
技术摘要:
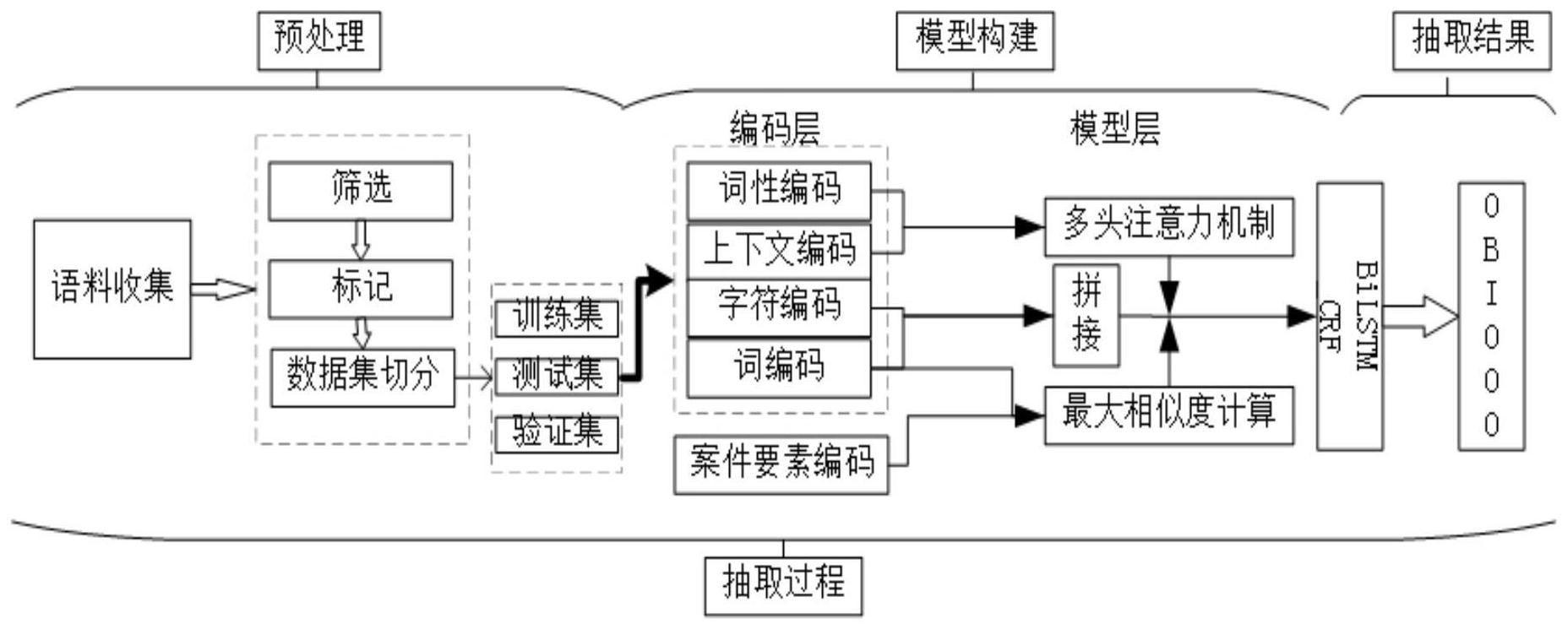
本发明涉及基于多头注意力机制的涉案微博评论的评价对象抽取方法,首先收集涉案微博正文和微博评论;标记涉案微博评论的评价对象;获取涉案微博评论的字符向量、获取词向量、名词词性相关的词性向量、上下文向量和案件要素向量;将获取的字符向量和词向量进行拼接,并 全部
背景技术:
随着自媒体时代的到来、我国新媒体的蓬勃发展和网络舆情的深入,部分法院所 审理的焦点案件在网络上迅速发酵,引发社会的广泛争议,甚至左右司法审判,严重影响社 会稳定。在此背景下,国家也在推行智慧法院的建设,司法部门通过实时有效的掌握并正确 引导网络舆情有助于确保法院依法独立行使审判权,维护社会公平正义。而微博作为社会 大众自由评论的社交媒体之一,其用户量庞大,发展较快,其中不少司法相关的案件会在微 博中引起激烈讨论。因此本文采用微博中的涉案事件,即涉案微博作为本文的研究重点。故 涉案微博评论的评价对象抽取旨在:针对于案件相关的微博话题评论,将评论中的评价对 象抽取出来,为涉案舆情的发展趋势预测做基础性工作。
技术实现要素:
本发明提供了基于多头注意力机制的涉案微博评论的评价对象抽取方法,以用于 解决目前涉案微博评论中大众评论的评价对象与涉案不相关的问题和大众在对涉案微博 评论的评价对象进行评论时表述不一致的问题。 本发明的技术方案是:基于多头注意力机制的涉案微博评论的评价对象抽取方 法,所述方法的具体步骤如下: Step1、收集涉案微博正文和微博评论,对微博评论进行去重、筛选; 作为本发明的优选方案,所述Step1中,使用Scrapy作为爬取工具,模仿用户操作, 登录微博,根据页面数据的XPath路径制定模板获取涉及案件的微博正文和微博评论。 此优选方案设计是本发明的重要组成部分,主要为本发明收集语料过程,为本发 明抽取微博评论中的评价对象提供了数据支撑。 Step2、根据微博正文所涉及的案件,对筛选后的微博评论设置该案件的案件要 素,标记涉案微博评论的评价对象,将标记好的微博评论语料按比例分为训练语料、测试语 料和验证语料; Step3、获取涉案微博评论的字符向量,并通过jieba工具对标记后的微博评论进 行分词和词性标注,然后获取词向量、名词词性相关的词性向量、上下文向量和案件要素向 量; Step4、将获取的字符向量和词向量进行拼接,并采用多头注意力机制获取词性向 量和上下文向量的相关性,同时计算最大的案件要素和词性向量的相似概率权重; Step5、将获取得到的拼接向量、相关性权重和最大相似度概率权重进行点乘,得 到的结果作为BiLSTM模型的输入,然后经过条件随机场CRF得到最后的序列标签,即抽取结 果。 3 CN 111581474 A 说 明 书 2/7 页 作为本发明的优选方案,所述Step2的具体步骤为: Step2.1、涉案微博评论的评价对象的标注体系采用了json格式的标记文本,通过 json格式的文件,对涉案微博评论进行B(begin)、I(inside)和O(outside)序列标注,其中B (begin)表示评价对象的起始位置,I(inside)表示评价对象的内容,O(outside)表示微博 评论中的其他部分,即标记出评价对象,并保存成json格式的文件; Step2.2、将标记的数据集按照8:1:1的比例切分为训练集、测试集和验证集; 其中,涉及到的案件要素包括何事、何时、何地、何物和何人。 作为本发明的优选方案,所述Step3的具体步骤为: Step3.1、采用jieba工具对标记后的微博评论进行分词,并进行词性标注,通过分 词后,根据已有的微博词向量,将微博的一句评论用微博词向量进行表征。同时,对于需要 抽取的评价对象一般是一些名词性实体,因此通过jieba根据对名词性相关的实体选择出 来,然后通过微博将选择出来的名词性相关的词性表征出来; Step3.2、根据目前现有的微博词向量,获取得到字符向量,以及分词后的词向量, 名词词性相关的词性向量和上下文向量; Step3.3、根据已有的微博向量获取案件要素的向量。 由图2可以看出,给定一句涉案微博评论的评论C={c1 ,c2 ...cm} (S={w1 , w2...wT}) ,和案件要素A={a1,a2...an},其中ci表示一句评论中的第i个字,wi表示一句评 论中第i个词,ai表示评论涉及的第i个案件要素。通过中文分词工具jieba可以将一句话切 分成若干个词,同时利用其词性标注功能,将每句评论中名词相关的词标记出来,得到词性 ePOS={n1,n2...np}。字符嵌入和词嵌入分别将构成评论的字和词表征到高维向量空间中, 获得微博评论的最终表征X={x1,x2,...xT},其中字和字符都用已经预训练好的微博中文 词向量来表征,POS是词性标记的简称,part of speech。 此优选方案设计是本发明的重要组成部分,主要为本发明提供向量编码的过程, 结合微博词向量,进而提升模型的性能。 本发明利用双向长短记忆神经网络预测抽取评价对象,通过多头注意力机制计算 词性向量和上下文的相关性,通过最大相似度概率权重计算案件要素和词向量的相似度, 再输入到双向长短记忆神经网络,最后经过条件随机场预测出评价对象;其中: 作为本发明的优选方案,所述Step4的具体步骤为: Step4.1、将得到的字符向量和词性向量通过两个高速网络分别输出两个长度相 同的序列,然后再进行拼接; Step4.2、将得到上下文向量和词性向量根据多头注意力机制的定义,即把上下文 与词性表征作为输入,且都有自己的原始Value,将名词词性特征作为Query,上下文作为 Key,并将Query与各个Key的相似性作为权重,计算出多头注意力机制的相关性权重; 结合词性特征以及上下文的语义信息,可以有效的缓解抽取任务中的带有前缀或 者后缀的问题,而导致抽取不准确的问题。 Step4.3、根据Step3获取得到的案件要素向量和微博评论的词向量根据相似度计 算公式,得到相似度概率权重,并选择出最大的概率权重。 所述Step5中,将通过词性向量和字符向量拼接后得到向量与最大相似概率权重 和相关性权重进行点乘后作为BiLSTM模型的输入G={g1 ,g2 ,...gm},模型首先进入一个 4 CN 111581474 A 说 明 书 3/7 页 LSTM层,通过公式(1)计算得到遗忘门,输入门和输出门。 其中W是输入层到隐藏层的参数矩阵,U是隐藏层到隐藏层的自循环参数矩阵,b为 偏置参数矩阵,σ为sigmoid函数。然后通过遗忘门ft和输入门it来控制忘记多少历史信息和 保存多少新信息 从而更新内部记忆细胞状态 其计算公式(2)所示: 接着通过输出门控制输出的结果,从而得隐状态ht,如公式(3)所示: 在完成LSTM后,本文还从后向运行了LSTM来生成后向隐向量 并将前向和后向 隐向量进行了拼接,记为ht,如公式(4)所示: 最后进入条件随机场进行抽取,其中条件随机场对模型的输出起到条件约束的作 用,最后得到抽取的结果。 本发明的有益效果是: 1、本发明的基于多头注意力机制的涉案微博评论的评价对象抽取方法,利用案件 要素与涉案微博评论中的评价对象的相干性,解决在涉案微博评论中,大众对于评价对象 与案件不相关的问题; 2、本发明的基于多头注意力机制的涉案微博评论的评价对象抽取方法,使用多头 注意力机制将词性特征与其上下文的关联性,解决了由于大众在评价中的前缀或后缀对于 评价对象抽取不准确的问题。 3、本发明的基于多头注意力机制的涉案微博评论的评价对象抽取方法,结合词 性、字符、词、上下文及案件要素的特征,利用BiLSTM和CRF对微博的评价对象进行抽取任 务。 4、本发明的基于多头注意力机制的涉案微博评论的评价对象抽取方法,解决了涉 案微博的微博评论中对于评价对象的抽取任务,且抽取效果好。 附图说明 图1为本发明评价对象抽取流程图; 图2为本发明提出的融入案件要素的评价对象抽取模型图。











