
技术摘要:
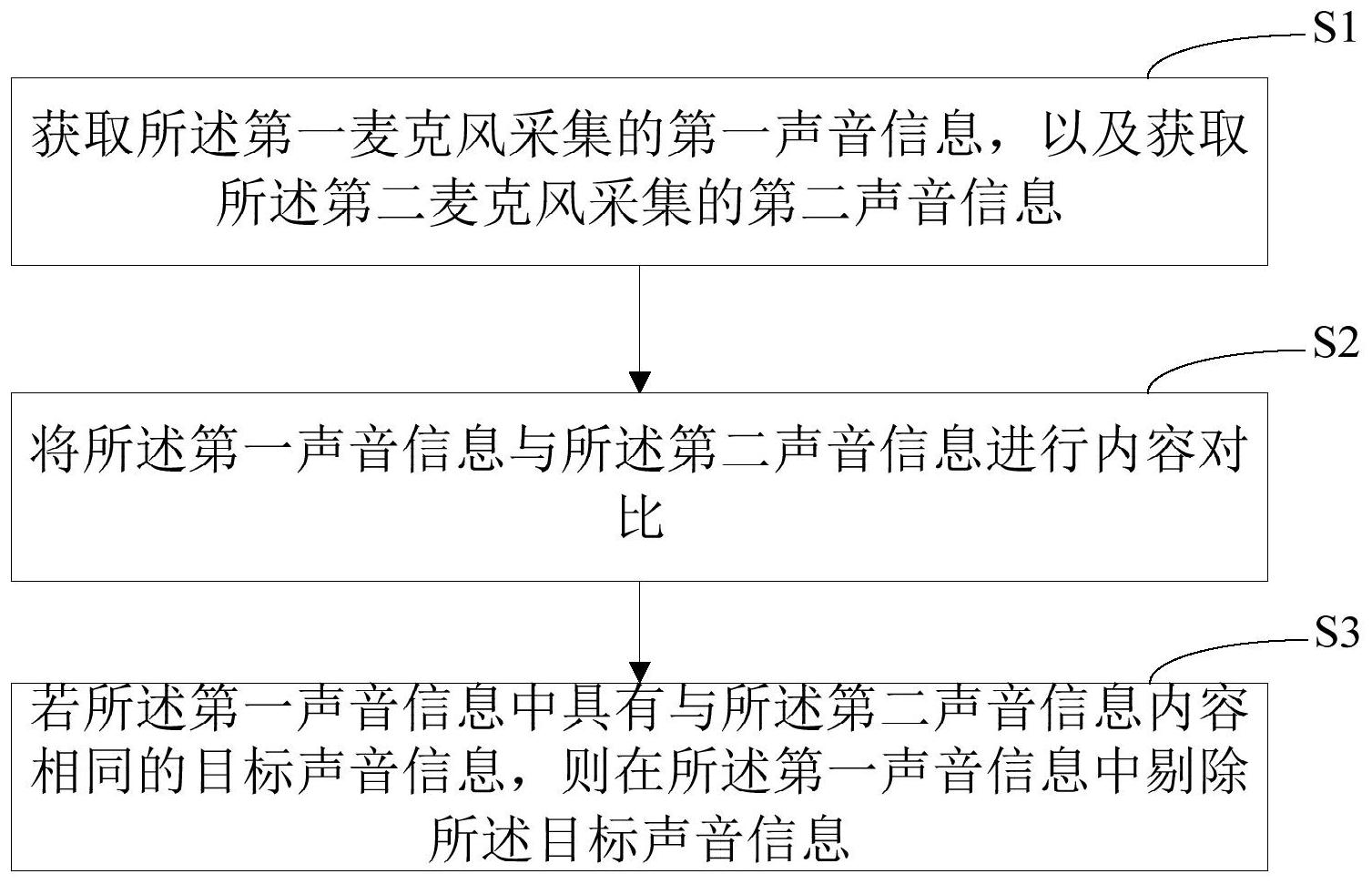
本申请提供一种回声消除方法、装置、计算机设备和存储介质,应用于耳机上,所述耳机包括喇叭以及用于通话的第一麦克风,所述耳机还包括设置于耳机前腔并靠近于所述喇叭的第二麦克风;其中方法包括:获取所述第一麦克风采集的第一声音信息,以及获取所述第二麦克风采集 全部
背景技术:
用户在配戴耳机通话时,耳机麦克风会采集用户说的话通过网络传到对讲端,对 讲端说的话通过对讲端的麦克风采集并经由网络传到用户耳机的左右耳喇叭端,喇叭端发 出的声音信号,一部分被用户耳朵接收,一部分被用户耳机的麦克风接收,并经由网络传递 到对讲端,这样对讲端就听到自己的回声。 现有的耳机回声消除方案中,通过通话降噪算法来进行回声消除,此种方法,对通 话麦克风的密封要求非常高,但是由于种种原因,通话麦克风的密封做的并不好,所以导致 通话过程中回声问题严重。
技术实现要素:
本申请的主要目的为提供一种回声消除方法、装置、计算机设备和存储介质,旨在 为了消除目前通话过程中的回声。 为实现上述目的,本申请提供了一种回声消除方法,应用于耳机上,所述耳机包括 喇叭以及用于通话的第一麦克风,所述耳机还包括设置于耳机前腔并靠近于所述喇叭的第 二麦克风,所述回声消除方法包括以下步骤: 获取所述第一麦克风采集的第一声音信息,以及获取所述第二麦克风采集的第二 声音信息; 将所述第一声音信息与所述第二声音信息进行内容对比; 若所述第一声音信息中具有与所述第二声音信息内容相同的目标声音信息,则在 所述第一声音信息中剔除所述目标声音信息。 进一步地,所述将所述第一声音信息与所述第二声音信息进行内容对比的步骤, 包括: 对所述第一声音信息以及第二声音信息分别进行文字识别,得到对应的第一文字 内容以及第二文字内容; 对比所述第一文字内容以及第二文字内容判断是否具有相同的语句;若具有,则 判定所述第一声音信息中具有与所述第二声音信息内容相同的目标声音信息。 进一步地,所述将所述第一声音信息与所述第二声音信息进行内容对比的步骤之 后,包括: 若所述第一声音信息中不具有与所述第二声音信息内容相同的目标声音信息,则 输出所述第一声音信息。 进一步地,所述将所述第一声音信息与所述第二声音信息进行内容对比的步骤, 包括: 4 CN 111601201 A 说 明 书 2/9 页 将所述第一声音信息输入至预设的声音分类模型中,以将所述第一声音信息中不 同用户的声音进行分离,得到各个用户对应的分离声音信息; 将各个用户对应的分离声音信息以及所述第二声音信息分别输入至预设的文本 识别模型中,识别得到对应的文本; 将各个分离声音信息分别对应的文本与所述第二声音信息对应的文本进行对比; 若任意一个分离声音信息对应的文本与所述第二声音信息对应的文本相同,则判定所述第 一声音信息中具有与所述第二声音信息内容相同的目标声音信息。 进一步地,所述将所述第一声音信息与所述第二声音信息进行内容对比的步骤, 包括: 将所述第一声音信息输入至预设的声音分类模型中,以将所述第一声音信息中不 同用户的声音进行分离,得到各个用户对应的分离声音信息; 将各个用户对应的分离声音信息以及所述第二声音信息分别输入至预设的声音 特征提取模型中,得到各个所述分离声音信息以及第二声音信息对应的特征向量; 分别计算各个所述分离声音信息对应的特征向量与所述第二声音信息对应的特 征向量之间的相似度; 若任意一个相似度大于阈值,则判定所述第一声音信息中具有与所述第二声音信 息内容相同的目标声音信息。 进一步地,所述声音特征提取模型的训练过程为: 获取语音训练数据;其中,所述语音训练数据为单个训练词及其对应的音频训练 数据,所述音频训练数据包括多个依次排序的训练帧数据; 按照所述训练帧数据在所述音频训练数据中的顺序,依次将每一个训练帧数据输 入至预设的卷积神经网络中,提取每一个所述训练帧数据对应的向量; 将所有训练帧数据对应的向量进行求和,得到和向量; 获取所述语音训练数据中单个训练词的词向量; 将所述和向量与所述词向量进行拟合,并训练所述卷积神经网络的网络参数,得 到所述声音特征提取模型。 本申请还提供了一种回声消除装置,应用于耳机上,所述耳机包括喇叭以及用于 通话的第一麦克风,所述耳机还包括设置于耳机前腔并靠近于所述喇叭的第二麦克风,所 述回声消除装置包括: 获取单元,用于获取所述第一麦克风采集的第一声音信息,以及获取所述第二麦 克风采集的第二声音信息; 对比单元,用于将所述第一声音信息与所述第二声音信息进行内容对比; 剔除单元,用于若所述第一声音信息中具有与所述第二声音信息内容相同的目标 声音信息,则在所述第一声音信息中剔除所述目标声音信息。 进一步地,所述对比单元包括: 第一对比子单元,用于对所述第一声音信息以及第二声音信息分别进行文字识 别,得到对应的第一文字内容以及第二文字内容; 第一判定子单元,用于对比所述第一文字内容以及第二文字内容判断是否具有相 同的语句;若具有,则判定所述第一声音信息中具有与所述第二声音信息内容相同的目标 5 CN 111601201 A 说 明 书 3/9 页 声音信息。 进一步地,所述回声消除装置还包括: 输出单元,用于若所述第一声音信息中不具有与所述第二声音信息内容相同的目 标声音信息,则输出所述第一声音信息。 进一步地,所述对比单元,包括: 第二对比子单元,用于将所述第一声音信息输入至预设的声音分类模型中,以将 所述第一声音信息中不同用户的声音进行分离,得到各个用户对应的分离声音信息; 第一输入子单元,用于将各个用户对应的分离声音信息以及所述第二声音信息分 别输入至预设的文本识别模型中,识别得到对应的文本; 第二判定子单元,用于将各个分离声音信息分别对应的文本与所述第二声音信息 对应的文本进行对比;若任意一个分离声音信息对应的文本与所述第二声音信息对应的文 本相同,则判定所述第一声音信息中具有与所述第二声音信息内容相同的目标声音信息。 进一步地,所述对比单元,具体用于: 将所述第一声音信息输入至预设的声音分类模型中,以将所述第一声音信息中不 同用户的声音进行分离,得到各个用户对应的分离声音信息; 将各个用户对应的分离声音信息以及所述第二声音信息分别输入至预设的声音 特征提取模型中,得到各个所述分离声音信息以及第二声音信息对应的特征向量; 分别计算各个所述分离声音信息对应的特征向量与所述第二声音信息对应的特 征向量之间的相似度; 若任意一个相似度大于阈值,则判定所述第一声音信息中具有与所述第二声音信 息内容相同的目标声音信息。 进一步地,所述声音特征提取模型的训练过程为: 获取语音训练数据;其中,所述语音训练数据为单个训练词及其对应的音频训练 数据,所述音频训练数据包括多个依次排序的训练帧数据; 按照所述训练帧数据在所述音频训练数据中的顺序,依次将每一个训练帧数据输 入至预设的卷积神经网络中,提取每一个所述训练帧数据对应的向量; 将所有训练帧数据对应的向量进行求和,得到和向量; 获取所述语音训练数据中单个训练词的词向量; 将所述和向量与所述词向量进行拟合,并训练所述卷积神经网络的网络参数,得 到所述声音特征提取模型。 本申请还提供一种计算机设备,包括存储器和处理器,所述存储器中存储有计算 机程序,所述处理器执行所述计算机程序时实现上述任一项所述方法的步骤。 本申请还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程 序被处理器执行时实现上述任一项所述的方法的步骤。 本申请提供的回声消除方法、装置、计算机设备和存储介质,应用于耳机上,所述 耳机包括喇叭以及用于通话的第一麦克风,所述耳机还包括设置于耳机前腔并靠近于所述 喇叭的第二麦克风;获取所述第一麦克风采集的第一声音信息,以及获取所述第二麦克风 采集的第二声音信息;将所述第一声音信息与所述第二声音信息进行内容对比;若所述第 一声音信息中具有与所述第二声音信息内容相同的目标声音信息,则在所述第一声音信息 6 CN 111601201 A 说 明 书 4/9 页 中剔除所述目标声音信息。本申请通过内容对比消除第一声音信息中的回声信息,避免回 声干扰。 附图说明 图1是本申请一实施例中回声消除方法步骤示意图; 图2是本申请一实施例中耳机辅助电路结构示意图; 图3是本申请一实施例中回声消除装置结构框图; 图4为本申请一实施例的计算机设备的结构示意框图。 本申请目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。











