
技术摘要:
本发明涉及生成物体的3D重建(62)。这包括:照射所述物体,捕捉关于所述物体的图像数据;以及根据所述图像数据来计算所述物体的3D重建(62)。根据本发明,所述图像数据包括第一图像数据和第二图像数据,其中,所述第一图像数据是在用照射光照射所述物体(12)时捕捉 全部
背景技术:
在刘振(Zhen , Liu)等人的“A Novel Stereo Vision Measurement System Using Both Line Scan Camera and Frame Camera [使用线扫描相机和帧相机两者的新 颖立体视觉测量系统]”中,已经描述了开篇所阐述类型的方法和设备。该文献建议同时捕 捉表面的灰度值图像和工件的深度图像。当捕捉深度图像时,用激光以反射光配置来照射 工件,并通过单帧相机和线相机从不同的记录位置进行记录。因此,根据所捕捉的图像数 据,通过三角测量在所谓的立体模型中计算工件的3D坐标。为此,基于这两个相机的校准信 息,针对用线相机记录的像素 来确定外极线 ,属于所述像素 的3D点P位于所述外极线 上。接着,将这条外极线 投影到单帧相机的记录中,其中,属于3D点P的像素必须位于单帧 相机的像平面中的投影外极线上。于是在单帧相机的记录中,用激光照射工件产生了细线, 所述细线是工件一部分的图像表示。随后,通过分析单帧相机记录中的沿着投影外极线的 灰度值曲线来确定具有最大灰度值的像素 。然后,将3D点P的坐标显示为具有点 的外极 线 与具有点 的外极线的交点。 US 9,357,204 B2披露了通过将一副眼镜布置在旋转的旋转板上并且随之一起在 多个图像捕捉装置前方移动来创建对这副眼镜的3D重建,每个图像捕捉装置被实施为相 机。在过程中,以不同的视角来记录这副眼镜的图像,每个视角都示出这副眼镜的剪影。接 着,计算机单元根据这些图像来计算关于这幅眼镜的3D重建。 DE 10 2018 209 570 A1(已公开并且根据EPC第54条第3款仅形成现有技术)说明 了通过将物体相对于图像捕捉装置移位并且在与物体一起的不同位置进行记录来确定物 体的3D重建。在此情况下,基于编码功能和解码功能,将所捕捉的图像投影到三维栅格后置 滤波器上,所述栅格的值表示3D重建。 通过摄影测量法为物体提供3D重建的可商购3D扫描仪不适用于眼镜和眼镜架的 三维测量,因为眼镜和眼镜架具有非常薄且部分反射的结构。为了能够通过结构光投射来 4 CN 111602177 A 说 明 书 2/18 页 测量眼镜和眼镜镜片,这些部件通常必须设有例如通过喷涂来施加的表面涂层。通过激光 线扫描对物体进行准确测量需要提供高功率激光辐射和高分辨率相机,这有助于以很大的 亮度差异来捕捉图像。
技术实现要素:
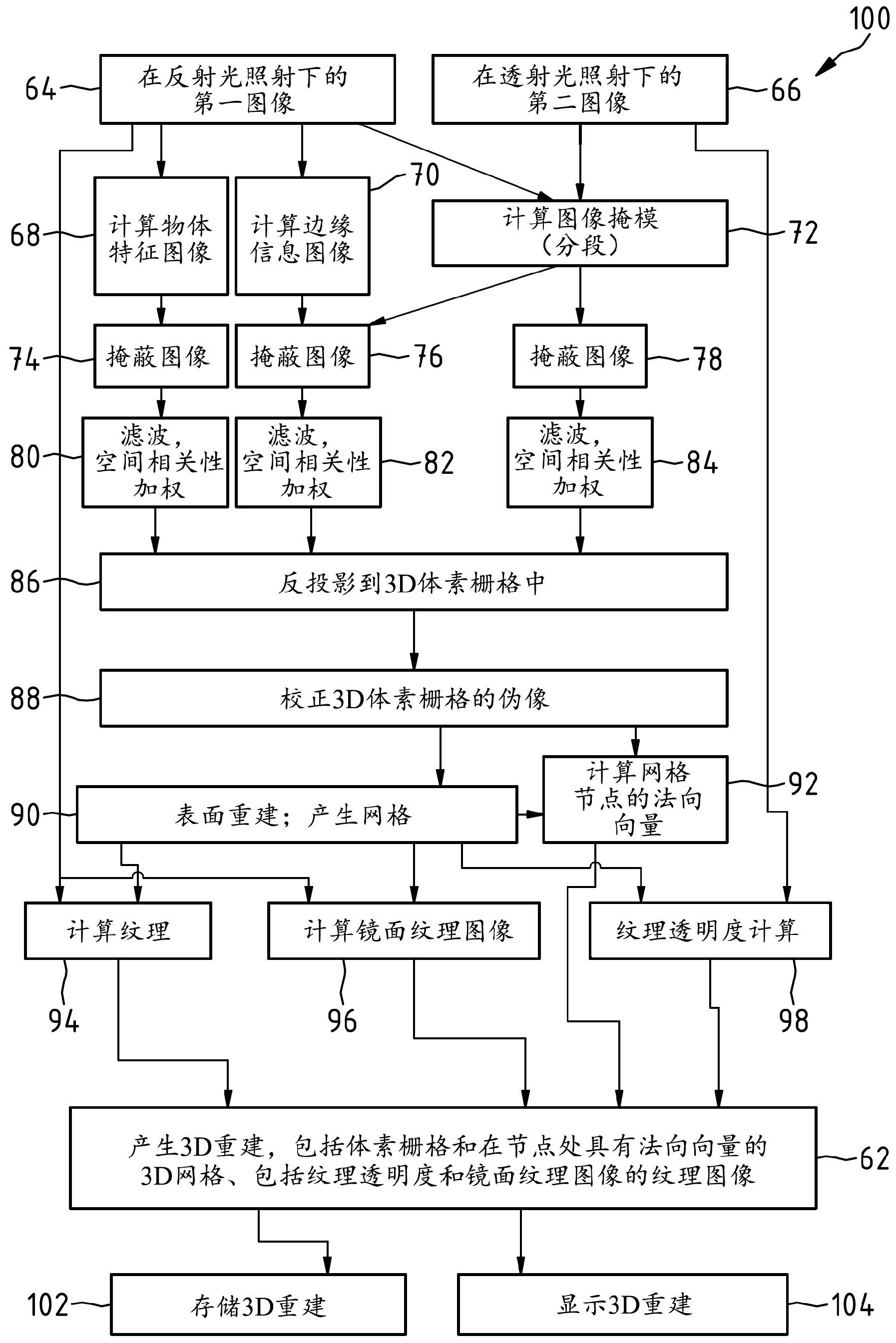
本发明的目的是促进对物体的更准确3D重建,所述物体还可以具有至少部分地对 光透明的区段、至少部分地反射所述光的区段、或发光的区段。 这种物体通过权利要求1描述的方法和权利要求15指定的设备来实现。在从属权 利要求中详细说明了本发明的有利实施例。 根据本发明的用于生成物体的3D重建的方法包括:照射所述物体,捕捉关于所述 物体的图像数据;以及根据所述图像数据来计算所述物体的3D重建。在此,所述图像数据包 括第一图像数据和第二图像数据,其中,所述第一图像数据是在用照射光来照射所述物体 时从不同的记录方向捕捉到的,所述照射光的至少一部分关于物体成像束路径而言是照射 所述物体的反射光,其中,所述第二图像数据是在用照射光来照射所述物体时从不同的记 录方向捕捉到的,所述照射光的至少一部分关于物体成像束路径而言是照射所述物体的背 景光,并且所述物体的3D重建是根据所述第一图像数据和所述第二图像数据来计算的。 在此,照射物体的反射光应理解为是指入射到物体上、并且从物体的光学有效表 面、即从物体的光散射或光反射表面被散射或反射到通向像平面的、将物体成像到图像捕 捉装置的像平面上的束路径中的光。 在此,照射物体的背景光应理解为是指入射到物体上、并且从物体的背景到达将 物体成像到图像捕捉装置的像平面上的束路径中的光,并且所述光的至少一部分在像平面 中产生物体的剪影的图像、即物体的外形的图像。对于照射物体的背景光,像平面中的物体 因此看起来至少部分地背光。 根据本发明的用于生成物体的3D重建的方法尤其可以包括:照射所述物体;以及 在相应的物体成像束路径上捕捉所述物体的具有图像数据的多个图像;以及根据所捕捉的 图像的图像数据来计算所述物体的3D重建。在此,所捕捉的所述物体的多个图像包含具有 图像数据的第一图像和第二图像。所述第一图像是在用照射光来照射所述物体时从不同的 记录方向捕捉到的,所述照射光的至少一部分关于相应的物体成像束路径而言是照射所述 物体的反射光。所述第二图像是在用照射光来照射所述物体时从不同的记录方向捕捉到 的,所述照射光的至少一部分沿相应的物体成像束路径被引导。接着,根据第一图像和第二 图像的图像数据来计算所述物体的3D重建。 根据本发明的用于生成物体的3D重建的方法还可以包括:照射所述物体;以及在 物体成像束路径中在所述物体相对于至少一个图像捕捉装置的不同布置的情况下,通过所 述至少一个图像捕捉装置来捕捉所述物体的具有图像数据的多个图像,以及根据所捕捉的 图像的图像数据来计算所述物体的3D重建,其中,所捕捉的所述物体的多个图像包含具有 图像数据的第一图像和第二图像,其中,所述第一图像是在用照射光来照射所述物体时针 对所述物体相对于至少一个图像捕捉装置的不同布置而捕捉到的,所述照射光的至少一部 分关于物体成像束路径而言是照射所述物体的反射光,并且其中,所述第二图像是在用照 射光来照射所述物体时针对所述物体相对于所述至少一个图像捕捉装置的不同布置而捕 5 CN 111602177 A 说 明 书 3/18 页 捉到的,所述照射光的至少一部分沿物体成像束路径被引导至所述至少一个图像捕捉装 置。接着,根据第一图像和第二图像的图像数据来计算所述物体的3D重建。 根据本发明的用于生成物体的3D重建的设备包含:用于用照射光来照射所述物体 的装置;用于捕捉关于所述物体的图像数据的装置;以及用于根据所捕捉的图像数据来计 算所述物体的3D重建的装置。所捕捉的图像数据包含第一图像数据和第二图像数据,其中, 所述第一图像数据是在用照射光来照射所述物体时从不同的记录方向捕捉到的,所述照射 光的至少一部分关于物体成像束路径而言是照射所述物体的反射光,其中,所述第二图像 数据是在用照射光来照射所述物体时从不同的记录方向捕捉到的,所述照射光的至少一部 分沿物体成像束路径被引导,并且所述物体的3D重建是根据所述第一图像数据和所述第二 图像数据来计算的。 根据本发明的用于生成物体的3D重建的设备尤其可以包括:用于用照射光来照射 所述物体的装置;以及用于在相应的物体成像束路径上捕捉所述物体的具有图像数据的多 个图像的装置;以及用于根据所捕捉的图像来计算所述物体的3D重建的装置,其中,所捕捉 的所述物体的多个图像包含具有图像数据的第一图像和第二图像,其中,所述第一图像是 在用照射光来照射所述物体时从不同的记录方向捕捉到的,所述照射光的至少一部分关于 相应的物体成像束路径而言是照射所述物体的反射光,其中,所述第二图像是在用照射光 照射所述物体时从不同的记录方向捕捉到的,所述照射光的至少一部分沿相应的物体成像 束路径被引导,并且其中,所述物体的3D重建是根据第一图像和第二图像的图像数据来计 算的。 作为其替代方案,根据本发明的用于生成物体的3D重建的设备还可以包含:用于 用照射光来照射所述物体的装置;以及用于在物体成像束路径中在所述物体相对于至少一 个图像捕捉装置的不同布置的情况下通过所述至少一个图像捕捉装置来捕捉所述物体的 具有图像数据的多个图像的装置,其中,设置了用于根据所捕捉的图像来计算所述物体的 3D重建的装置,并且其中,存在用于用照射光来照射所述物体的装置,所述照射光的至少一 部分关于物体成像束路径而言是照射所述物体的反射光,并且所述照射光还利于用其中至 少一部分光沿所述物体成像束路径被引导至所述至少一个图像捕捉装置的照射光来照射 所述物体。在此,根据通过用于捕捉物体的具有图像数据的多个图像的装置所捕捉的多个 图像中的第一图像和第二图像的图像数据来计算所述物体的3D重建,其中,所述第一图像 是在用照射光照射所述物体时针对所述物体相对于所述至少一个图像捕捉装置的不同布 置而捕捉到的,所述照射光的至少一部分关于所述物体成像束路径而言是照射所述物体的 反射光,并且其中,所述第二图像是在用照射光来照射所述物体时针对所述物体相对于所 述至少一个图像捕捉装置的不同布置而捕捉到的,所述照射光的至少一部分沿物体成像束 路径被引导至所述至少一个图像捕捉装置。 被生成3D重建的物体尤其可以是眼镜架。 在当前情况下,图像捕捉装置到物体的物体成像束路径是将物体全部或部分地成 像到图像捕捉装置的像平面中的光束路径。 在当前情况下,关于物体成像束路径而言的照射物体的反射光应理解为是指照射 物体并且在过程中在物体的光散射或反射表面处被散射或反射到将物体成像的物体成像 束路径中的光。 6 CN 111602177 A 说 明 书 4/18 页 通过不仅在用其中至少一部分光关于物体成像束路径而言是照射物体的反射光 的照射光来照射物体时、并且还在用其中至少一部分光沿物体成像束路径被引导至所述至 少一个图像捕捉装置的照射光来照射物体时针对物体相对于图像捕捉装置的不同布置来 捕捉具有图像数据的图像,可以识别物体的透明结构并且在物体的3D重建中考虑这些结 构。 确定物体的断层重建以计算物体的3D重建是有利的。以此方式,特别地,可以为薄 的物体指明准确的3D重建。 在当前情况下,物体的断层3D重建应理解为是指如德国专利申请DE 10 2018 209 570.1中描述的用于生成物体的三维图像表示的方法,在此对其进行引用并且将其披露内 容全部并入本发明的描述中。这种方法将物体的三维图像表示、即物体的断层3D重建表示 为3D体素栅格,这是根据例如所捕捉的可用于物体的强度图像计算出的。 原则上,强度图像还可以是彩色图像。因此,可以针对第一图像和第二图像两者在 每个颜色通道上独立地执行上述计算,所述第一图像是在用照射光照射物体时针对物体相 对于所述至少一个图像捕捉装置的不同布置而捕捉到的,所述第二图像是在用其中至少一 部分光沿物体成像束路径被引导至所述至少一个图像捕捉装置的照射光照射物体时针对 物体相对于至少一个图像捕捉装置的不同布置而捕捉到的。 断层3D重建的方法包含以下步骤: - 使用高通滤波器、Ram-Lak滤波器Shepp-Logan滤波器、通用Hamming滤波器、低通余 弦滤波器,通过计算物体特征图像或通过在额外的滤波步骤中突显图像中的边缘而使得在 物体的3D重建中仅可见其外边缘,来对关于物体的强度图像预处理,如在例如以下出版物 中描述的:R.Cierniak,“X-ray computed tomography in biomedical engineering [生 物医学工程中的X射线计算机断层扫描]”,Springer Science & Business Media [施普林 格科学与商业媒体](2011),在此对其进行引用并且将其披露内容全部并入本发明的描述 中。 - 根据经预处理的图像来构建3D体素栅格,所述3D体素栅格的分辨率取决于所需 的重建准确度。 在当前情况下,体素应被理解为是指三维栅格中的栅格点。3D体素栅格在计算机 单元中表示3D物体。举例而言,如果体素位于物体内或物体表面上,则它被指派大于0且小 于或等于1的值。如果体素位于物体之外,则它被指派值0。在半透明物体的情况下,体素的 值指明了物体在这个点处的透明程度。在不透明物体的情况下,在物体之外假设值为0,而 在物体内假设值为1。 - 通过编码和解码功能对每个体素计算栅格中的强度。在此过程中将应用以下步 骤: a. 通过相关联的图像捕捉装置的成像参数来在每个经预处理的所捕捉图像中投影体 素中心; b. 读取像素的强度; c. 用与体素距相关联图像捕捉装置的距离成反比的权重因子对强度进行加权(编码 功能);以及 d. 计算所有捕捉图像的加权强度的总和(解码功能)。 7 CN 111602177 A 说 明 书 5/18 页 这产生了具有三维强度分布的3D体素栅格,其最大值对应于3D物体点。 通过滤波器和/或神经网络对3D体素栅格进行伪像校正是有利的。这可以提高物 体的3D重建的准确度,甚至在不同的复杂的物体几何的情况下,物体的3D重建仍精确地重 现物体。还有利的是,计算物体的3D重建包括针对至少一些第一图像来计算物体特征图像。 这允许将3D重建限于经滤波的特征,并且因此可以实现在计算物体的3D重建时计算时间和 待处理数据的减少。 举例而言,物体特征图像中的每个像素可以包含这个像素中是否存在物体的某个 特征的信息。特别地,检测到的特征可以是边缘、拐角、所谓的斑点或其他重要像素,即“兴 趣点”。特别地,物体特征图像可以是带有图像像素的二进制图像,其中假设W = 0的值或W = 1的值。W = 1的值意味着在这个像素中存在所寻求的特征、例如边缘。W = 0的值表明情 况并非如此。替代性地,物体特征图像还可以包含在区间[0,1]内的值,所述值代表存在所 寻求特征的概率。其他值也是可能的,例如,当将所捕捉的图像与一个或多个用于检测特定 特征的滤波核(例如用于纹理分析的伽柏(Gabor)滤波器,用于检测重要像素的SIFT特征) 进行卷积时具有滤波器响应的向量,如在以下出版物中描述的:D.G . Lowem , “Object recognition from local scale invariant features; Proceedings of the International Conference on Computer Vision [从局部尺度不变特征识别物体;国际 计算机视觉会议的会议记录]”, ICCV '99, 1150-1157(1999),在此对该文献进行引用并 且将其披露内容全部并入本发明的描述中。 还可以使用:SURF特征检测器,如在以下出版物中描述的:H .Bay , A .Ess , T.Tuytelaars和L.Van Gool , “Speeded-Up Robust Features (surf) [加速稳健特征 (surf)]”, Comput. Vis. Image Underst.[计算机视觉与图像理解], 110 (3) , 346-359 (2008),在此对该文献进行引用并且将其披露内容全部并入本发明的描述中;或AKAZE特征 检测器,如在以下出版物中描述的:A. B . Pablo Alcantarilla , J . Nuevo: “Fast explicit diffusion for accelerated features in nonlinear scale spaces [对非线 性尺度空间中的加速特征进行快速显式扩散]”; 在英国机器视觉会议的会议记录中, BMVA Press [BMVA出版社], 2013,在此对该文献进行引用并且将其披露内容全部并入本 发明的描述中;或MSER特征检测器,如从以下出版物已知的:Matas, O. Chum, M. Urban, T . Pajdla , “Robust Wide Baseline Stereo from Maximally Stable Extremal Regions [最大稳定极值区域的稳健宽基线立体视觉]”, Proc . BMVC , 36 .1-36 .10 (2002)。在此对该出版物也进行引用并且将其披露内容全部并入本发明的描述中。此外,可 以将多个上述检测器进行组合。特别地,可以使用通过机器学习针对专用任务、比如检测例 如眼镜架的镜架边缘进行学习过的滤波器。 由于物体的特征通常不能在一个像素上精确定位,因此可以通过高斯函数对每个 检测到的特征进行局部加权。应注意的是,物体特征图像可以具有例如来自边缘、拐角和伽 柏(Gabor)特征的组中的单一物体特征或多个物体特征作为特征。 通过机器学习或通过神经网络来计算物体特征图像意味着不必在用于根据所捕 捉图像来计算物体的3D重建的装置中提前设定特征。接着,所述装置本身中的算法可以学 习物体的特征以及应如何检测这些特征。这同样可以提高针对物体计算的3D重建的准确 度。 8 CN 111602177 A 说 明 书 6/18 页 为了计算物体的3D重建,尤其可以提供的是确定分段图像掩模并且提供通过分段 图像掩模从第一图像和/或第二图像的至少一部分中切出物体部分。 在当前情况下,分段图像掩模应被理解为是呈二进制图像形式的物体图像表示的 图像,其中属于待重建的物体图像表示的像素精确地具有为1的值,并且其中背景像素的值 为0。 特别地,可以通过机器学习、初始地通过放置轮廓点来将待分段图像手动分段并 且然后训练神经网络来标识图像掩模,来确定分段图像掩模。作为其替代方案或附加于此, 可以为已知的3D物体及其分段图像掩模生成模拟图像数据,并且这些图像数据可以用作神 经网络的训练数据。在此,有利的是将第一捕捉图像和第二捕捉图像均用作神经网络的输 入,因为基于这两个图像数据来计算分段图像掩模更加准确。 计算物体的3D重建还可以包括根据第一和/或第二图像来计算边缘信息图像。 边缘信息图像应理解为是指可用于特定“边缘”特征的物体特征图像。原则上,可 以使用不同的滤波器来检测边缘,例如Canny边缘检测器,如在以下出版物中描述的:W. Rong、Z. Li, W. Zhang和L. Sun“, An Improved Canny Edge Detection Algorithm [一 种改进的Canny边缘检测算法]”, IEEE国际机电一体化与自动化会议, 天津, 577-582 (2014),在此对该文献进行引用并且将其披露内容全部并入本发明的描述中;或如US 2015/362761 A中描述的,在此对文献进行引用并且将其披露内容全部并入本发明的描述 中;或者如在以下出版物中描述的:R .C . Bolles , H .H . Baker , D .H . Marimont , “Epipolar-Plane Image Analysis: An Approach to Determining Structure from Motion [外极平面图像分析:一种根据运动来确定结构的方法]”, International Journal of Computer Vision [国际计算机视觉杂志], 1, 7-55 (1987),在此对该文献 进行引用并且将其披露内容全部并入本发明的描述中;或霍夫变换(Hough transforms), 如在以下出版物中描述的:R.O. Duda, P.E. Hart, “Use of the Hough Transformation to Detect Lines and Curves in Pictures [使用霍夫变换来检测图片中的线和曲线]”, Comm. ACM, 15, 11-15 (1972),在此同样对文献进行引用并且将其披露内容全部并入本 发明的描述中;或结构张量,如在以下出版物中描述的:S. Wanner , B . Goldlucke , “Globally Consistent Depth Labeling of 4D Light Fields [4D光场的全局一致深度 标记]”, Computer Vision and Pattern Recognition [计算机视觉与模式识别] (CVPR) , 2012 IEEE会议, IEEE (2012),在此同样对该文献进行引用并且将其披露内容全 部并入本发明的描述中。应注意的是,通过所谓的机器学习来学习过的边缘检测滤波器也 可以用于检测经特殊训练的边缘。 特别地,对物体的3D重建的计算可以基于根据物体特征图像和/或边缘信息图像 来计算外极平面图像而进行。 图1是利用外极几何关系根据所捕捉的图像来计算外极平面图像的展示。 在计算物体的深度图和3D重建时可使用所谓的外极几何。参见图1,在物体12相对 于图像捕捉装置的每种布置中,物体的3D点5映射到图像捕捉装置的像平面的某个像素x (1)。相反,如果在记录的图像中考虑选定的像素x(1),则在具有不同深度的所有3D点的3D空 间中的整条线对应于这个像素,所述3D点映射到这一个像素上。可以根据选定的像素以及 图像捕捉装置的已知成像参数来计算这条线。在关于物体相对于图像捕捉装置的不同布置 9 CN 111602177 A 说 明 书 7/18 页 的第二记录图像中,这条3D线被投影到2D线4(2)上。这是所谓的外极线。选定的3D物体点的 图像表示也必须位于其上。这很大程度地限制了搜索区域,因此通过计算外极线4(2)简化了 在不同的捕捉图像中检测相应点的问题。在通过图像捕捉装置捕捉到的针对物体的不同布 置的两个图像中检测对应点允许通过三角测量、借助于图像捕捉装置的成像参数来推导相 关联的3D点5的深度。为了简化外极线4(2),…,4(n)的计算,可以应用多种方法,例如将图像 对相对于所捕捉图像中的某个图像进行修正或通过图像旋转,如在以下出版物中描述的: R. Hartley和A.Zisserman, “Multiple View Geometry in Computer Vision [计算机视 觉中的多视图几何]”, 剑桥大学出版社, 纽约, 美国纽约州, 第2版(2003),在此对该文 献进行引用并且将其披露内容全部并入本发明的描述中。 参见图1,外极平面图像Ex,k(y,t)应理解为是指由像素y构建的图像1,所述图像是 基于外极几何根据以下多个图像2(1)、2(2)、…、2(n-1)、2(n)并且考虑图像捕捉装置k的已知成 像特性来计算的,所述多个图像是在所述图像相对于图像捕捉装置k的已知的不同布置中、 通过图像捕捉装置k在不同时刻t捕捉到的关于物体12的图像。 为此,对于第一捕捉图像2(1)中的每个选定像素x(1)、…,在每个另外的捕捉图像2 (2)、…、2(n)中指明所谓的极线4(2)、…、4(n)。因此,对于物体在图像捕捉装置前方的各种布 置,针对第一捕捉图像2(1)中的选定像素x(1),外极平面图像Ex,k(y,t)包含在对应的另外的 捕捉图像2(2)、…、2(n-1)、2(n)中的相关联外极线4(2)、… 4(n)。因此,在具有像素y的每条图像 线中,外极平面图像Ex,k(y,t)包含关于图像捕捉装置k在时刻t捕捉到的相应图像中的选定 像素x的外极线4(2)、… 4(n)的强度。 如果在捕捉图像2(1)、2(2)、…、2(n-1)、2(n)时物体12和图像捕捉装置k相对于彼此沿 着直线轨迹移动,则外极平面图像Ex,k(y,t)相应地包含呈直线6形式的物体点轨迹,所述物 体点轨迹描述了物体12的属于所述选定像素的3D点5的移动。应注意的是,使图像捕捉装置 捕捉的图像失真就足以能够在外极平面图像中获得直线。 接着,根据这条直线6的梯度来确定3D点5相对于图像捕捉装置的空间深度,所述 梯度对应于深度相关性偏离量,即,立体深度估计方法中的所谓“视差”。 原则上,可以使用各种图像处理方法来检测呈直线6形式的物体点轨迹并确定其 梯度。举例而言,检测物体点轨迹和确定其梯度可以如下进行:基于霍夫变换,通过结构张 量计算,通过基于对称的计算方法、比如散焦深度计算之类的方法,或通过凸超分辨率,如 K.Polisano等人, “Convex super-resolution detection of lines in images [图像中 的线的凸超分辨率检测]”, 信号处理会议(EUSIPCO),2016年第24届欧洲IEEE,(2016),在 此对该文献进行引用并且将其披露内容全部并入本发明的描述中;或如在以下出版物中指 明的:M.W . Tao , S . Hadap , J . Malik和R . Ramamoorthi , “Depth from Combining Defocus and Correspondence Using Light-Field Cameras [使用光场相机来将散焦与 通信相结合的深度]”, 2013 IEEE国际计算机视觉会议(ICCV '13)的会议记录, IEEE计算 机协会, 华盛顿特区, 美国, 673-680 (2013),在此同样对该文献进行引用并且将其披露 内容全部并入本发明的描述中。 根据本发明,可以如下来执行物体的外极几何3D重建: 在第一步骤中,通过确定物体的固有和非固有成像参数并且确定用于生成物体的3D重 建的设备中的每个图像捕捉装置相对于相应的其他图像捕捉装置的空间位置,来校准图像 10 CN 111602177 A 说 明 书 8/18 页 捕捉装置。然后,在另一步骤中校准用于将物体相对于图像捕捉装置移动的装置。作为这个 校准过程的结果,获得了针对物体相对于图像捕捉装置的每种布置的旋转矩阵和平移向 量。 图像捕捉装置的非固有成像参数描述了比如图像捕捉装置的光轴相对于另一图 像捕捉装置或预定坐标系的相对对准等特性。固有成像参数定义了被成像在图像捕捉装置 的图像传感器的像平面中的点在相对于对应图像捕捉装置的坐标系中的坐标如何转换为 这个点在图像传感器的像平面中的像素的坐标。 例如在由R.Hartley和A Zisserman(第2版,剑桥大学出版社(2004年)的教材 “Multiple View Geometry in Computer Vision(计算机视觉的多视图几何)”第8页中可 以找到关于相机形式的图像捕捉装置的校准的综合解释,在此对该文献进行引用并且将其 披露内容全部并入本发明的描述中。 然后,检测所捕捉图像的图像数据中的边缘和特征,以进行物体的外极几何3D重 建。 随后,针对每个检测到的特征来计算外极平面图像。 接着,在外极平面图像中检测物体点轨迹,并计算物体点轨迹的梯度。 接着,使用图像捕捉装置的成像参数来确定相关联的深度。 因此,对于每个特征点显现点云的3D点,所述点云表示物体的3D重建。 应注意的是,同时使用多个图像捕捉装置以及使用误差最小化方法(例如求平均 或稳健估计器,比如所谓的“随机样本一致性”(RANSAC)方法,例如在 https://en.wikipedia.org/wiki/Random_sample_consensus (2017年11月16日)中描述的)允许计算更稳健的3D重建,在此对所述文献进行引用并 且将其披露内容全部并入本发明的描述中。 有利的是,计算物体的3D重建要实施:根据外极平面图像来计算物体点轨迹,以及 测量所计算的物体点轨迹的梯度,并且通过三角测量来估计深度信息,以形成所述物体的 外极几何3D重建。由此,不再需要通过比较图像区段来执行深度计算,这允许重建非常薄的 结构。 如果物体具有对光透明的结构,则计算物体点轨迹也会为物体的3D重建带来稳健 性,因为在这种情况下各个物体点的颜色逐渐地或在几个图像上具有极小影响或没有影 响。这是因为物体点轨迹是作为所有图像上的线来计算。 特别地,可以提供的是,在空间相关性加权和可能的滤波之后,通过将第一图像和 第二图像的图像数据反投影到3D体素栅格中,来确定物体的断层重建以计算物体的3D重 建,其中,通过计算将物体的外极几何3D重建与所述3D体素栅格组合以形成物体的3D重建。 由此,物体的3D重建甚至对于不同的物体几何也可以是可靠且准确的,这是因为 在这种情况下,物体的外极几何3D重建和物体的断层3D重建中的误差通过求平均而消失。 可以通过滤波器和/或神经网络来校正3D体素栅格的伪像,来进一步提高物体的 3D重建的准确度。 优选地,根据3D体素栅格来计算用于描述物体表面的网格。与点云相比,这允许更 快地处理3D数据。应注意的是,可以通过以下方式来从3D体素栅格中提取网格:均值偏移法 或移动立方体法,例如在以下出版物中描述的:F. Isgro, F. Odone , W. Saleem and & 11 CN 111602177 A 说 明 书 9/18 页 O. Schal, “Clustering for Surface Reconstruction [用于表面重建的聚类]”, 1st International Workshop towards Semantic Virtual Environments [第一届面向语义 虚拟环境的国际研讨会], 瑞士维拉尔: MIRALab., 156-162 (2005),在此对该文献进行 引用并且将其披露内容全部并入本发明的描述中,或如在以下出版物中描述的:F. Zhou, Y. Zhao, K.-Liu Ma, “Parallel mean shift for interactive volume segmentation [用于交互式体积分段的平行均值偏移]”, Machine learning in medical imaging [医 学成像中的机器学习], Lecture notes in Computer science [计算机科学讲义], 67- 75 (2010),在此同样对该文献进行引用并且将其披露内容全部并入本发明的描述中;或通 过泊松重建方法,如在以下出版物中描述的:M. Kazhdan , M . Bolitho , H . Hoppe , “Poisson surface reconstruction [泊松表面重建]”, Proceedings of the fourth Eurographics symposium on Geometry processing [第四届欧洲图形学几何处理研讨会 的会议记录](SGP '06) , Eurographics Association [欧洲图形协会], Aire-la-Ville [艾尔拉维尔], 瑞士, 瑞士,61-70 (2006),在此对该文献进行引用并且将其披露内容全 部并入本发明的描述中;或在以下出版物中描述的:M. Kazhdan , Michael & Bolitho , Matthew & Hoppe, Hugues, “Screened Poisson Surface Reconstruction [筛选式泊松 表面重建]”, ACM Transactions on Graphics [ACM图形交易], 32. 61-70 (2006),在此 同样对该文献进行引用并且将其披露内容全部并入本发明的描述中。 在当前情况下,点云应理解为是指向量空间中的具有无组织空间结构的点集。这 些点表示3D物体表面上的点。点云通常是计算具有网格和纹理的3D模型的中间步骤。 还应注意,网格可以具有带有纹理坐标的节点,其中,纹理坐标指的是具有纹理信 息的纹理图像,所述纹理图像是通过将所捕捉的第一图像投影并叠加在3D重建上并使用图 像捕捉装置的固有和非固有成像参数计算出的,如在出版物A. Baumberg , “Blending Images for Texturing 3D Models [融合图像以纹理化3D模型]”, BMVC (2002) . Baumberg的第5页中描述的,在此同样对该文献进行引用并且将其披露内容全部并入本发 明的描述中。 在当前情况下,纹理图像应被理解为是指描述物体的3D重建的表面点的外观的特 性(尤其颜色和反射特性)的图像。纹理可以由颜色值组成,例如2D图像。然而,物体的反射 特性也可以额外存储在纹理中。所谓的“纹理映射”是为物体表面上或网格上的每个3D点指 派一个或多个纹理坐标的映射。纹理坐标确定了纹理点向物体表面的3D点的指派。 可以分析沿着物体点轨迹的强度曲线,以估计所重建物体的反射特性。在纯漫反 射的表面点的情况下,在相对于图像捕捉装置的各种物体布置上,这种强度曲线在很大程 度上是恒定的。随着镜面反射分量的增加,强度逐渐偏离恒定曲线。可以根据这个信息以类 似于漫射纹理图像的方式、即纯颜色信息来生成镜面纹理图像。 举例而言,可以通过将第一图像投影到网格上来计算这种纹理图像。替代性地,可 以将来自多通道3D体素栅格的颜色或强度值例如作为相应网格节点的直接相邻体素的平 均值传递到网格上。可以根据3D体素栅格通过导数滤波器来计算网格法线。 物体的3D重建包含关于根据第二图像计算纹理透明度而获得的计算出的纹理透 明度的信息。 纹理透明度描述了3D物体的表面的透光率。除了颜色信息外,它也被存储在纹理 12 CN 111602177 A 说 明 书 10/18 页 的所谓的α通道中。α通道通常采用在区间[0,1]内的值。值为1是指此时纹理是不透明的;相 反,值为0表示纹理不可见。对于在[0,1]范围内的中间值,将纹理用位于其后的纹理进行线 性插值。为了确定纹理透明度,可以根据所捕捉的第二图像、通过将网格的节点投影到所捕 捉的各个第二图像中来估计纹理的所谓α通道。纹理变得越透明并且α值减小,所捕捉图像 中的所成像点就越亮。 通过计算纹理透明度,可以根据在用其中至少一部分光沿物体成像束路径被引导 到至少一个图像捕捉装置的照射光来照射物体时针对所述物体相对于所述至少一个图像 捕捉装置的不同布置而获得的第二图像来确定纹理的透明度。 特别地,可以根据第一和/或第二图像来计算镜面纹理图像,其中,物体的3D重建 包含所计算出的纹理图像的信息。 可以通过所捕捉的图像是彩色图像,来实现所计算出的物体的3D重建的高准确 度,因为例如可以以这种方式来估计3个颜色通道的信息,而不仅仅是来自单一灰度值通道 的信息。 特别有利的是通过计算将物体的多个3D颜色通道重建进行组合、尤其通过求平均 或稳健估计器,例如在RANSAC方法的范围内,来确定物体的3D重建,其中,接着根据第一图 像和第二图像的图像数据、针对颜色通道和/或纹理透明度通道来计算每个3D颜色通道重 建。甚至在不同的物体几何的情况下,这也允许进一步提高所计算的物体3D重建的准确度。 所计算的物体3D重建可以具有纹理信息。 通过将物体的视图反射到图像捕捉装置中可以实现的是,图像捕捉装置可以从不 同的侧面捕捉物体并且因此还可以记录可能被覆盖的结构。 有利的是,计算物体的3D重建包括通过根据第二图像的图像数据计算出的物体剪 影来计算视觉外壳,如在以下出版物中描述的:Y. Shuntaro等人, “The Theory and Practice of Coplanar Shadowgram Imaging for Acquiring Visual Hulls of Intricate Objects [共面阴影图成像用于获取复杂物体视觉外壳的理论与实践]”, International Journal of Computer Vision [国际计算机视觉杂志], 81 , 259-280 (2008),在此对该文献进行引用并且将其披露内容全部并入本发明的描述中;或在以下出 版物中描述的:G. Haro, “Shape from silhouette consensus and photo-consistency [根据剪影共识和光一致性的成形]”, 2014年IEEE图像处理国际会议 (ICIP) , 巴黎, 4837-4841 (2014),在此同样对该文献进行引用并且将其披露内容全部并入本发明的描述 中。 在当前情况下,物体的剪影应理解为是指由于物体到图像捕捉装置的像平面上的 透视投影而产生的二进制图像,至少一个物体点被成像到其上的像平面中的那些点精确地 属于所述剪影。 根据第二图像数据或第二图像的图像数据计算出的物体的剪影来计算视觉外壳 实现了所计算的物体3D重建的准确度的进一步提高,因为物体的视觉外壳指明了对物体的 良好近似。在计算物体的3D重建时,尤其可以考虑所计算的3D体素距视觉外壳的距离。 本发明还扩展至使用上述方法生成的物体、尤其眼镜片的3D重建的可视化,在图 像显示装置、尤其显示器的显示区域上具有网格。此外,本发明还扩展至具有程序代码的计 算机程序,所述程序代码用于尤其通过上述的用于生成物体的3D重建的设备来执行上述方 13 CN 111602177 A 说 明 书 11/18 页 法。 附图说明 在图2至图5中示意性地描绘并且在下文描述了本发明的有利的示例性实施例。 详细而言: 图2 示出了用于生成物体的3D重建的设备的侧视图; 图3 示出了用于生成物体的3D重建的设备的平面视图; 图4 示出了用于生成物体的3D重建的设备中的计算机单元的计算机程序的第一算法; 以及 图5 示出了用于生成物体的3D重建的设备中的计算机单元的计算机程序的第二算法。











