
技术摘要:
本发明公开了一种hadoop集群kerberos高可用认证方法,在不同的Linux服务器部署多个kerberos server;Linux定时器定时调用shell脚本对多个kerberos server的数据进行同步与备份;Hadoop在启动kerberos认证时,在krb5.conf的kdc参数配置所使用的所有kdc服务器地址;Hadoo 全部
背景技术:
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解 分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。 Kerberos是一种网络认证协议,其设计目标是通过密匙系统为客户机/服务器应 用程序提供强大的认证服务。该认证过程的实现不依赖于主机操作系统的认证,无需几本 主机地址的信任,不要求网络上所有主机的物理安全,并假定网络上传输的数据包可以被 任意的读取修改和插入。 Hadoop集群使用kerberos认证,是为了集群的安全性,Kerberos可以将认证的密 钥在集群部署时事先放到可靠的节点上。集群运行时,集群内的节点使用密钥得到认证,只 有被认证过节点才能正常使用,企图冒充的节点由于没有事先得到的密钥信息,无法与集 群内部的节点通信。防止了恶意的使用或篡改Hadoop集群的问题,确保了Hadoop集群的可 靠安全。 然而,在大规模集群中,单个kerberos服务作为认证服务器,往往会出现问题:首 先,有单点故障问题,当这台kerberos认证服务器出现异常,则集群上的任务启动认证会失 败,会导致整个集群异常;其次,当Hadoop集群节点达到一定规模,系统任务达到一定规模 的时候,会出现单kerberos认证服务器认证延迟过高或者认证异常等情况,所以,单 kerberos认证服务器已无法满足大规模集群认证。因此,如何研究设计一种hadoop集群 kerberos高可用认证方法是我们目前迫切需要解决的问题。
技术实现要素:
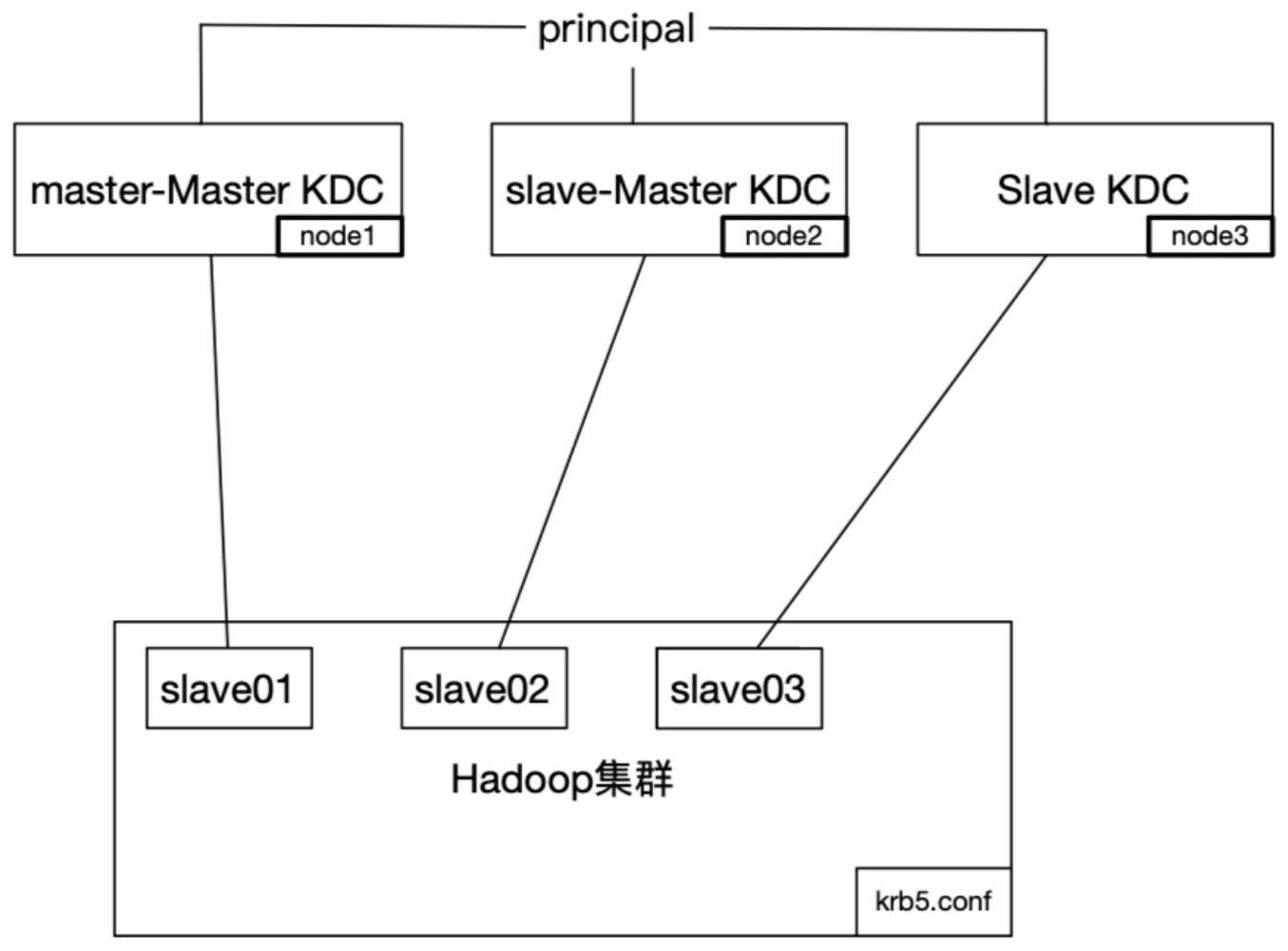
本发明的目的是提供一种hadoop集群kerberos高可用认证方法,kerberos server实现多备份,当hadoop在做kerberos认证时,可以根据其认证服务器配置做调整,在 大规模集群里面,可以减少因为认证带来的延时;同时,降低了kerberos server单服务器 的负载,保障了集群做kerberos认证的稳定性。 本发明的上述技术目的是通过以下技术方案得以实现的:一种hadoop集群 kerberos高可用认证方法,包括以下步骤: S1:在不同的Linux服务器部署多个kerberos server; S2:Linux定时器定时调用shell脚本对相应Linux服务器内的多个kerberos server的数据相互之间进行同步与备份; S3:Hadoop在启动kerberos认证时,在krb5.conf的kdc参数配置所使用的所有kdc 服务器地址;其中,默认第一个kdc参数为kerberos server的主主(master-master)服务, 第二个kdc参数为kerberos server的备主(slave-master)服务,第三个kdc参数为slave服 4 CN 111597536 A 说 明 书 2/4 页 务;Hadoop集群中,节点通过调整kdc参数顺序对kerberos认证优先顺序进行调整。 优选的,多个所述kerberos server部署具体为:在Linux服务器安装kerberos server与kerbreos client;所述kerbreos client用于操作本地与远程的kerberos server服务principle;所述kerberos server是Hadoop集群票据分发与验证服务器。 优选的,所述Linux定时器定时周期为5s执行一次。 优选的,所述Hadoop集群做kerberos认证时,优先向master-master对应的node1 认证;当node1的kerberos server出现异常时,接着向slave-master对应的node2认证;当 node1、node2均出现异常时,向slave对应的node3认证。 优选的,所述数据的同步与备份具体为:node1、node2、node3相互备份数据;其中, node1、node2相互之间数据同步,node3全量备份master-master主机的数据。 优选的,所述slave节点数据备份具体为:slave节点负责将master-master节点的 kdc数据同步过来;同时将相应数据导出,做冷备份。 优选的,所述master-master与slave-master相互数据同步具体为: a1:获取Linux系统hadoop启用kerberos的配置文件krb5.conf; a2:获取本系统kerberos高可用配置目录; a3:利用shell从krb5 .conf下获取主kerberos server的Linux主机名、备 kerberos server的Linux主机名; a4:获取本Linux系统的主机名; a5:获取本地kerberos server数据库里面所有principle信息,命名为local_ principles; a6:根据krb5 .conf的kdc参数配置,获取remote主机名以及remote主机的所有 principle信息,命名为remote_principles; a7:遍历local_principals;若local_principal不在remote_principles,则同步 local_principal到remote kdc服务器中;反之,则根据update_time,version信息,判断 local_principal与remote_principal哪个为最新数据,然后同步到服务中; a8:当将local_principals都遍历结束后;判断本地kdc服务是否running,如果 running,本次同步结束;如果非running,则启动起来,然后将krb5.conf中的kdc参数对调, 同步到几个节点,最后结束。 与现有技术相比,本发明具有以下有益效果: 1、通过hadoop集群部署方案,在启动kerberos认证过程中,krb5.conf配置文件根 据集群的节点交叉部署kdc参数,能避免kerberos认证负载过大,同时能满足集群的 kerberos认证的高可用要求; 2、通过Kerberos同步方案,kerberos server之间数据同步通过shell调用,其kdc 同步过程是根据principal的导入信息、版本号做对比进行同步;同时,根据实际场景,实现 多kerberos扩充,保障集群kerberos认证的稳定性。 附图说明 为了更清楚地说明本发明实施例中的技术方案,下面将对实施例或现有技术描述 中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些 5 CN 111597536 A 说 明 书 3/4 页 实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附 图获得其他的附图。 图1是本发明实施例中的整体原理结构示意图; 图2是本发明实施例中master-master与slave-master相互数据同步的流程图; 图3是本发明实施例中slave节点数据备份的流程图。











