
技术摘要:
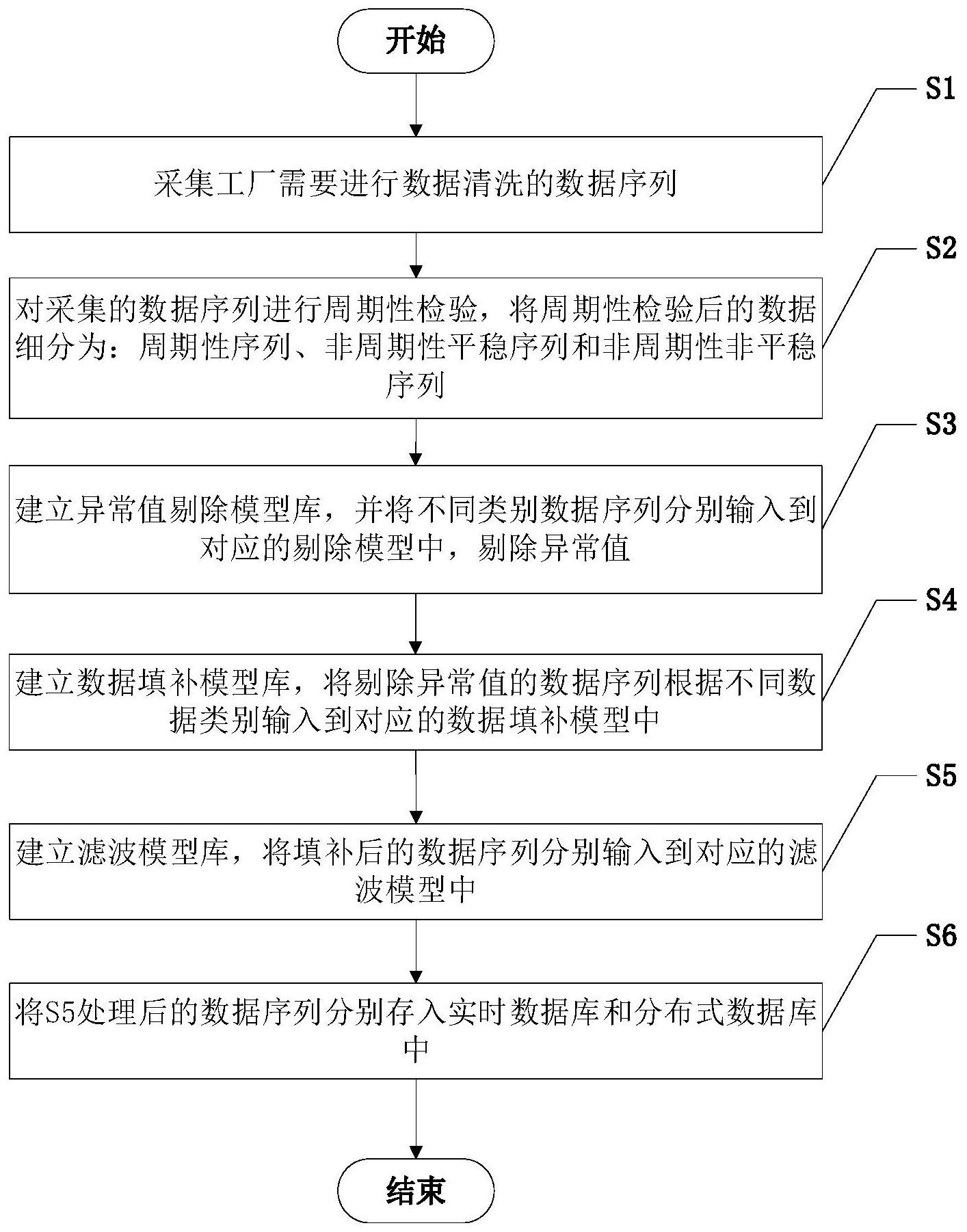
本发明公开了基于工业用电大数据的数据清洗的集成方法,包括下述步骤:S1、采集工厂需要进行数据清洗的数据序列;S2、对采集的数据序列进行周期性检验,将周期性检验后的数据细分为:周期性序列、非周期性平稳序列和非周期性非平稳序列;S3、建立异常值剔除模型库,并 全部
背景技术:
工业的电耗占了全社会用电的70%以上,为了实现到2030年中国单位GDP的二氧 化碳排放,要比2005下降60%到65%。因此,减少工业用电是十分必要的。 为了减少工业用电,需要建立一系列的智能优化模型,而数据质量决定了优化模 型的好坏,因此,保证数据质量是十分重要的。当前,工业对用电数据的采集点比其他的方 面要全面,大型的工业对用电数据已经有了一定的沉淀。然而由于测量问题、通讯问题断、 生产环境等原因,数据存在噪声、异常、空缺、失真等问题。因此,为了提高数据质量,需要对 沉淀的工业用电大数据进行数据清洗。 本发明提出的一种基于工业用电大数据的数据清洗的集成方法,可以普遍用于各 种大型工业的用电大数据的数据清洗,帮助提高数据质量,为后续建立用电优化模型提供 可靠的保证。
技术实现要素:
为解决现有技术中存在的问题,本发明提供了一种基于工业用电大数据的数据清 洗的集成方法,解决了以往方法降低数据质量,无法为后续建立用电优化模型提供可靠的 保证的问题。 本发明采用的技术方案是,一种基于工业用电大数据的数据清洗的集成方法,包 括下述步骤: S1、采集工厂需要进行数据清洗的数据序列; S2、对采集的数据序列进行周期性检验,将周期性检验后的数据细分为:周期性序 列、非周期性平稳序列和非周期性非平稳序列; S3、建立异常值剔除模型库,并将不同类别数据序列分别输入到对应的剔除模型 中,剔除异常值; S4、建立数据填补模型库,将剔除异常值的数据序列根据不同数据类别输入到对 应的数据填补模型中; S5、建立滤波模型库,将填补后的数据序列分别输入到对应的滤波模型中; S6、将S5处理后的数据序列分别存入实时数据库和分布式数据库中。 优选地,S2包括以下子步骤: S21、利用小波分析法对部分序列进行拆分,分析拆分后的序列是否具有周期性, 若没有,则分入非周期性这一类别中;若有,则分入周期性这一类别; 所述小波分析法的计算公式为: 4 CN 111582593 A 说 明 书 2/5 页 其中,a为尺度,控制小波函数的伸缩;τ为平移量;f(t)为目标信号;ψ(t)为基本频 率特性; S22、对不是周期性序列进行统计学分析,分析一年的数据,且判断是否95%的数 据都存在于一个固定范围内,若是,则将这类数据归类到非周期性、平稳序列中;若否,则归 类到非周期性序列、非平稳序列中。 优选地,S3包括以下子步骤: S31、利用主成分分析法对平稳生产的数据序列进行异常值标记和剔除,所述主成 分分析法的计算公式为: 其中,a1i,a2i,……,api(i=1,……,m)为X的协方差阵Σ的特征值所对应的特征向 量, 是原始变量经过标准化处理的值; 变量标准化处理的公式为: 其中, 为 标准化后的数据,Zmin为一段时间内的Zx的最小值,Zmax为 一段时间内的Zx的最大值; S32、采用箱线图的方法对非周期性非平稳序列进行异常值剔除和标记; S33、对非周期性平稳序列进行排异,当超过或者低于某个设定数值时,进行异常 值剔除; S34、根据数据序列的周期性对具有周期性的数据序列进行异常值剔除。 优选地,S4包括以下步骤: S41、判断所需填补的数据序列是否为非周期性、不平稳的数据序列,若是,则判断 其相邻空缺值的长度,若大于1,则输入空缺值之前的一段连续的数据序列到BP神经网络进 行模型训练; S42、对空缺值进行预测,用预测值对数据序列对应的空缺进行填补; 所述BP神经网络的核心计算公式为: yjk=f(w1j×oj ··· wij×oj ··· wmj×oj bj) 其中,f表示隐藏层的激活函数,j表示隐藏层的节点个数,oj表示隐藏层的第j个 神经元的输出值,wij表示输入层的第i个神经元与隐藏层的第j个神经元的连接权值; S43、若长度等于1,则采用最近邻插值法进行数据填补; S44、利用数据序列周期性规则对具有周期性的数据序列进行数据填补。 优选地,S5包括以下子步骤: S51、对具有周期性的数据序列和平稳的数据序列进行滑动平均滤波,所述滑动平 均滤波算法的计算公式为: 5 CN 111582593 A 说 明 书 3/5 页 其中,f(t)为时间为t时的滤波结果,y(i)为时间为i时刻的采样数据,n为滤波长 度; S52、对不平稳、非周期的序列进行卡尔曼滤波,所述卡尔曼滤波整个过程的公式 为: X(k|k-1)=A×X(k-1|k-1) B×U(k) P(k|k-1)=A×P(k-1|k-1)×A′ Q X(k|k)=X(k|k-1) Kg(k)*(Z(k)-H×X(k|k-1)) Kg(k)=P(k|k-1)×H′/(H×P(k|k-1)×H′ P(k|k)=(I-Kg(k)×H)×P(k|k-1) 其中,X(k|k-1)是利用上一状态预测的结果,X(k-1|k-1)是上一状态最优的结果; U(k)为现在状态的控制量,如果没有控制量,它的值为0;P表示协方差;A表示状态转移矩 阵;Q是系统过程的协方差;Z(k)是观测值的平均数;Kg为卡尔曼增益。 本发明基于工业用电大数据的数据清洗的集成方法有益效果如下: 本发明提出的一种基于工业用电大数据的数据清洗的集成方法,可以普遍用于各 种大型工业的用电大数据的数据清洗,帮助提高数据质量,为后续建立用电优化模型提供 可靠的保证。 附图说明 图1是本发明基于工业用电大数据的数据清洗的集成方法的流程图。 图2是本发明基于工业用电大数据的数据清洗的集成方法的结构图。 图3是本发明基于工业用电大数据的数据清洗的集成方法的某大型生活用纸企业 某分厂的总用电的原始数据和清洗后数据的对比图。











