
技术摘要:
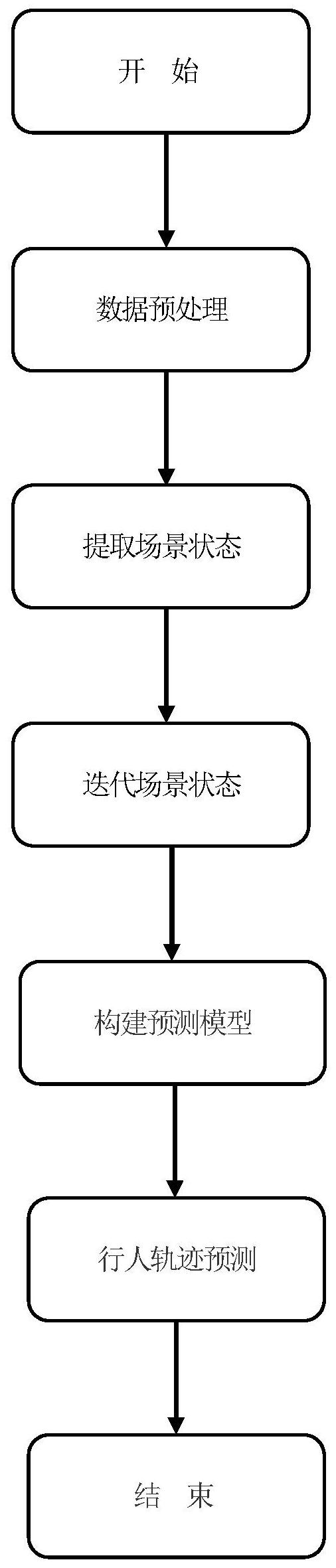
一种基于场景状态迭代的门循环单元网络行人轨迹预测方法,由数据预处理、提取场景状态、迭代场景状态、构建预测模型、行人轨迹预测步骤组成。本发明采用对采集的行人视频数据集经坐标规范化和数据增强处理,用门循环单元网络进行编码,确定场景中行人之间的空间相对位 全部
背景技术:
随着计算机技术的快速演变和发展,计算机在计算速度上呈几何倍数的提高。得 益于计算机设备在计算力提升方面的大幅增强,许多基于序列的预测也变得越来越普及。 行人轨迹作为一项典型的序列问题,有着广阔的应用空间,如自动汽车驾驶、无人送货机器 人及交通实时监测等。 现有行人轨迹预测方法大致分为社会性交互、运动模式监测和基于深度学习法三 类,社会性交互方面有代表性的是社会力模型、高斯交互过程等,社会力模型构造了引力- 斥力模型,高斯交互过程引入了潜在交互网络,两种方法均在特定环境下模拟了人群的相 互作用,发挥出了不俗的表现,但其缺点是受制于固定场景。运动模式监测方面以聚类方法 为主要预测方法,但该方法主要面向于预测对静止物体进行避障的运动模式轨迹,未实现 人群的交互。基于深度学习法主要运用了循环神经网络的方法,将人的轨迹视作一系列基 于固有时序的数据链,最具代表性的是Social-LSTM模型,该模型通过社交池化操作,较好 地描述了一个基于社交状态的行人网络,但在行人时间步的状态控制存在局限性,没有表 现出行人状态变化的实时性。
技术实现要素:
本发明所要解决的技术问题在于克服上述现有技术的不足,提供一种运算复杂度 低、预测准确率高的基于场景状态迭代的门循环单元网络行人轨迹预测方法。 解决上述技术问题所采用的技术方案由下述步骤组成: (1)数据预处理 从公开数据集ETH和数据集UCY中提取行人轨迹数据,包含5个子数据集及行人的 非线性轨迹,其中每一个行人i在时间t的二维坐标从数据集ETH和数据集UCY中提取,记作 所有行人坐标数据经过坐标规范化和数据增强方法进行处理。 (2)提取场景状态 1)分别将视频时刻t中每一个行人i用一个单独的门循环单元网络进行编码,在时 刻t中所有的行人i用相同的方法进行编码,行人i的当前位置信息和门循环单元网络的隐 含层状态输入到门循环单元网络,采用张量 按式(1)确定行人i在时刻t的位置信息: 其中φ(·)是含偏置ReLU非线性函数,We是该函数的权重矩阵,be是该函数的偏置 矩阵。 2)按式(2)确定行人i在t时刻的隐含层状态: 4 CN 111553232 A 说 明 书 2/6 页 其中, 是行人i在门循环单元网络在时刻t-1的隐含层状态,WG是门循环单元 网络输入的内部权重矩阵,bG是门循环单元网络输入的内部偏置矩阵。 3)按式(3)确定场景中行人之间的空间相对位置关系 其中φl是ReLU非线性函数,Wl是该函数的权重, 和 分别表示在时刻 t行人i和行人j的空间坐标,i和j为有限的正整数,i≠j。 4)按式(4)、(5)确定行人之间关系的特征矩阵 其中σF是含偏置Sigmoid非线性函数,WF是该函数的权重矩阵,bF是该函数的偏置 矩阵。 5)按式(6)确定场景中行人的注意力 其中Wα是Softmax函数的权重矩阵。 (3)迭代场景状态 按式(7)、(8)对式(2)获取的行人隐含层状态进行迭代,得更新后的状态 其中,*表示Hadamard积,N是场景内出现的所有行人个数、为有限的正整数,Wh为 系数矩阵,z表示门循环单元中的更新门,σz是该门中Sigmoid非线性函数,Wz是该函数的权 重矩阵,bz是该函数的偏置矩阵。 (4)构建预测模型 按照式(9)确定行人i在时刻t 1的预测坐标 其中W表示已完全学习的参数矩阵。 结合数据集ETH和数据集UCY提供的坐标序列,以时刻tob为观察起始时刻,以时刻 ts为观察结束时刻,确定一个完整的观察步长周期P: P=ts-tob (10) 将步长周期P内场景状态中所有的信息传递到门循环单元网络,并采用迭代场景 状态步骤(3)和式(9)预测出时刻ts 1的行人坐标,以时刻tob 1作为观测起始时刻,以时刻 ts 1作为观察结束时刻,通过该方法预测出时刻ts 2的行人坐标,继续采用该方法预测,直 到预测出时刻ts tpred的行人坐标,构建成预测模型。 (5)行人轨迹预测 5 CN 111553232 A 说 明 书 3/6 页 对数据集ETH和数据集UCY使用留一法对预测模型进行反复训练,最小化均方误差 MSE,按式(11)确定预测轨迹与真实轨迹的均方误差MSE: 得到最佳的训练模型参数,将最佳的训练模型参数应用到训练模型中,输入需要 进行预测的坐标数据,预测出行人轨迹。 在本发明的数据预处理步骤(1)中,所述的坐标规范化方法为:在观测时间长度 内,以行人i的初始坐标为原点。所述的数据增强方法为:将对应帧视频图像进行随机旋转。 在本发明的构建预测模型步骤(4)中,所述的观察步长周期P的取值范围为:P∈ [5,10];所述的tpred的取值范围为:tpred∈[8,12]。 本发明采用对采集的行人视频数据集经过坐标规范化和数据增强处理,用门循环 单元网络进行编码,确定场景中行人之间的空间相对位置关系以及场景中行人的注意力, 对获取的行人隐含层状态进行迭代,得更新后的状态,构建预测模型,采用留一法对预测模 型进行反复训练,得到最佳的训练模型参数,将最佳的训练模型参数应用到训练模型中,输 入需要进行预测的坐标数据,预测出行人轨迹。这种方法,有效地利用场景内提取的状态且 不受环境制约,对场景内行人之间的交互状态进行准确地确定,充分地考虑到场景内行人 之间的互动,将行人之间互动的结果以实时修正行人的隐含层状态,获得行人预测轨迹,接 近于行人的真实轨迹。本发明具有方法简单、运算复杂度低、预测准确率高等优点,可用于 无人驾驶车对行人运动轨迹进行预测,无人驾驶车辆可避开行人,也可用于其它需要预测 行人运动轨迹的技术领域。 附图说明 图1是本发明实施例1的流程图。











