
技术摘要:
本申请提供一种文本相似度的计算方法,包括:通过基于相同的过滤策略,对原始的黑样本库中的文本样本以及新录入的文本样本进行分词处理得到的文本分词,按照多个保持梯度的文本过滤比例分别进行文本分词过滤处理,并使用过滤后剩余的文本分词分别对原始的黑样本库中的 全部
背景技术:
社交应用,通常都会面临内容审核的问题。而一款社交产品,通常可能会有几千万 甚至几亿的用户量,每天每时每刻都有巨大的信息量在交互。因此如何基于已审核出的不 良历史内容,快速的完成各种不良内容的实时线上防控,具有十分重要的意义。 在相关技术中,在基于已审核出的不良历史内容针对各种不良内容进行实时的线 上防控时,通常是基于文本相似度来实现的;比如,可以基于编辑距离或者余弦距离等算 法,计算社交应用产生的文本样本与已审核出每一条包含不良内容的黑样本的文本相似 度,然后通过计算出的文本相似度来完成不良内容的实时线上防控。 然而,通过诸如编辑距离或者余弦距离等算法,计算社交文本产生的文本样本与 每一条黑样本的相似度时,通常都面临着1:N的轮询;因此,当黑样本的数量较多,轮询所有 的黑样本依次进行相似度的计算,从响应速度上看,无法满足实时的线上防控的要求。
技术实现要素:
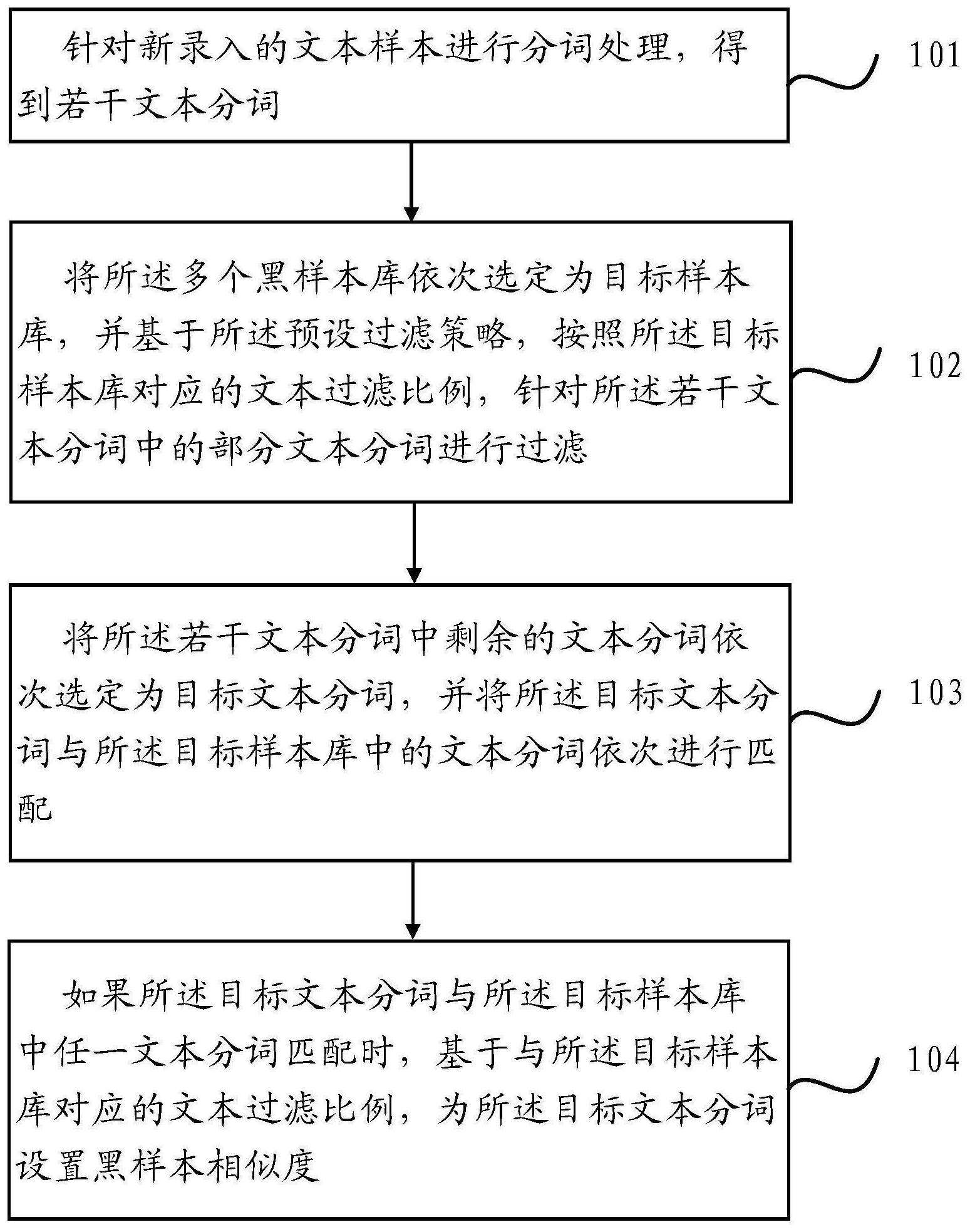
本申请提出一种文本相似度的计算方法,应用于计算机设备,所述计算机设备包 括多个黑样本库;所述多个黑样本库为基于预设过滤策略,针对原始的黑样本库中的部分 文本样本进行过滤后,基于剩余的文本样本创建得到;其中,所述多个黑样本库分别对应不 同的文本过滤比例;所述方法包括: 针对新录入的文本样本进行分词处理,得到若干文本分词; 将所述多个黑样本库依次选定为目标样本库,并基于所述预设过滤策略,按照所 述目标样本库对应的文本过滤比例,针对所述若干文本分词中的部分文本分词进行过滤; 将所述若干文本分词中剩余的文本分词依次选定为目标文本分词,并将所述目标 文本分词与所述目标样本库中的文本分词依次进行匹配; 如果所述目标文本分词与所述目标样本库中任一文本分词匹配时,基于与所述目 标样本库对应的文本过滤比例,为所述目标文本分词设置黑样本相似度。 本申请还提出一种文本相似度的计算装置,应用于计算机设备,所述计算机设备 包括多个黑样本库;所述多个黑样本库为基于预设过滤策略,针对原始的黑样本库中的部 分文本样本进行过滤后,基于剩余的文本样本创建得到;其中,所述多个黑样本库分别对应 不同的文本过滤比例;所述装置包括: 分词模块,针对新录入的文本样本进行分词处理,得到若干文本分词; 过滤模块,将所述多个黑样本库依次选定为目标样本库,并基于所述预设过滤策 略,按照所述目标样本库对应的文本过滤比例,针对所述若干文本分词中的部分文本分词 进行过滤; 匹配模块,将所述若干文本分词中剩余的文本分词依次选定为目标文本分词,并 5 CN 111611786 A 说 明 书 2/12 页 将所述目标文本分词与所述目标样本库中的文本分词依次进行匹配; 设置模块,如果所述目标文本分词与所述目标样本库中任一文本分词匹配时,基 于与所述目标样本库对应的文本过滤比例,为所述目标文本分词设置黑样本相似度。 本申请中,通过基于相同的过滤策略,对原始的黑样本库中的文本样本以及新录 入的文本样本进行分词处理得到的文本分词,按照多个保持梯度的文本过滤比例分别进行 文本分词过滤处理,并使用过滤后剩余的文本分词分别对原始的黑样本库中的文本样本以 及新录入的文本样本进行重构,然后利用文本分词的过滤比例来表征新录入的文本样本与 黑样本的相似度,通过匹配重构后的黑样本库与新录入的文本样本中的文本分词,为新录 入的文本样本进行分词得到的文本分词设置黑样本相似度,可以显著提升在计算新录入的 文本样本与黑样本库中的文本样本的相似度时的计算效率,从而在基于黑样本对新录入的 文本样本进行实时的线上防控时,可以快速的完成针对新录入的文本样本的内容审核,提 高系统的响应速度。 附图说明 图1是本申请一实施例示出的一种文本相似度的计算方法的流程图; 图2是本申请一实施例示出的一种文本相似度算法的整体设计框架图; 图3是本申请一实施例示出的一种对原始的黑样本库中的社交文本进行重构的处 理流程图; 图4是本申请一实施例示出的一种对新录入的社交文本执行相似度打分的处理流 程图; 图5是本申请一实施例示出的一种文本相似度的计算装置的逻辑框图; 图6是本申请一实施例示出的承载所述文本相似度的计算装置的计算机设备所涉 及的硬件结构图。











