
技术摘要:
本发明公开了一种基于高维空间聚类近邻搜索的区域建筑动态负荷预测方法,属于区域建筑负荷预测领域,通过业界广泛认可的建筑能耗计算引擎EnergyPlus,对不同地区下不同业态建筑在不同情境(朝向、围护结构热工参数、室内负荷强度、建筑使用时间表等)下的负荷进行模拟 全部
背景技术:
为了响应政府的号召且适应社会经济的快速发展和城市化进程的稳步推进,以新 区形式进行规划建设并配有区域能源中心的项目越来越多,由于区域集中供能的效率比分 散冷热源高,初投资小,易于维护管理,它已成为实现供能区域目标和可持续发展的优选之 一。 区域供能中的区域负荷包括各建筑叠加的冷热负荷、电负荷和生活热水负荷。其 中电负荷预测对电网规划、发电设备选型及电力检修等至关重要,冷热负荷预测则主要影 响区域供热供冷系统的设计与设备选型。在规划阶段的系统设计及选型中往往针对各类负 荷考虑一定的富余系数,以保证系统的安全运行。但有对已建成的能源站项目调研发现,现 运行的能源站系统设备配置过大,负荷率很低,不能实现节能、高效、环保、经济运行的设计 初衷。究其最根本的原因是负荷预测准确性较差,设计负荷偏大,造成能源站供能侧负荷远 大于实际用户需求侧负荷。 负荷预测对于区域供能有重要的意义,国内外学者也提出了大量的预测方法,大 致可分为三种,面积负荷指标法,正演模型法与数据驱动方法。面积负荷指标法得到的是静 态的负荷结果,不能反映区域中负荷的时间动态特性;正演模型法计算时间较长,对建模人 员专业性要求高;数据驱动方法则完全基于统计学,未将建筑物理性能考虑在内。且由于模 型输出数量限制,现有研究较少讨论全年逐时负荷,而是用典型日逐时负荷/峰值负荷代 替,这种替代使得区域负荷峰值计算结果与真实结果相差较大,浪费了系统容量。
技术实现要素:
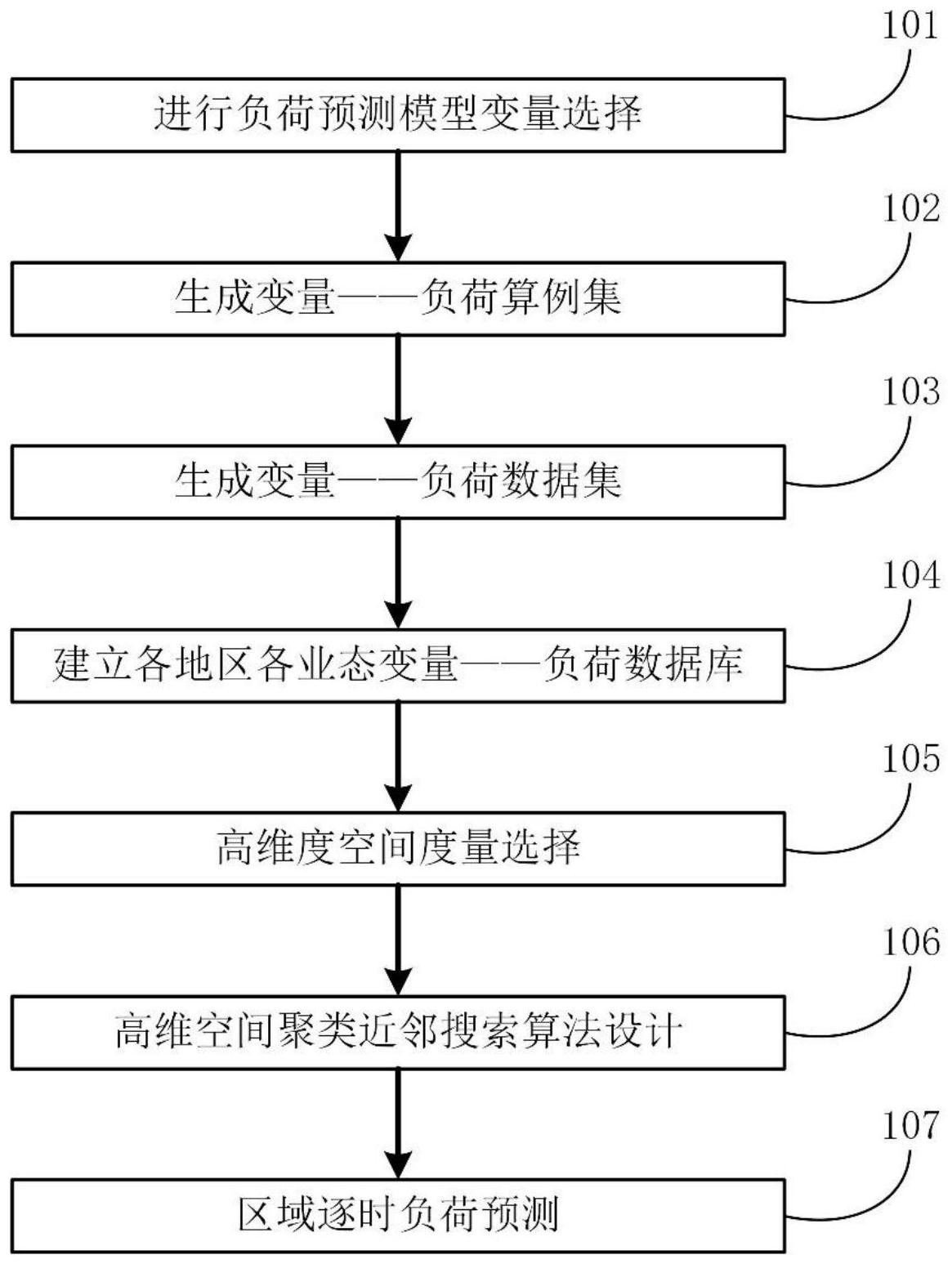
为了解决现有技术中存在的上述问题,本发明提出一种基于高维空间聚类近邻搜 索的区域建筑动态负荷预测方法,通过设计各地区各业态的变量——负荷数据库,结合高 维空间聚类近邻搜索,实现了区域建筑群的全年逐时负荷预测。 本发明解决上述问题所采用的技术方案是:一种基于高维空间聚类近邻搜索的区 域建筑动态负荷预测方法,其特征在于,包括: 变量——负荷数据库设计; 基于高维空间聚类近邻搜索的预测算法设计; 以及结合数据库与算法的区域尺度负荷预测。 建立北京、上海、武汉、重庆、广州五个城市常见典型建筑业态(办公/酒店/商业/ 医院/数据中心)变量——负荷数据库,得到冷、热、电、生活热水负荷数据库,数据库的形式 为sql。 进一步地,变量——负荷数据库设计阶段的负荷预测模型中选择参数依次为体形 4 CN 111612031 A 说 明 书 2/5 页 系数、综合传热系数、夏季室内设定温度、冬季室内设定温度、人员密度、设备功率密度、照 明密度、时刻表,其中前七个参数取四水平,时刻表取三水平; 优选地,采用基于数论中拟蒙特卡洛方法的试验设计方法——均匀设计进行高维 空间填充设计,使试验点在试验范围内均匀充满参数空间,使用蒙特卡罗方法抽取10%试 验点作为变量——负荷算例集。 进一步地,对各城市各业态都分别进行变量——负荷算例集的抽样生成,并作为 负荷数据库中的变量集合,数据库中的每一个变量都代表着该数据库对应的该城市该业态 现实中的一栋建筑。 优选地,各城市各业态的冷、热、电、生活热水负荷数据库中的负荷结果均为 EnergyPlus计算得出,且负荷为全年8760小时逐时负荷,单位均为W/㎡。 优选地,上述各城市各业态的负荷计算与数据库建立,均由编写Python代码实现 EnergyPlus的自动计算与数据库的自动建立。 进一步地,对变量——负荷数据库中的变量进行Kmeans聚类,将变量集合聚为k个 簇,城市与业态不同,k的取值亦不同。 优选地,上述Kmeans聚类中选用的度量为街区距离,街区距离为: 进一步地,对于Kmeans聚类,预先确定分为k个簇,k预设为1,然后每次聚类时k=k 1,将k与聚类性能作图,得到一个聚类性能随k变化的“手肘”线,当k增加,聚类性能增加率 降低的时候,认为此时的k为数据库中变量的最佳分类数。 优选地,Kmeans聚类的性能指标为DB指数与Dunn指数; DB指数(Davies-Bouldin Index,简称DBI): Dunn指数(Dunn Index,简称DI): avg(C)对应于簇内样本间的平均距离,diam(C)对应于簇C内样本间的最远距离, dmin(Ci,Cj)对应于簇与簇最近样本间的距离,dcen(Ci,Cj)对应于簇与簇中心点的距离;DBI 比较的是簇内间距与簇中心间距,DI比较的是簇间最近样本间的距离与簇内最远样本点间 的距离。 优选地,将待预测建筑的参数(体形系数、综合传热系数、夏季室内设定温度、冬季 室内设定温度、人员密度、设备功率密度、照明密度、时刻表)看作为一个高维变量,使用待 预测建筑所在地区对应业态的数据库与算法进行冷、热、电、生活热水的全年逐时负荷预 测。 进一步地,将待预测变量与对应数据库中的N个簇中心进行街区距离的计算与比 较,找出距离最近的簇中心,并在该簇中进行KNN近邻算法,找出距离待预测变量最近的3个 5 CN 111612031 A 说 明 书 3/5 页 邻居变量,通过距离加权得到待预测变量冷、热、电、生活热水的全年逐时负荷预测。 优选地,在KNN近邻算法中,选择距离加权函数为反比例函数为: 进一步地,可以进行区域建筑群的冷、热、电、生活热水的全年逐时负荷预测。 优选地,搜集该区域的各个建筑的参数与建筑面积,得到代表各个建筑的变量,并 根据城市、业态找到各变量对应的数据库,进行算法预测,得到各变量对应的全年逐时负 荷,将各负荷与对应面积相乘,即可得到各建筑的全年逐时总负荷,将各建筑的全年逐时总 负荷再进行加和,即可得到该区域建筑群的全年逐时负荷。 本发明与现有技术相比,具有以下优点和效果:本发明通过业界广泛认可的建筑 能耗计算引擎EnergyPlus,对不同地区下不同业态建筑在不同情境(朝向、围护结构热工参 数、室内负荷强度、建筑使用时间表等)下的负荷进行模拟,形成基于正演模型的数据库,由 于该数据库包含大量典型业态建筑情景,能较好地涵盖实际工程设计情况;在此数据库基 础上,采用高维空间聚类近邻搜索方法,实现快速预测区域全年逐时负荷。将区域内各业态 建筑的全年逐时冷热负荷叠加,即可得到全年峰值冷负荷与峰值热负荷,用于指导设备选 型工作。该方法简单方便,对理论研究领域与实际应用领域都产生了积极的意义。 附图说明 图1是本发明实施例的流程示意图。











