组合的方式,通过结合原型掩膜感兴趣区域以及掩膜系数生成实例掩膜。 具体步骤如下: (1)设最终期望生成的实例掩膜M的大小为Smask×Smask,则对于原型掩膜而言,设置 其通道数C 2proto=Smask ,设原型掩膜的感兴趣区域的边长为Scrop,经过ROIAlign,得到的原型 6 CN 111597920 A 说 明 书 3/8 页 掩膜感兴趣区域维度为n 2obj×Scrop ×Cproto=n 2obj×Scrop ×S 2mask ,经过张量形状重塑 (reshape)操作后,得到原型掩膜感兴趣区域维度为n ×S 2 2obj mask ×Scrop ,其中nobj表示待预 测的目标实例个数。 (2)对于掩膜系数而言,根据原型掩膜的感兴趣区域的边长为Scrop,设原型掩膜在 水平和竖直两个方向上的都分成k段,则掩膜系数的通道数Ccoef设置为 C 2coef=Scrop ×k2 经过对特征图上的位置进行筛选后,得到掩膜系数的维度为nobj×Ccoef=nobj× S 2 2crop ×k 。 (3)对于每一个待预测的目标而言,其原型掩膜张量维度为S 2mask×Smask×Scrop ,沿 其水平和竖直方向各分为k段,每一段原型掩膜的维度为 即将原型掩 膜共分成k2段。 (4)对于每一个待预测的目标而言,其掩膜系数张量维度为S 2crop×Scrop×k ,将其 沿着深度方向分为k2段,每一段掩膜系数的维度为Scrop×Scrop,可看成一个二维张量,且每 一段掩膜系数与每一段原型掩膜一一对应。 (5)将每一段原型掩膜和每一段掩膜系数相结合,生成实例掩膜的每一个分段。 具体的,对于每一个维度为 的原型掩膜分段,可看成由S 2crop 个大小为 的原型掩膜二维张量组成,可将这些原型掩膜二维张量记为为 对于每一个维度为Scrop×S 2crop的掩膜系数分段,可看成由Scrop 个掩膜系数标量组 成的二维张量,可将这些掩膜系数标量记为 则实例掩膜的一个分段Mdiv可按如下式子计算: 其中,掩膜系数标量ci和原型掩膜二维张量pi的相乘为标量和张量的相乘,即ci分 别乘以pi的每一个元素,从而得到新的二维张量,然后再对这些二维张量求和得到实例掩 膜的一个分段。 (6)得到所有实例掩膜的分段后,将它们依次做水平和竖直方向上的连接 (concat),最终可以得到大小为Smask×Smask的实例掩膜M。 进一步的,所属步骤6中的各项损失函数的计算,其中,分类损失函数采用focal loss,回归损失函数采用IOU loss,实例掩膜损失函数采用二进制交叉熵损失函数,中心性 损失函数采用带有sigmoid函数的二进制交叉熵损失。 进一步的,所述步骤7中对网络采用引入动量的随机梯度下降法进行训练,选取 batch size大小为8,使用两块Tesla P100 GPU进行训练。 进一步的,所述步骤8中用训练好的网络做自然场景下的人体实例分割,在 COCO2017test测试该方法的时候,步骤1、步骤2、步骤3和步骤4与训练时相同,步骤5中生成 原型掩膜中感兴趣区域时,采用生成的回归结果进行定位,步骤6也和训练时相同,最后得 7 CN 111597920 A 说 明 书 4/8 页 到图片中人体的实例分割结果。 有益效果:与现有技术相比,本发明的技术方案具有以下有益技术效果: 本发明所提出的自然场景下的人体实例分割方法,具有单阶段、全卷积、不需要 anchors等特点,从而具有较快的运行速度,实现了实时人体实例分割;同时,本发明具备生 成原型掩膜感兴趣区域的能力,并且采用了分段线性组合的方式结合掩膜系数和原型掩 膜,从而得到最终的实例掩膜,因此具有较高的查准率。 本方法在MS COCO 2017数据集上完成了训练和测试,其中,训练采用COCO 2017train数据集,测试采用COCO 2017val数据集,并且从两个数据集中都筛选出了包含人 体实例标注的图片进行训练和测试,舍弃其余图片。本方法获得了可以与目前主流方法相 比较的性能,可以实现41.4fps速度下的实时人体实例分割,同时人体实例分割的平均查准 率可以达到34.8%。 附图说明 图1是本发明整体网络结构图。 图2是本发明中生成实例掩膜的方法示意图。 图3是本发明在COCO 2017val数据集上的部分测试结果图。











