
技术摘要:
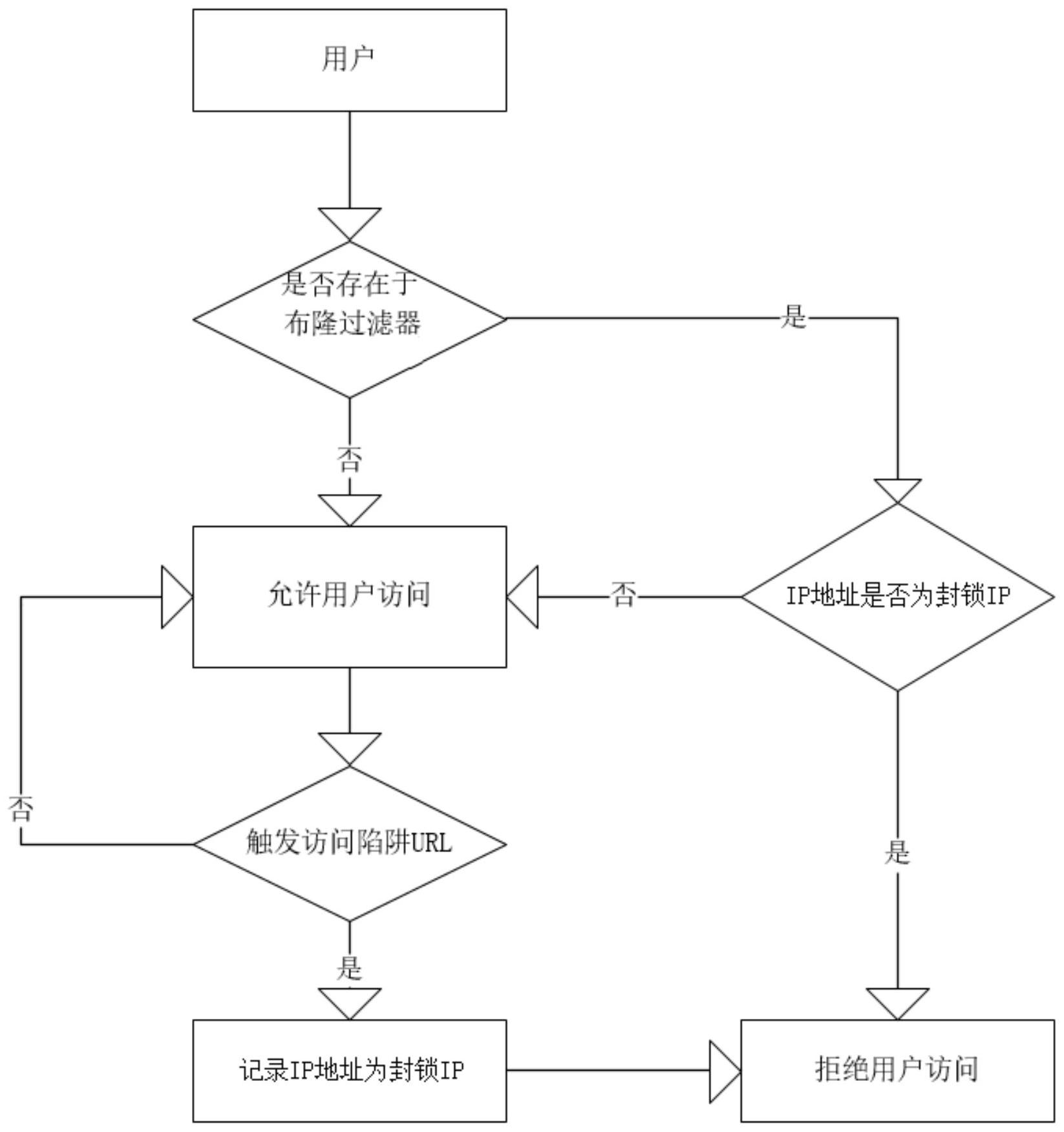
本发明公开了一种爬虫识别拦截方法、设备、存储介质,包括以下步骤:获取用户访问网站的IP地址;获取过滤器的IP列表,并根据所述IP列表判断是否存在所述IP地址;若不存在,则允许用户访问该网站;若存在,则判断该IP地址是否为封锁IP;获取过滤器的已封锁的IP地址列表 全部
背景技术:
在当今大数据时代,互联网信息资源十分丰富,数据已成为企业的核心资产之一。 网络爬虫是按照一定的规则,自动抓取万维网信息的程序或者脚本,寻找数据,搜索引擎的 本质就是一种爬虫。随着开源技术的流行,越来越多的个人开发者都能根据自己的需求开 发爬虫。但对于一些网站而言,这些爬虫带来的访问是无意义且占用资源的,并会带来恶意 爬虫窃取网站数据的风险。 因此,很多网站为了保证网站在提供用户正常访问的同时,也需要对恶意爬虫做 好防范。很多网站都采取IP频率统计的方式防范爬虫,需要在用户访问网站的时候记录下 用户IP的访问时间,并根据一定的规则,计算用户在某个时间段内的访问频率是否可疑。若 频率过高,则对IP进行限制访问,以此来达到反爬的目的。但这种反爬策略只能针对单机爬 虫,对于分布式爬虫来说,只要调度时间设置得合理,一段时间内用一批服务器访问,下一 段时间切换另一批,通过IP频率统计则无法防范此类爬虫。
技术实现要素:
为了克服现有技术的不足,本发明的目的在于提供一种爬虫识别拦截方法、设备、 存储介质,有效解决通过分布式轮询的爬虫爬取网站资源的问题。 本发明的目的之一采用如下技术方案实现: 一种爬虫识别拦截方法,包括以下步骤: 获取用户访问网站的IP地址; 获取过滤器的IP列表,并根据所述IP列表判断是否存在该IP地址;若过滤器的IP 列表不存在该IP地址,则允许用户访问该网站;若过滤器的IP列表中存在该IP地址,则判断 所述该IP地址是否为封锁IP; 获取所述过滤器的已封锁的IP地址列表,判断所述已封锁的IP地址列表中是否存 在所述IP地址,若存在所述IP地址,则该IP地址为封锁IP,拒绝该IP地址访问网站;若已封 锁的IP地址列表中不存在所述IP地址,则该IP地址不是封锁IP,允许该IP地址访问网站; 获取所述IP地址访问网站URL,根据所述网站URL判断所述IP地址是否触发陷阱 URL;若所述IP地址触发所述陷阱URL,则拒绝该IP地址访问网站;若所述IP地址不触发所述 陷阱URL,则允许所述IP地址访问网站。 进一步地,若所述IP地址触发所述陷阱URL,还包括以下步骤: 将所述IP地址添加至已封锁的IP地址列表,并拒绝该IP地址后续访问网站。 进一步地,若所述IP地址触发所述陷阱URL,还包括以下步骤: 将所述IP地址添加至已封锁的IP地址列表,并拒绝该IP地址后续访问网站,返回 3 CN 111614652 A 说 明 书 2/3 页 错误警告信息。 进一步地,所述陷阱URL位于所述网站页面的HTML文本信息中。 进一步地,所述过滤器为布隆过滤器。 本发明的目的之二采用以下技术方案实现: 一种设备,其包括处理器、存储器及存储于所述存储器上并可在所述处理器上运 行的计算机程序,所述处理器执行所述计算机程序时实现如上所述的一种爬虫识别拦截方 法的步骤。 本发明的目的之三采用以下技术方案实现: 一种存储介质,其上存储有计算机程序,所述计算机程序被执行时实现如上所述 的一种爬虫识别拦截方法的步骤。 相比现有技术,本发明的有益效果在于: 本发明提供了一种爬虫识别拦截方法、设备、存储介质,通过在网站页面中设置陷 阱URL,若爬虫程序或脚本触发了陷阱URL,则可拒绝该IP地址访问网站,有效解决通过分布 式轮询的爬虫爬取网站资源的问题。且在执行过程中正常访问用户无感知,能够进一步提 高用户体验,提高反爬虫的有效性且节约反爬虫成本。 附图说明 图1为本发明所提供实施例一的流程示意图; 图2为本发明所提供实施例二的结构示意图。











