 技术摘要:
技术摘要: 一种基于Quota的集群模糊控制容量规划方法,包括以下步骤:步骤1:根据用户方提供的保存周期、每日数据增量折算为Quota;步骤2:创建集群region,设计抽象出两层逻辑的概念rack和region来规划集群;步骤3:预留free‑rack缓冲池,定位在10%的free‑rack;所有的集群共 全部
背景技术:
在互联网企业中,随着基于大数据Elasticsearch引擎搭建的搜索存储平台优化
迭代过程中,各类自适应规划算法层出不穷,力求对用户创建的索引数据进行高效合理的
管控,提高集群资源利用率的同时又大大减少人工运维成本。但是随着自适应容量规划算
法的应用,带来的运维成本不断凸显,并且存在集群单节点故障的可能,随着各种集群自适
应算法应用和时间推移,业务需求的不断接入,这种故障变得不再可控。
对比某一互联网企业的自适应集群容量规划算法可知,根据同一个索引模板来创
建的索引数据每天都会分配到不同的集群节点上,这种算法存在以下几个问题:
(1)数据热点。算法会一次性将集群中某个节点的空闲空间打满,经常出现一个节
点上存在某个超大数据量的索引,这种情况对后期运维非常不友好,涉及磁盘告警和数据
搬迁时操作复杂,耗时较长;
(2)不可容错性。要求自适应集群规划算法任务每天都要成功,不得失败,因为索
引模板分配的节点只能承接一天的量;
(3)影响模版范围广。在当前自适应规划算法状态下,侧重于空闲的节点,用户索
引模版数据会不均匀分配到多个集群节点中,有些节点存储模版量多,有些节点存储模版
量小,一旦出现集群某节点故障,该故障节点存在大量模版的情况下,造成严重的数据丢
失,后果不堪设想。
(4)固化的写入瓶颈。基于配额管控用户的索引模板时,当配额内的磁盘被打满
时,容量规划算法下只能通过停止用户写入来管控。但是,对索引中过期数据的处理显然比
停止用户写入来得更优雅。
虽然这种自适应规划算法在一定程度上提升了集群的资源利用率,降低了需要人
工手动分配集群资源带来的运维成本。但是随着业务需求的发展,自适应算法带来其他方
面的运维成本不断凸显,一定程度降低集群的稳定性。因此,需要更有效的集群容量规划策
略来解决当前的痛点。
技术实现要素:
为了克服已有技术的不足,本发明提供了一种基于Quota的集群模糊控制容量规
划方法,将集中于集群级别的资源规划,集群资源规划中的数据存储单元为索引模板,其大
小是基于Quota来管控的,不在支持索引资源需求量的自适应;实现一个能够作用于任何集
群、任何索引模板保存周期的固定资源分配的规划算法;能够定期的检查各个索引模板的
资源是否能够满足Quota需求,并根据统计做出扩缩容调整;提高集群资源利用率,会保证
每个region的资源利用率在合理的范围内,每个模板会占用的资源会固定在region中。
7
CN 111597253 A 说 明 书 2/13 页
本发明解决其技术问题所采用的技术方案是:
一种基于Quota的集群模糊控制容量规划方法,包括以下步骤:
步骤1:模版数据Quota初始化,根据用户方提供的保存周期、每日数据增量折算为
Quota;
Quota=(userapply*day)/capnode
其中,userapply为用户申请的资源,day为保存天数,capnode为每个机器节点的磁盘
规格;
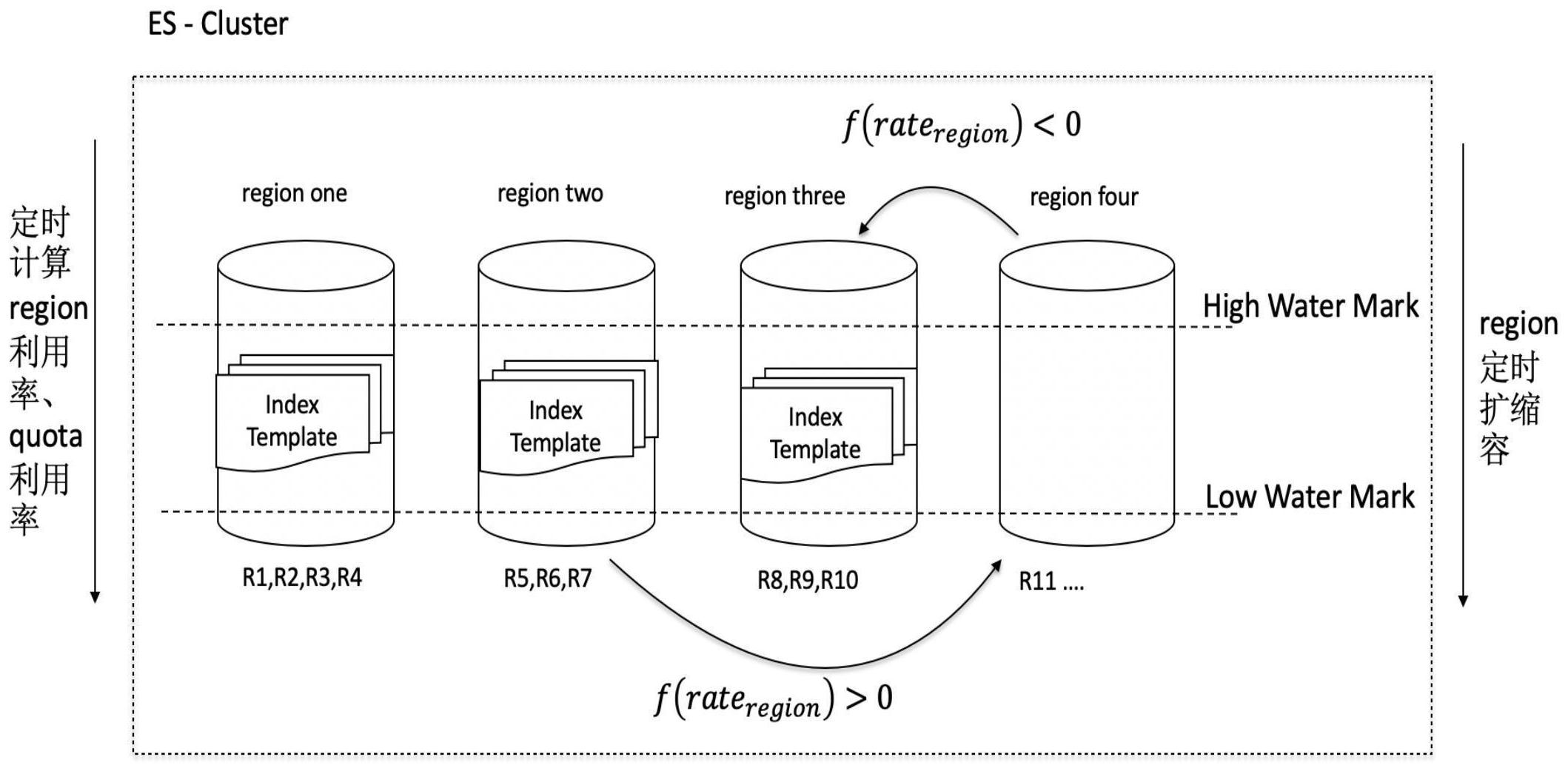
步骤2:创建集群region,设计抽象出两层逻辑的概念rack和region来规划集群,
作用层面在region,集群与节点的关系如下所示:
其中,R为集群区域region,r为机架rack,n为rack的个数,n的范围为 3
0,表示资源利用率大于高水位线,需要扩容,扩容的节点数为count的绝对
值;
count<0,表示资源利用率小于低水位线,需要缩容,缩容的节点数为count的绝对
值;
其中,构建f(h)=count模型流程如下:
4.1.3.2.1确定观测量
由上定义集群region低水位线为Low,高水位线为High,实际测得的水位高度为h,
上下限液位差Δe如下:
h-Low≤Δe≤h-High
其中对于高低水位线的偏差量Δe作为观测值。
4.1.3.1.2)定义输入输出模糊集
Δe的模糊集均为:{NB ,NM ,NS ,ZO ,PS ,PM ,PB},其中负大(NB)、负中 (NM)负小
(NS)、零(O)、正小(PS)、正中(PM)正大(PB),其中N1、N2为经验值,以下出现N1、N2皆为该意
义;
Δe论域,即变化范围为:{-3,-2,-1,0,1,2,3},得到如下集群region 水位变化划
分表1,表1为集群region水位变化划分表;
表1
控制量count为调节集群region的变化阀门,将其分为五个模糊集:负大(NB)、负
中(NM)负小(NS)、零(O)、正小(PS)、正中(PM)正大(PB),并将count 的变化范围分为九个等
级:-4,-3,-2,-1,0, 1, 2, 3, 4,得到集群region 控制量模糊划分表2:
10
CN 111597253 A 说 明 书 5/13 页
表2
4.1.3.1.3)模糊规则的描述
根据日常的经验,设计以下模糊规则:
“若Δe负大,则count负大”
“若Δe负中,则count负中”
“若Δe负小,则count负小”
“若Δe为0,则count为0”
“若Δe正小,则count正小”
“若Δe正中,则count正中”
“若Δe正大,则count正大”
其中,region利用率调整时,count为负,增加,count为正,减少。
上述规则采用“IF A THEN B”形式来描述:
ifΔe=NB then count=NB
ifΔe=NM then count=NS
ifΔe=NS then count=NS
ifΔe=0then count=0
ifΔe=PS then count=PS
ifΔe=PM then count=PM
ifΔe=PB then count=PB
由上经验规则,得模糊控制规则表3。
若 NBe NMe NSe ZOe PSe PMe PBe
则 NBc NMc NSc ZOc PSc PMc PBc
表3
4.1.3.1.4)求模糊关系
模糊控制规则是一个多条语句,它可以表示为U×V上的模糊子集,即模糊关系R:
R=(NBe×NBc)∪(NMe×NMc)∪(NSe×NSc)∪ (ZOe×ZOc)∪(PSe×PSc)∪(PMe
×PMc)∪(PBe×PBc)
由上模糊关系,其中规则内的模糊集运算取交集,规则间的模糊集运算取并集,求
11
CN 111597253 A 说 明 书 6/13 页
得
4.1.3.1.5)模糊核心决策
集群region调整输出量为一模糊向量 其中,为矩阵的合成运算;
4.1.3.1.6)根据上述控制输出模糊向量v,再反模糊化得到调整节点count。
优选的,反模糊化方法采用最大隶属度法,选取推理结果模糊集合中隶属度最大
的元素作为输出值,即:
count=maxμv(v) ,v∈R
如果在输出论域V中,其最大隶属度对应的输出值多于一个,则取所有具有最大隶
属度输出的平均值,即:
最大隶属度法不考虑输出隶属度函数的形状,只考虑最大隶属度处的输出值;
若 根据隶属度最大原则进行反模糊化,1对
应的隶属度为-4,故选择控制量为count=-4。
所述4.2,容量检查任务的过程为:
4.2.1)执行周期:根据不同场景,定期运行;
4.2.2)算法目标:确保流量突增、用户申请扩容等场景下的资源充足;
4.2.3)算法策略:
依次检查每个region的实际的资源利用率,如果rate0,表示资源利用率大于高水位线,需要扩容,扩容的节点数为 countcount<0,表示
资源利用率小于低水位线,需要缩容,缩容的节点数为 count。
本发明的基于Quota的集群模糊控制容量规划方法,过程为:模版数据Quota 化、
创建集群region、预留region free-rack缓冲池、根据模糊控制容量规划策略获取每个
region的调整量count、再由count维度执行region资源规划和region资源检测任务、任务
去重操作。
本发明的有益效果主要表现在:1,集群资源规划中的数据存储单元为索引模板,
其大小是基于Quota来管控的,不在支持索引资源需求量的自适应;2,实现一个能够作用于
12
CN 111597253 A 说 明 书 7/13 页
任何集群、任何索引模板保存周期的固定资源分配的规划算法,3,该算法能够定期的检查
各个索引模板的资源是否能够满足Quota需求,并根据统计做出扩缩容调整;4,提高集群资
源利用率,算法会保证每个region的资源利用率在合理的范围内,每个模板会占用的资源
会固定在region中。
附图说明
图1为本发明实施例集群资源分配示意图;
图2为balance-diff策略示意图;
图3是balance-diff策略收益图;
图4为本发明实施例容量规划算法流程图;
图5为本发明实施例region检查任务流程图。












