
技术摘要:
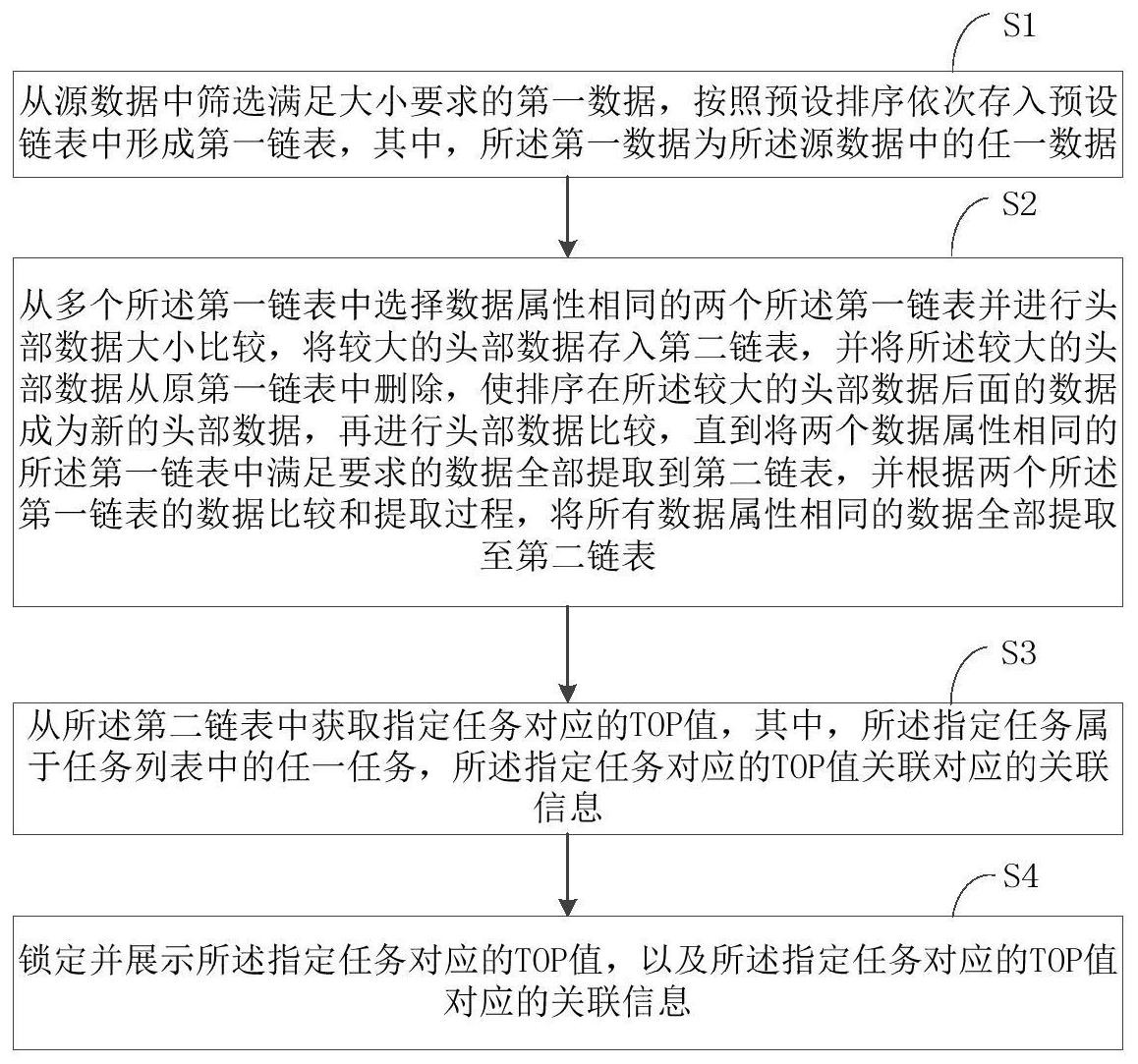
本申请揭示了筛选信息的方法,包括:从源数据中筛选满足大小要求的第一数据,按照预设排序依次存入预设链表中形成第一链表;从多个第一链表中选择数据属性相同的两个第一链表并进行头部数据大小比较,将较大的头部数据存入第二链表,并将较大的头部数据从原第一链表中 全部
背景技术:
Hadoop做数据仓库时,常用hive做离线数据处理,hive做离线数据处理时,需要用 到分组排序获取第一条数据的情况。传统的方式是使用“row_number”加上“distributeby” 指定对应的分组字段,然后“sortby”指定需要排序的字段并定义为字段“rn”,最后将计算 的数据作为子查询,然后再增加筛选条件“rn=1”,就能挑选出分组排序的第一条记录,但 是这样需要将一个分组中的所有数据先汇总再全部排序,消耗的资源也很大。而且数据架 构中只保存筛选出的一个结果数据,不利于数据应用的拓展。
技术实现要素:
本申请的主要目的为提供筛选信息的方法,旨在解决现有数据分组排序中耗费的 资源大的技术问题。 本申请提出一种筛选信息的方法,包括: 从源数据中筛选满足大小要求的第一数据,按照预设排序依次存入预设链表中形 成第一链表,其中,所述第一数据为所述源数据中的任一数据; 从多个所述第一链表中选择数据属性相同的两个所述第一链表并进行头部数据 大小比较,将较大的头部数据存入第二链表,并将所述较大的头部数据从原第一链表中删 除,使排序在所述较大的头部数据后面的数据成为新的头部数据,再进行头部数据比较,直 到将两个数据属性相同的所述第一链表中满足要求的数据全部提取到第二链表,并根据两 个所述第一链表的数据比较和提取过程,将所有数据属性相同的数据全部提取至第二链 表; 从所述第二链表中获取指定任务对应的TOP值,其中,所述指定任务属于任务列表 中的任一任务,所述指定任务对应的TOP值关联对应的关联信息; 锁定并展示所述指定任务对应的TOP值,以及所述指定任务对应的TOP值对应的关 联信息。 优选地,所述第一链表包括链表结构和按照预设排序填充在链表中的元组数,所 述预设排序为降序排列,所述从源数据中筛选满足大小要求的第一数据,按照预设排序依 次存入预设链表中形成第一链表的步骤,包括: 获取位于所述第一链表开始表格的第一元组数; 判断所述第一数据是否大于或等于所述第一元组数; 若是,则在所述开始表格的降序排序之前添加第一新表格,使所述第一新表格成 为开始表格; 将所述第一数据填充至所述第一新表格,使所述第一数据成为新的第一元组数, 并按照所述第一新表格的添加过程以及所述第一新表格中的数据填充过程,完成所述第一 5 CN 111737263 A 说 明 书 2/15 页 链表中所有数据的录入。 优选地,判断所述第一数据是否大于或等于所述第一元组数的步骤之后,包括: 若否,则获取与所述开始表格相邻且位于所述开始表格排序之后的第二元组数; 判断所述第一数据是否大于或等于所述第二元组数; 若是,则在所述第二元组数之前添加第二新表格; 将所述第一数据填充至所述第二新表格,并按照所述第一新表格、第二新表格的 添加过程,以及所述第一新表格、第二新表格中的数据填充过程,完成所述第一链表中所有 数据的录入。 优选地,判断所述第一数据是否大于或等于所述第二元组数的步骤之后,包括: 若否,依次获取降序排列中排布于所述第二元组数之后的第三元素组,直至降序 排序的末尾数; 判断所述第一数据是否大于或等于所述末尾数; 若否,则在降序排序中的所述末尾数之后,添加第三新表格; 将所述第三元组数填充至所述第三新表格,并根据所述第一新表格、第二新表格 和第三新表格的添加过程,以及所述第一新表格、第二新表格和第三新表格中数据填充过 程,完成所述第一链表中所有数据的录入。 优选地,所述完成所述第一链表中所有数据的录入的步骤之后,包括: 判断添加完所有数据的第一链表的链表长度是否大于第一预设量; 若是,则将排布于所述第一链表的指定数量的末尾表格剔除,同时删除填充在所 述指定数量的末尾表格的元组数,使所述第一链表的链表长度保持在小于或等于所述第一 预设量。 优选地,从源数据中筛选满足大小要求的第一数据,按照预设排序依次存入预设 链表中形成第一链表的步骤之前,包括: 判断所述第一链表中的元组数的数量是否大于第二预设量; 若是,则终止从所述源数据中筛选数据,终止向所述第一链表中填充数据。 优选地,所述从多个所述第一链表中选择数据属性相同的两个所述第一链表并进 行头部数据大小比较,将较大的头部数据存入第二链表,并将所述较大的头部数据从原第 一链表中删除,使排序在所述较大的头部数据后面的数据成为新的头部数据,再进行头部 数据比较,直到将两个数据属性相同的所述第一链表中满足要求的数据全部提取到第二链 表,并根据两个所述第一链表的数据比较和提取过程,将所有数据属性相同的数据全部提 取至第二链表的步骤,包括: 比较第一指定链表的头部元组数与第二指定链表的头部元组数,其中,所述第一 指定链表和所述第二指定链表,属于所有第一链表中具有相同数据属性以及排序规律的两 个链表,所述排布规律包括降序排列; 若所述第一指定链表的头部元组数大于或等于第二指定链表的头部元组数,则将 所述第一指定链表的头部元组数提取至所述第二链表,并剔除所述第一指定链表的头部元 组数,将与所述第一指定链表的头部元组数相邻,且位于降序排序中所述第一指定链表的 头部元组数之后的元组数,变更为新头部元组数; 将所述第一指定链表的新头部元组数与所述第二指定链表的头部元组数比较大 6 CN 111737263 A 说 明 书 3/15 页 小; 若所述第一指定链表的新头部元组数小于所述第二指定链表的头部元组数,则将 所述第二指定链表的头部元组数提取至所述第二链表,并排列于所述第一指定链表的头部 元组数之后形成降序排布,且剔除所述第二指定链表的头部元组数,将与所述第二指定链 表的头部元组数相邻,且位于降序排序中所述第二指定链表的头部元组数之后的元组数, 变更为新头部元组数; 按照所述第一指定链表的头部元组数与第二指定链表的头部元组数的比较过程, 以及所述第一指定链表的新头部元组数与所述第二指定链表的头部元组数比较过程,继续 比较所述第一指定链表与所述第二指定链表中的剩余元组数,至所述第二链表中的数据数 量达到预设条件,完成所述第二链表中所有数据的录入。 本申请还提供了一种筛选信息的装置,包括: 筛选模块,用于从源数据中筛选满足大小要求的第一数据,按照预设排序依次存 入预设链表中形成第一链表,其中,所述第一数据为所述源数据中的任一数据; 比较模块,用于从多个所述第一链表中选择数据属性相同的两个所述第一链表并 进行头部数据大小比较,将较大的头部数据存入第二链表,并将所述较大的头部数据从原 第一链表中删除,使排序在所述较大的头部数据后面的数据成为新的头部数据,再进行头 部数据比较,直到将两个数据属性相同的所述第一链表中满足要求的数据全部提取到第二 链表,并根据两个所述第一链表的数据比较和提取过程,将所有数据属性相同的数据全部 提取至第二链表; 获取模块,用于从所述第二链表中获取指定任务对应的TOP值,其中,所述指定任 务属于任务列表中的任一任务,所述指定任务对应的TOP值关联对应的关联信息; 锁定模块,用于锁定并展示所述指定任务对应的TOP值,以及所述指定任务对应的 TOP值对应的关联信息。 本申请还提供了一种计算机设备,包括存储器和处理器,所述存储器存储有计算 机程序,所述处理器执行所述计算机程序时实现上述方法的步骤。 本申请还提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机 程序被处理器执行时实现上述的方法的步骤。 本申请通过改变数据存储结构,使中间存储数据可存储多个元组数,方便需要不 同数据类型的top值的数据应用,且基于改进的数据存储结构优化了排序获取top值的筛选 方法,简化了比较取值过程,提高数据处理效率。 附图说明 图1本申请一实施例的筛选信息的方法流程示意图; 图2本申请一实施例的筛选信息的装置结构示意图; 图3本申请一实施例的计算机设备内部结构示意图。











