
技术摘要:
本发明提供了一种人员口罩佩戴状态检测方法。该方法包括:利用一定数量的佩戴口罩和不佩戴口罩的人脸图像构建口罩佩戴训练数据集,使用口罩佩戴训练数据集训练SSD目标检测算法,得到口罩佩戴检测模型;利用一定数量的监测区域场景的图像构建监测区域场景的口罩佩戴训练 全部
背景技术:
由于新型冠状病毒具有较强的传染性,佩戴口罩能够有效预防该病毒。轨道交通 作为居民日常通勤和外出远行的主要交通方式之一,长时间聚集大量人群,面临着严峻的 传播风险。一些不佩戴口罩的乘客进入轨道交通车站,不仅给轨道交通车站和其他乘客造 成潜在威胁,还面临着自身被感染的风险。但是轨道交通车站工作人员有限,不能实时查看 每一个乘客。轨道交通车站的监控视频能够监控到车站大多数地方,利用能够检测是否佩 戴口罩的智能算法,可以提高车站的检查效率和监控范围,保障轨道交通场所的广大乘客 的安全。 目前,现有技术中的一种口罩佩戴检测算法包括:基于深度学习的目标检测算法 对是否佩戴口罩进行检测。该方法的原理是构建基于卷积神经网络的目标检测模型,利用 已经标注的训练数据集训练目标检测模型,获得可以自动检测是否佩戴口罩的智能算法。 上述现有技术中的口罩佩戴检测算法的缺点为:由于轨道交通车站场景复杂,监 控视频角度多变,直接使用口罩数据集训练基于深度学习的目标检测算法会出现漏报和误 报问题,不能满足现场应用的需求。
技术实现要素:
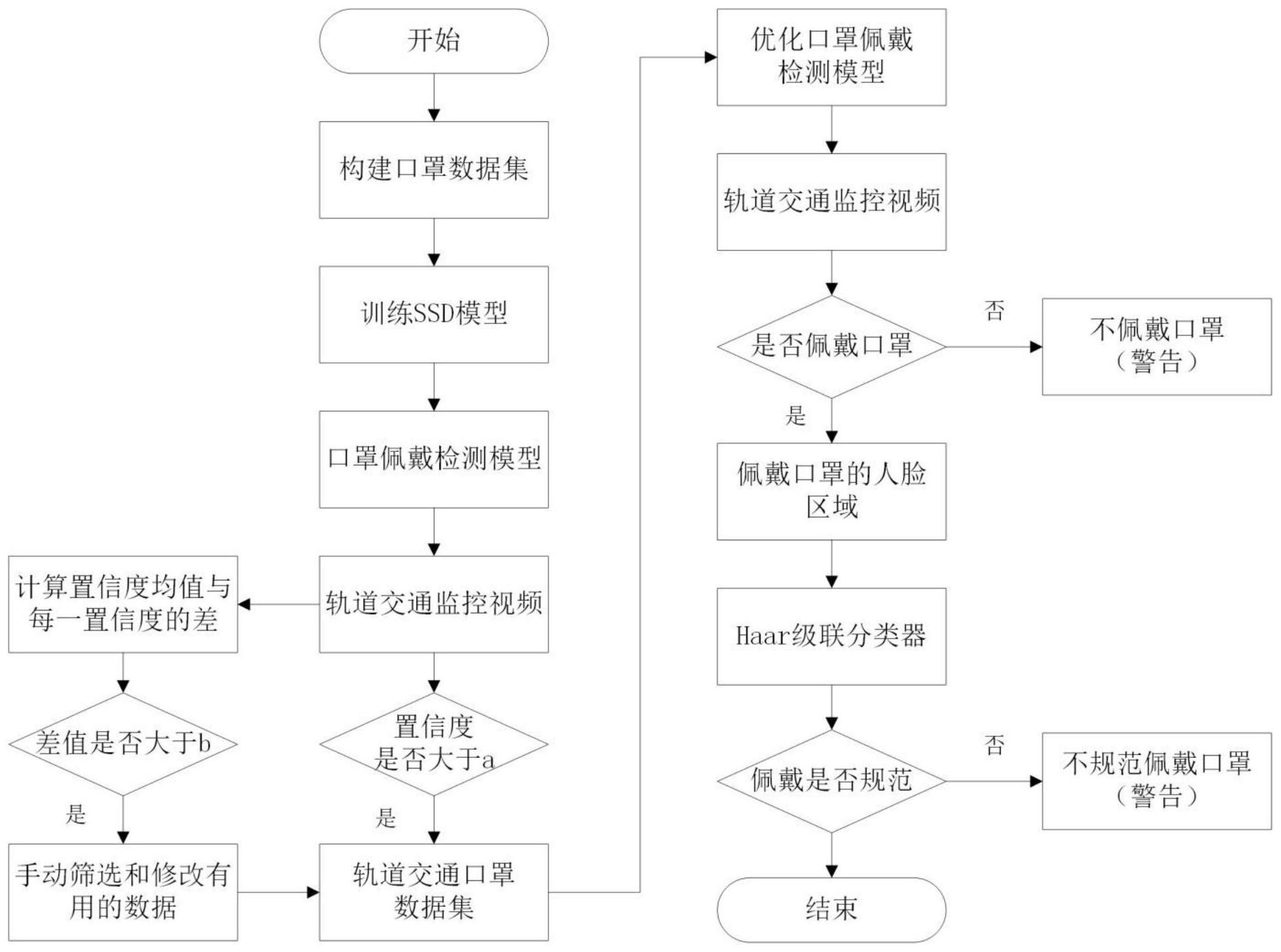
本发明的实施例提供了一种人员口罩佩戴状态检测方法,以克服现有技术的问 题。 为了实现上述目的,本发明采取了如下技术方案。 一种人员口罩佩戴状态检测方法,包括: 利用一定数量的佩戴口罩和不佩戴口罩的人脸图像构建口罩佩戴训练数据集,使 用所述口罩佩戴训练数据集训练SSD目标检测算法,得到口罩佩戴检测模型; 利用一定数量的监测区域场景的图像构建监测区域场景的口罩佩戴训练数据集, 利用所述口罩佩戴训练数据集训练所述口罩佩戴检测模型,得到适用于监测区域场景的训 练好的口罩佩戴检测模型; 将待检测的监测区域场景的图像输入所述训练好的口罩佩戴检测模型,所述训练 好的口罩佩戴检测模型输出图像中的人员口罩佩戴状态检测结果。 优选地,所述的利用一定数量的佩戴口罩和不佩戴口罩的人脸图像构建口罩佩戴 训练数据集,使用所述口罩佩戴训练数据集训练SSD目标检测算法,得到口罩佩戴检测模 型,包括: 获取一定数量的佩戴口罩和不佩戴口罩的人脸图像,分别标注类型为佩戴口罩和 不佩戴口罩,并且标注每个人脸图像中人脸的长和宽,利用佩戴口罩和不佩戴口罩的人脸 图像构建口罩佩戴训练数据集,在佩戴训练数据集中记录每个人脸图像中人脸的长宽比数 4 CN 111582068 A 说 明 书 2/6 页 据; 构建SSD目标检测算法,使用K-means算法统计所述口罩佩戴训练数据集中记录的 人脸图像中人脸的长宽比,根据统计出的人脸图像中人脸的长宽比设定SSD目标检测算法 中的锚点长宽比为1:1、1:1.4和1:2,调整SSD目标检测算法的训练超参数,优化批处理和学 习率,SSD目标检测算法的批处理设为32,初始学习率为0.001,在70000迭代时下降为 0.0001,在100000迭代时下降为0.00001,得到参数优化后的SSD目标检测算法; 使用口罩佩戴训练数据集训练所述参数优化后的SSD目标检测算法,训练后得到 口罩佩戴检测模型。 优选地,所述的利用一定数量的监测区域场景的图像构建监测区域场景的口罩佩 戴训练数据集,利用所述口罩佩戴训练数据集训练所述口罩佩戴检测模型,得到适用于监 测区域场景的训练好的口罩佩戴检测模型,包括: 提取监测区域场景的监控视频的每帧图像,将图像缩放至512*512,将每个图像输 入参数优化后的SSD目标检测算法,SSD目标检测算法根据交并比阈值排除重复的人脸图像 后,输出每个图像的特征参数,使用所述口罩佩戴检测模型评估图像的特征参数,得到图像 的多个候选检测结果,每个候选检测结果包括人脸区域的坐标、人脸是否佩戴口罩类别和 相应的置信度,利用非极大值抑制算法从多个候选检测结果中筛选出图像的检测结果输 出; 设置阈值a为0.8,根据每个图像的检测结果,保留置信度大于a的乘客是否佩戴口 罩类别和人脸位置,标注置信度大于a的图像中的乘客人脸区域,将乘客是否佩戴口罩类别 和人脸位置写入第一口罩佩戴数据集; 设置阈值b为0.2,根据每个图像的检测结果,设计主动学习的查询策略计算一张 图像中所有置信度均值与每一个置信度的差值,保留差值大于b的乘客是否佩戴口罩类别 和人脸位置,自动标注差值大于b的乘客人脸区域,将乘客是否佩戴口罩类别和人脸位置写 入第二口罩佩戴数据集; 将所述第一口罩佩戴数据集和所述第二口罩佩戴数据集合并,构建监测区域场景 的口罩佩戴训练数据集,使用迁移学习的方法所述口罩佩戴检测模型作为预训练模型,使 用监测区域场景的口罩佩戴训练数据集训练所述预训练模型,得到适用于监测区域场景的 训练好的口罩佩戴检测模型。 优选地,所述的主动学习的查询策略的计算公式为: 是所有置信度的均值,xi是第i个人脸的置信度。 优选地,所述的将待检测的监测区域场景的图像输入所述训练好的口罩佩戴检测 模型,所述训练好的口罩佩戴检测模型输出图像中的人员口罩佩戴状态检测结果,包括: 提取监测区域场景的每帧图像,将图像缩放至512*512; 将图像输入到所述训练好的口罩佩戴检测模型中,设置交并比和置信度阈值为 0.5,所述训练好的口罩佩戴检测模型输出图像中的人员口罩佩戴状态的检测结果,检测结 果包括:没有乘客、乘客佩戴口罩和乘客没有佩戴口罩; 所述训练好的口罩佩戴检测模型检测到乘客佩戴口罩,则提取佩戴口罩的人脸区 5 CN 111582068 A 说 明 书 3/6 页 域图像,并将提取的人脸区域图像从RGB颜色空间转换为灰度空间,使用Haar级联分类器检 测佩戴口罩的人脸区域是否露出鼻子,输出佩戴口罩是否规范的检测结果。 优选地,所述的使用Haar级联分类器检测佩戴口罩的人脸区域是否露出鼻子,输 出佩戴口罩是否规范的检测结果,包括: 下载并加载鼻子的Haar级联分类器,设置鼻子的Haar级联分类器参数,该参数包 括输入图像、每次图像尺寸缩小的比例和不同比例的人脸区域图像中都检测到鼻子的设定 数量; 将灰度的人脸区域图像进行多次缩小处理,每次图像尺寸缩小的比例为 1 .2,将 不同比例的人脸区域图像输入到Haar级联分类器中,当Haar级联分类器在设定数量个人脸 区域图像中都检测到鼻子,则确定人脸区域中露出了鼻子,输出佩戴口罩不规范的检测结 果。 由上述本发明的实施例提供的技术方案可以看出,本发明实施例的方法考虑到轨 道交通场景等监测区域的特殊性和乘客佩戴口罩的习惯,优化SSD网络的检测框长宽比和 学习率,并使用迁移学习的手段优化口罩检测模型,结合Haar级联分类器,人员口罩佩戴状 态的检测准确率可达到98.2%。 本发明附加的方面和优点将在下面的描述中部分给出,这些将从下面的描述中变 得明显,或通过本发明的实践了解到。 附图说明 为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用 的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本 领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的 附图。 图1是本发明实施例提供的一种基于迁移学习与改进SSD-Haar模型的轨道交通乘 客口罩佩戴状态视频检测方法的实现原理示意图。 图2是本发明实施例提供的一种基于迁移学习与改进SSD-Haar模型的轨道交通乘 客口罩佩戴状态视频检测方法的处理流程图。 图3、图4和图5是本发明实施例提供的轨道交通车站的口罩佩戴检测实验结果示 意图。











