
技术摘要:
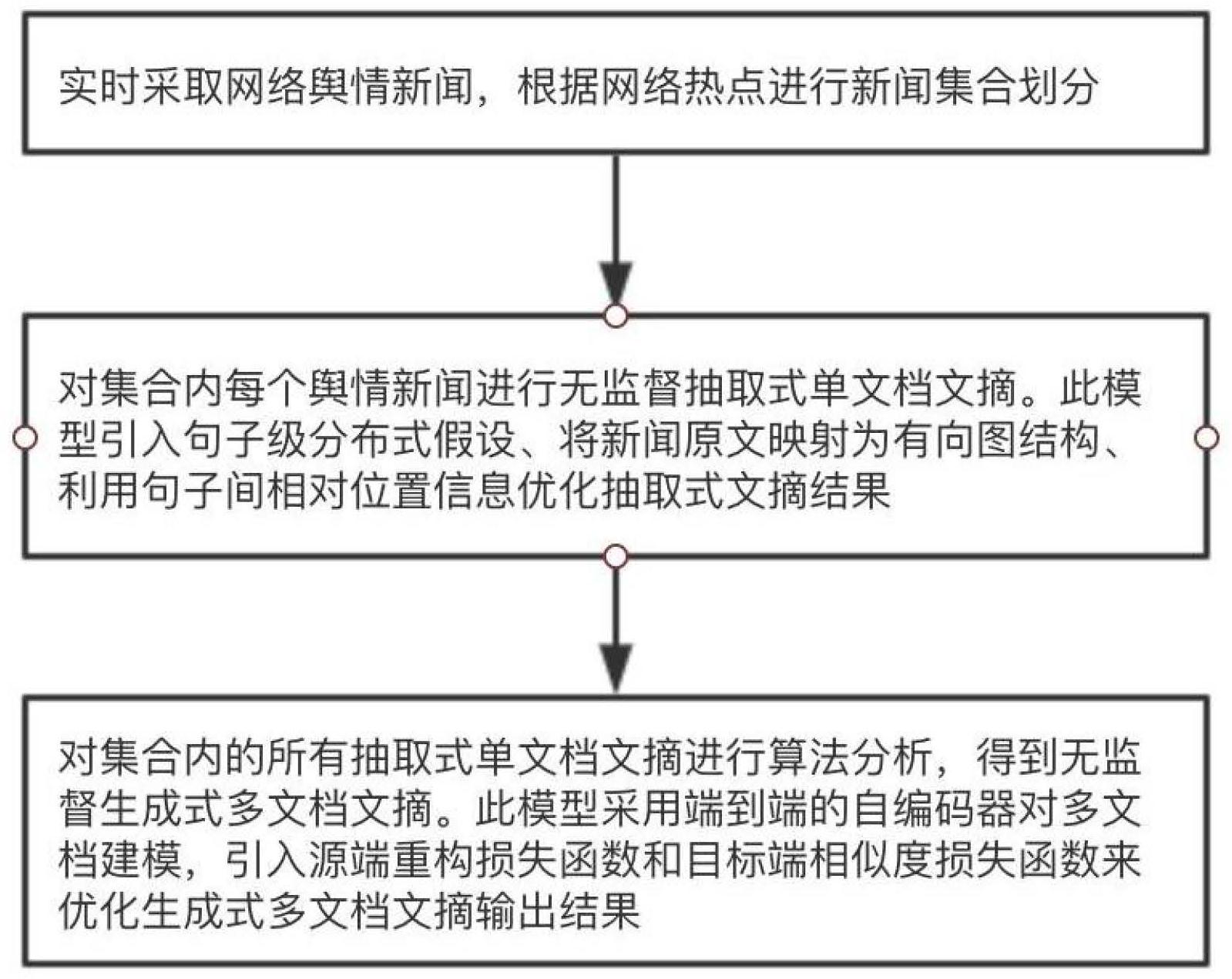
本发明公开了一种面向舆情分析的无监督式多文档文摘生成方法。步骤1:实时采集网络舆情新闻,根据网络热点进行新闻集合自动划分;步骤2:对集合内每个舆情新闻进行无监督式的抽取单文档文摘;步骤3:对集合内的所有抽取的单文档文摘进行分析,得到无监督式的多文档文摘 全部
背景技术:
自动文摘是自然语言处理领域最重要的技术之一,其研究目的是利用计算机自动 地从文本或者文本集合中抽取或生成能准确复述原文意思的精炼、连贯的短文。用户只需 要阅读文摘结果便可以了解文档的主要信息,省去大量检索和阅读大篇幅文档的时间,从 而提供人们的阅读效率。 按照不同的划分标准,可以将自动文摘技术划分成不同类别,主要有以下三种划 分方式: 1 .根据是否需要语料库,可以划分为无监督文摘和有监督文摘。无监督的摘要方 法又细分为基于经验式规则、基于主题、基于图、基于整数线性规划等方法;有监督方法又 细分为基于分类、回归、序列标注以及端到端的神经网络等方法。 2.根据文摘与原文的关系,划分为抽取式文摘和生成式文摘。抽取式文摘是指从 原始文档中抽取重要结构单元(句子、短语等),这种方法一般需要定义规则或特征集合,根 据特征对原文句子进行打分排序,选择得分高的句子作为文摘句;生成式文摘是指基于理 解文档的角度生成摘要,摘要中的句子或词可以未在原始文档中出现过。生成式文摘更接 近人自身写的摘要,但是需要用到自然语言理解和文本生成技术,例如句子压缩、改写、融 合等等,有一定技术难度。 3.根据处理文档的数量,可以划分为单文档文摘与多文档文摘。单文档文摘对一 篇文档进行处理,产生该文档的文摘;多文档文摘将多篇相同主题的文档聚集在一起,对文 档集进行处理,形成该文档簇的文本摘要,多文档相对单文档而言,由于信息来源于不同文 本,文摘连贯性的问题更加严重。
技术实现要素:
本发明提供一种面向舆情分析的无监督式多文档文摘生成方法,解决现有多文档 文摘方法效果较低、生成式文摘实用性较差、中文舆情文摘训练语料匮乏的问题,以实现对 舆情新闻的监控。 本发明通过以下技术方案实现: 一种面向舆情分析的无监督式多文档文摘生成方法,所述生成方法包括以下步 骤: 步骤1:实时采集网络舆情新闻,根据网络热点进行新闻集合自动划分;从互联网 中获取到热点,将该热点作为查询语句,利用搜索引擎收集与该热点相关的新闻,因此建立 热点-新闻,一个热点对多个新闻的关系,从而划分出新闻集合; 步骤2:对集合内每个舆情新闻进行无监督式的抽取单文档文摘;利用深度学习技 5 CN 111597327 A 说 明 书 2/9 页 术在大规模自然语言文本中训练语言模型,并将文本转化成以句子为单位的有向图结构, 从有向图中抽取按照中心度打分,将有向图中各节点降序排列,取前k个句子作为抽取式摘 要输出作为文摘句; 步骤3:对集合内的所有抽取的单文档文摘进行分析,得到无监督式的多文档文 摘;无监督式的多文档文摘生成为利用自编码器构建端到端的神经网络模型,并引入源端 重构损失函数和目标端相似度损失函数,共同作为模型的优化目标,使得源端能够生成重 构多文档集合的分布式表示向量,目标端能够生成与多文档集合相似性高的文摘句。 进一步的,所述深度学习技术为基于Bert的预训练语言模型,所述预训练语言模 型通过以下步骤建立: 步骤2.01:使用Transformer编码器,在大规模领域无关网络语料中训练双向语言 模型,所述双向语言模型采用自注意力机制捕获每个单词所属句子的上下文特征,能够同 时学习覆盖词预测与连续句预测两个任务; 步骤2.02:使用网络舆情新闻这一特定领域语料,对预训练双向语言模型进行微 调,使双向语言模型能够学习并适应特定领域语料的构词特征、语法特征,最终得到舆情新 闻相关的预训练语言模型; 步骤2.03:针对文本摘要特点,作出句子级分布式假设,采取自监督学习的方式拟 合,对舆情新闻相关的预训练语言模型进行参数微调。 进一步的,所述步骤2.3中作出句子级分布式假设,采取自监督学习的方式拟合, 具体过程为:舆情新闻中第i个句子用si表示,将句子si-1和句子si 1作为句子si的正例,将语 料中的其他句子作为负例,针对句子si,双向语言模型的学习目标如下: 其中,vs和v′s是两个不同参数化Bert编码器的向量表示,σ是sigmoid函数,P(s)是 句子空间的均匀分布函数,该目标函数T是为了将语料库中的其他句子与上下文句子区分 开。 进一步的,所述文本转化成以句子为单位的有向图结构,从有向图中抽取最重要 的结点作为文摘句,具体过程为: 步骤2.11:利用微调后的舆情新闻相关的预训练语言模型,将舆情新闻文本映射 为高维分布式表示向量, 步骤2.12:将自然语言文本定义为有向图结构,所述有向图中各节点间相似度计 算公式为: 其中, 表示文档中第i个句子si的分布式表示, 表示未标准化的相似度矩阵, 表示第i个句子与第j个句子的未标准化相似度得分; 由未标准化的相似度矩阵 得到规范化相似度矩阵E的计算公式为: 6 CN 111597327 A 说 明 书 3/9 页 其中,E表示规范化后的相似度矩阵,通过强调不同相似度得分之前的相对贡献来 消除相似度得分的绝对值影响,β∈[0,1],表示控制节点相似度得分归为0的阈值; 利用有向图各节点邻边权重信息汇总计算节点的中心度打分,所述中心度计算公 式为: centrality(si)=λ1∑j<ieij λ2∑j>ieij (5) 其中,λ1、λ2是两个不同的权重,分别表示前向权重、后向权重; 按照中心度打分,将有向图中各节点降序排列,取前k个句子作为抽取式摘要输 出。 进一步的,所述用自编码器构建端到端的神经网络模型,具体过程如下: 步骤3.1:利用长短时间记忆网络作为编码器,对文档集合内各舆情新闻抽取式文 摘编码,得到句子级分布式表示,所述编码的计算公式为: φE(x)=[h,c] zi=φE(xi) 其中,xi表示第i个舆情新闻抽取式文摘,h和c分别表示长短时间记忆网络的隐状 态与细胞状态,φE(x)是隐状态h和细胞状态c的级联表示,zi表示第i个舆情新闻抽取式文 摘的分布式向量; 步骤3.2:利用另一个参数非共享的长短时间记忆网络作为解码器,解码器的输入 是编码器输出的分布式向量,利用该向量解码出一段自然语言文本序列,解码器的计算公 式与编码器相同,模型以源端重构损失函数为目标,使编码器与解码器同时捕获源端文本 语义信息; 文档集合D包含k篇舆情新闻抽取式文摘{x1,x2,…,xk},自编码器学习输出向量组 {z1,z2,...,zk},对向量组求平均得到文档集合D的压缩表示向量 利用参数共享的解码器 φD得到生成式多文档文摘s,并使用参数共享的编码器φE对文摘s重新编码; 步骤3.3:模型以目标端相似度损失函数为目标,使文摘s编码后的向量zs,与源端 文档集合各舆情新闻文本编码后的向量更相近,减少模型编码解码过程中的语义信息丢 失。 进一步的,所述源端重构损失函数计算公式为: 其中,losscross_entropy表示交叉熵损失函数;φD(φE(xi)表示第i个舆情新闻抽取 式文摘先经过编码器,再经过解码器的输出结果;lossrec表示源端重构损失函数,由舆情新 闻文档集合各舆情新闻抽取式文摘的交叉熵累加和计算得到。 进一步的,所述目标端相似度损失函数计算公式为: 其中,dcos表示向量余弦相似度;hi表示第i个舆情新闻抽取式文摘经过长短时间 记忆网络输出的隐状态;hs表示多文档文摘句s经过共享参数的编码器得到的隐状态; losssim表示目标端相似度损失函数,由舆情新闻文档集合各舆情新闻抽取式文摘隐状态的 余弦相似度平均值计算得到。 本发明的有益效果是: 7 CN 111597327 A 说 明 书 4/9 页 1.本发明提出针对新闻文本的无监督抽取式单文档文摘方法,将基于神经网络的 预训练语言模型与基于图的算法相结合,对每篇舆情新闻单独处理,得到每篇舆情新闻的 核心语句。此方法提出句子分布式假设,在预训练语言模型中引入相对位置信息,并根据新 闻文本的行文特点,采用有向图的自动文摘算法对舆情新闻文本进行分析。 2.本发明提出针对热点相关舆情新闻集合的无监督生成式多文档文摘方法,将自 编码器应用于多文档文摘方法,引入源端重构损失函数与目标端相似度损失函数,共同作 为模型的优化目标。本发明采用贪心策略在解码端逐字生成,能够得到实用性较强、通顺较 高的多文档文摘, 3.本发明突破单文档文摘与多文档文摘的局限,将单文档文摘作为多文档文摘的 前序任务,有效降低多文档文摘的计算复杂度,减少模型解码时的搜索空间。 4.本发明提出的一系列自动文摘方法,均不需要“原文本-摘要”数据对,适应中文 舆情文摘训练语料匮乏的环境,此方法充分利用网络舆情新闻文本规模大的特点,避免既 耗时又耗力的人工标注方式。 附图说明 图1本发明的流程示意图。 图2本发明的语料库构建流程图。 图3本发明的无监督式抽取单文档文摘流程图。 图4本发明的无监督式抽取单文档文摘结果样例。 图5本发明的无监督式生成多文档文摘模型示意图。











