
技术摘要:
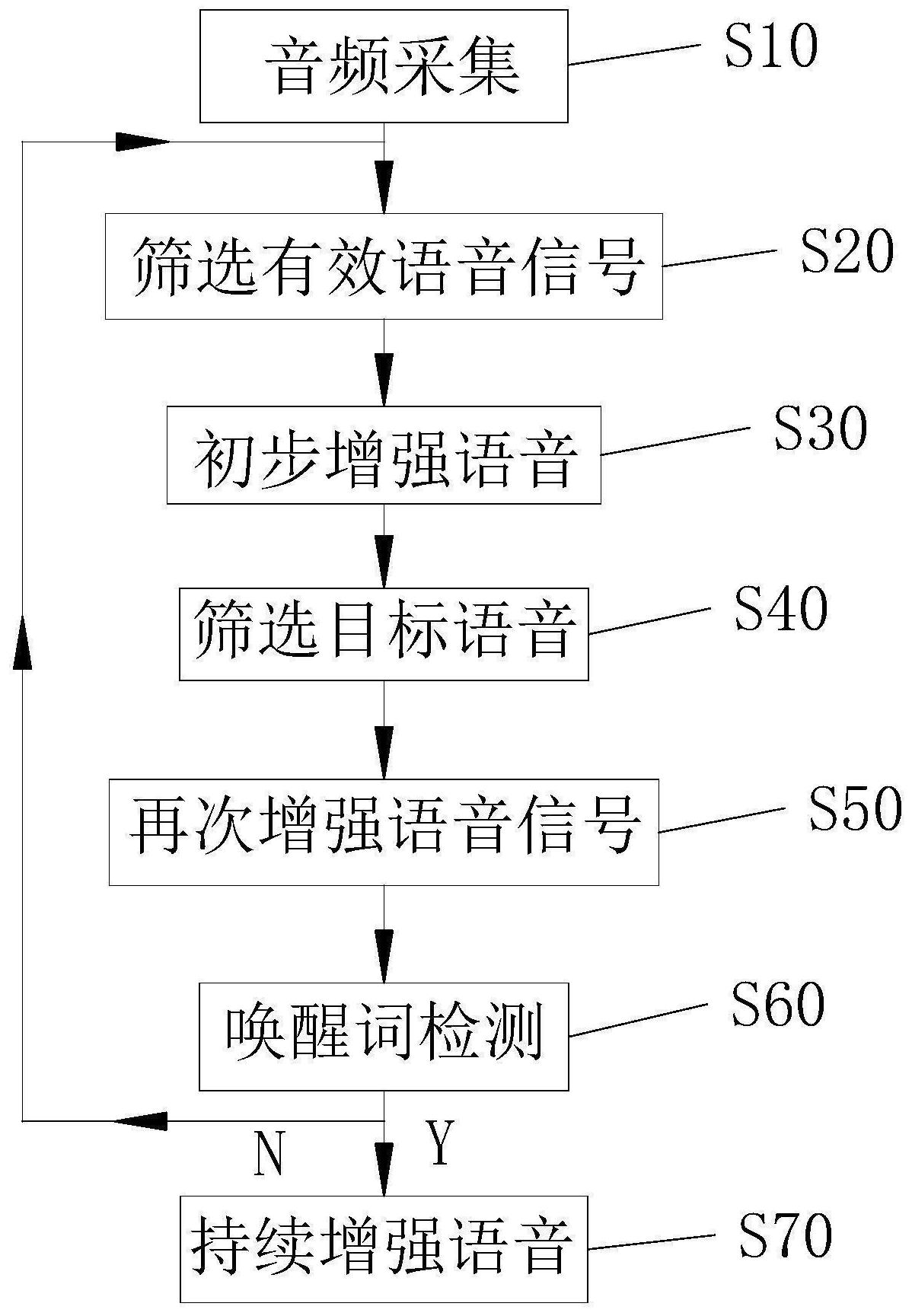
本发明涉及一种语音信号的处理方法,尤其是语音增强方法,包括以下步骤:S10、音频采集;S20、筛选有效语音信号;S30、初步增强语音;S40、筛选目标语音;S50、再次增强语音信号;S60、唤醒词检测,将再次增强的语音送入高精度的唤醒词检测模型中进行唤醒词检测,当检 全部
背景技术:
语音增强是指从接收到的复杂的语音信号中提取有效的目标语音信号,降低或者 抑制来自非目标语音信号的干扰的技术手段。目前语音增强算法通常需要预先知道目标声 源的方位或者噪声的先验分布后通过一定的算法来进行语音增强。 然而在实际较强噪声的应用场景中,由于无法事先确定哪一个是目标声源,可能 会导致声源定位不准确,影响后续的语音信号处理;而且相对复杂和较为精准的声源定位 算法以及语音增强算法往往都意味着计算复杂度较高,需要提供较大的计算资源。所以,传 统的语音增强算法和系统对某些应用场景存在一定的局限性。
技术实现要素:
为解决上述问题,本发明提供一种在只有低计算资源设备的条件下,针对强噪声 场景下的语音信号,依然可以做到有效的语音唤醒和语音识别的语音增加方法,具体技术 方案为: 语音增强方法,包括以下步骤: S10、音频采集,通过音频采集设备不断的采集多通道音频信号; S20、筛选有效语音信号,用语音活动检测对接收到的音频信号进行不间断的检测 筛选,筛选出有效语音信号; S30、初步增强语音,对筛选出的有效语音信号进行初步增强,所述初步增强包括 采用固定波束语音增强算法同时对多个方向进行语音增强; S40、筛选目标语音,将初步增强的语音送入评分模型中进行评分,选择评分最高 且大于指定阈值的语音信号,得到该信号的方向; S50、再次增强语音信号,对筛选的目标语音进行再次增强,所述再次增强包括采 用高性能的语音增强算法; S60、唤醒词检测,将再次增强的语音送入高精度的唤醒词检测模型中进行唤醒词 检测,当检测到唤醒词时进入S70,否则返回S20; S70、持续增强语音,对通过唤醒词检测的语音进行持续增强,然后将增强后的语 音送入识别端进行识别。 进一步的,所述固定波束语音增强算法包括广义旁瓣相消算法或权重延迟相加算 法。 进一步的,所述评分模型包括深度神经网络唤醒模型,所述深度神经网络唤醒模 型包括评分特征提取模块,所述评分特征提取模块用于对送入的初步增强的语音提取与模 型匹配的特征;评分深度神经网络模块,所述评分深度神经网络模块用于将每一帧的语音 4 CN 111599371 A 说 明 书 2/6 页 特征转化为指定关键字与其它无关字的后验概率;评分唤醒决策模块,所述评分唤醒决策 模块用于通过一段语音信号的后验概率来判断该段语音是否可以被唤醒。 进一步的,所述深度神经网络唤醒模型的层数为3-5层,节点数在30-40。 进一步的,所述唤醒决策模块的唤醒词包括两个字。 进一步的,所述高性能语音增强算法包括最小方差无失真响应算法或基于混合高 斯模型的最小方差无失真响应算法。 进一步的,所述唤醒词检测模型包括时间延迟网络或者卷积神经网络。 进一步的, 所述唤醒词检测模型包括 唤醒词特征提取模块,所述唤醒词特征提取模块用于对送入的再次增强的语音提 取与模型匹配的特征; 唤醒词深度神经网络模块,所述唤醒词深度神经网络模块用于将每一帧的语音特 征转化为指定关键字与其它无关字的后验概率; 唤醒词唤醒决策模块,所述唤醒词唤醒决策模块用于通过一段语音信号的后验概 率来判断该段语音是否可以被唤醒。 语音增强系统,包括音频采集系统,用于不断的采集多通道音频信号;有效语音信 号筛选系统,用于对接收到的音频信号进行不间断的检测筛选;初步增强语音系统,用于对 筛选出的有效语音信号进行初步增强;筛选目标语音系统,用于对初步增强的语音进行筛 选;再次增强语音信号系统,用于对筛选的目标语音进行再次增强;唤醒词检测系统,用于 对再次增强的语音进行唤醒词检测和判断;持续增强语音系统,用于对通过唤醒词检测的 语音进行持续增强并送入识别端识别。 一种语音装置,所述装置包括处理器、存储器以及程序;所述程序存储在所述存储 器中,所述处理器调用存储器存储的程序,以执行语音增强方法的步骤。 一种计算机可读存储介质,所述计算机可读存储介质被配置成存储程序,所述程 序被配置成执行语音增加方法的步骤。 与现有技术相比本发明具有以下有益效果: 本发明提供的语音增强方法可以有效的降低计算开销,即使在有强噪声场景下也 能较准确的进行识别任务。适合应用在环境较复杂且计算资源有限的本地端。 附图说明 图1是语音增强方法的流程图; 图2是评分模型的方框图; 图3是唤醒词检测模型的方框图。











