
技术摘要:
本发明提供一种大数据处理方法、设备、计算机系统及存储介质,将数据存储于数据库中,提取出数据库中的非结构化数据和缺失数据,将非结构化数据整理成结构化数据,并将缺失数据进行补齐加工得到已加工后数据,将已加工数据构建出因子库,对因子库进行去趋势化操作和标 全部
背景技术:
在计算机技术的运用中经常需要将人工加工过的数据作为输入,对此会依赖大量 人力资源,而在工作中需要的信息和数据都庞多且繁杂,同时数据源也很广泛,但是现有的 系统往往只能读取已有的报表中信息数据,对于其它需要进行简单判断和处理的其它信 息,由于未被加工为格式化数据信息而无法被采集,只能在收集后人工总结进行人工录入 系统。如果较多数据需要人工输入和判断,就会大大降低系统的效率和覆盖面,当工作中出 现新的信息时,除非人工介入将信息补齐,不然也无法对这些新的信息做出反馈。 尤其是各种数据应用于信用评级时,传统评级手段往往需要很多信息来达成,通 常需要大量人力资源来简单加工数据作为输入,由于信息源的多样性使得数据的处理尤为 重要,而评级需要的信息和数据庞多且繁杂,数据源也非常广泛,也会造成数据摄取的不 便,各种不同数据的提取出有效信息使得数据处理变得复杂,同时还得保证在数据处理的 转换过程中的准确度,需要在信息收集后将观点进行总结,然后人工录入系统,使得处理过 程更长,花费更多的时间,无法满足当下对信息处理的要求。
技术实现要素:
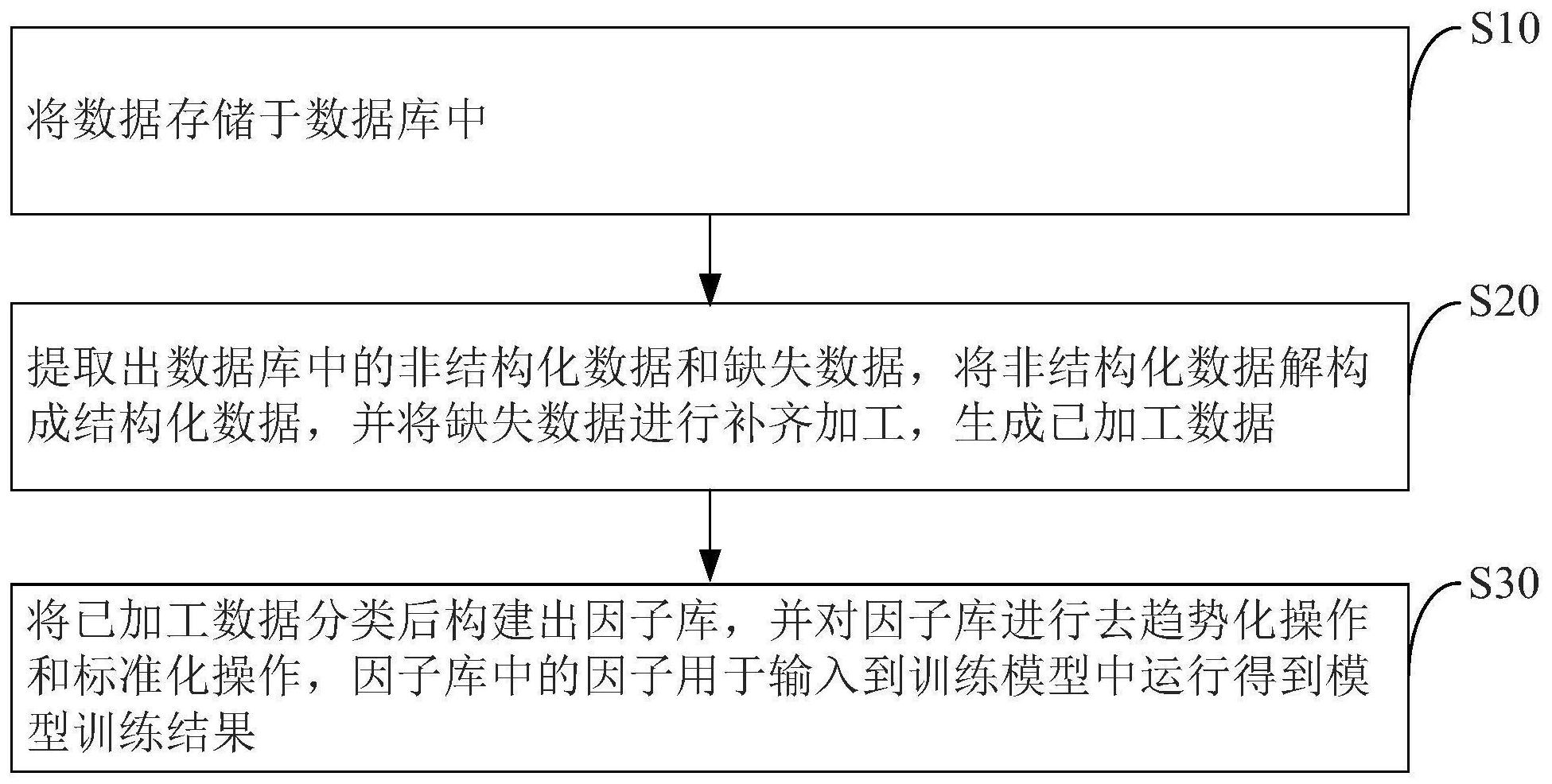
本发明的目的在于提供一种数据处理方法、设备、计算机系统及存储介质,以解决 上述现有技术中的问题。 为了实现上述目的,本发明提供一种数据处理方法,包括以下步骤: 将数据存储于数据库中; 提取出数据库中的非结构化数据和缺失数据,将非结构化数据解构成结构化数 据,并将缺失数据进行补齐加工,生成已加工数据; 将已加工数据分类后构建出因子库,对因子库进行去趋势化操作和标准化操作, 因子库中的因子用于输入到训练模型中运行得到模型训练结果。 进一步地,将数据库中非结构化数据解构成结构化数据包括采用文本挖掘、光学 字符识别和语义分析解构数据信息,将非结构化数据整理成结构化数据。 进一步地,将数据存储于数据库中采用的技术包括利用爬虫技术和大数据技术。 进一步地,去趋势化操作采用将数据减去一条最小二乘的拟合直线、平面或曲面, 使去趋势后的数据均值为零。 进一步地,标准化操作将因子的极大值与极小值做处理,界定出因子的上下限。 进一步地,对缺失数据进行补齐加工的方法包括采用统计学原理和机器学习方法 进行填充,填充的数据值包括默认值、均值、中位数、众数、上下条的数据、插值得到的数据、 邻近算法数据或预测值。 3 CN 111581193 A 说 明 书 2/8 页 进一步地,还包括对因子库中的因子进行分析,采用的方法包括重心法、影像分析 法、最大似然解、最小平方法、阿尔发抽因法或拉奥典型抽因法。 为了实现上述目的,本发明提供一种数据处理设备,包括数据采集模块、数据加工 模块和数据处理模块,数据采用模块用于将数据存储于数据库中,数据加工模块用于提取 出数据库中的非结构化数据和缺失数据,将非结构化数据解构成结构化数据,并将缺失数 据进行补齐加工,生成已加工数据,数据处理模块用将已加工数据分类后构建出因子库,并 对因子库进行去趋势化操作和标准化操作,因子库中的因子用于输入到训练模型中运行得 到模型训练结果。 为了实现上述目的,本发明还提供一种计算机系统,其包括多个计算机设备,各计 算机设备包括存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,所 述多个计算机设备的处理器执行所述计算机程序时共同实现前述方法的步骤。 为了实现上述目的,本发明还提供一种计算机可读存储介质,存储介质上存储有 计算机程序,所述存储介质存储的所述计算机程序被处理器执行时实现前述方法的步骤。 通过采用上述技术方案,本发明相对于现有技术具有如下有益效果: 本发明提供了数据处理方法、设备、计算机系统及存储介质,通过将采集到数据库 中的非结构化数据解构成结构化数据,并对于缺失数据进行补充加工,结构化数据有助于 数据后续的整理,同时防止缺失数据造成的误差,从而减少了非系统性的数据输入错误,保 证准确性,通过将已加工数据构建出因子库对数据进行分类整合,因子库中的因子输入到 训练模型中运行得到模型训练结果,通过因子库提高数据处理的工作效率和覆盖面。 附图说明 图1为本发明数据处理方法的流程图; 图2为本发明数据处理设备的一个实施例的结构框图; 图3为本发明计算机设备的一个实施例的硬件架构图。











