
技术摘要:
本发明公开了一种基于FAQ问答系统的问句匹配方法,通过联合训练术语规范化模块M1和语句规范化模块M2,得到训练完的问句规范系统,再将用户问句输入问句规范系统,得到规范化的问句,计算规范化的问句与原始标准FAQ问答对集中问句的相似度,得到准确的答案。本发明在构 全部
背景技术:
基于FAQ的垂直领域自动问答系统,其常见问题和答案,往往由领域专家搜集整 理,一个问题对应一个答案。也称为问答对。已有的采用FAQ技术实现的问答系统,通过将用 户提出的问题和系统中所列问题,采用基于句子相似度匹配的方式,完成用户问题到所列 问题之间的映射。这种方法的主要缺点有: 一义多词等带来的语义鸿沟。在许多专业领域的问答系统中,比如医学、税收等, 用户(如患者、普通纳税人)提问时的用词和句式等等,和专业问句的表述之间有巨大的语 义鸿沟。比如“呼吸困难”和“出不赢气”;前者是专业表达,后者是普通用户描述,两者语义 相近,但无一字相同。研究人员进一步提出采用词嵌入(word embedding)方式,但这种方式 对每一个词计算一个静态的词向量。接下来,通过余弦相似度计算词相似,然后通过词相似 计算句子相似;或者将一句话所有词的词向量采用累加等方法形成一个总的句子向量,计 算这两个句子向量的余弦相似度。但这些改进对一词多义仍然束手无策且存在下述第二个 缺点。 无法有效利用标注问题集合里的信息。由于标注好的问答句对里面包含了很多可 以利用的规律和信息,利用这些信息,可以有效提升问题系统的质量。如何利用这些信息, 基于传统问题匹配技术,还不充分和不够科学。 低频词权重过高(不知道哪些词更重要)。已有方法在计算用户提问和已有列表问 题的句子相似度时,通常采用tf*idf的加权方法,tf为词频(该词在当前问句中出现的次 数),idf为反文档频次(总问句数除以该词出现的问句数)。但该方法是一种比较粗的计算 方法,和实际问句上下文关系不大。用户问句中由于用户的实际情况千差万别,表达方式各 异,许多词通常只在极少数问题表述中出现。这使得虽然其tf很小,但idf往往很高,两者相 乘之后仍可能被赋予了过高的权重。比如“模特为未成年是否需缴纳个税吗?”和“我家小孩 子还不到18岁,给电商摆拍模特,日收入过千,交不交税?”。在后者的普通用户问题描述中, “摆拍”在已有权重计算方法中权重很高,但由于和其匹配的专业表达中,未出现该词,从而 极大降低该专业表达匹配的概率。但此词显然并不重要。 综上所述,目前的基于句子相似的问题匹配,由于存在用户问句和列表问句存在 语义鸿沟,且句子中关键词加权算法无法细致考虑其所在上下文,导致匹配准确率不高。
技术实现要素:
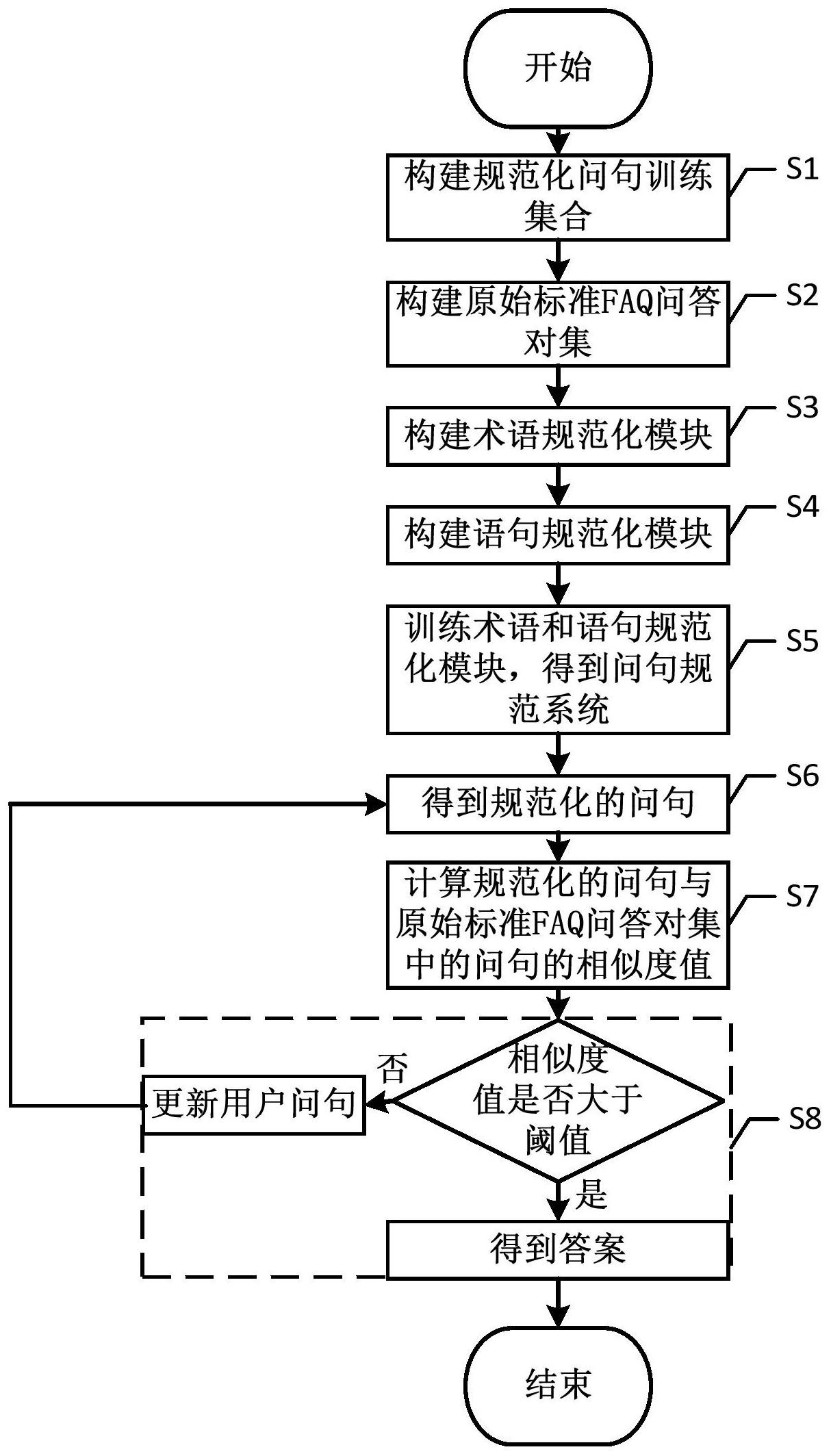
针对现有技术中的上述不足,本发明提供的一种基于FAQ问答系统的问句匹配方 法解决了现有基于FAQ的自动问答技术匹配准确率不高的问题。 为了达到上述发明目的,本发明采用的技术方案为:一种基于FAQ问答系统的问句 4 CN 111597319 A 说 明 书 2/6 页 匹配方法,包括以下步骤: S1、收集用户问句,构建规范化问句训练集合; S2、构建原始标准FAQ问答对集; S3、采用动态softmax方法构建术语规范化模块M1; S4、基于术语规范化模块M1输出logits向量,构建语句规范化模块M2; S5、采用规范化问句训练集合,联合训练术语规范化模块M1和语句规范化模块M2, 得到训练完的问句规范系统; S6、将用户问句,输入问句规范系统,得到规范化的问句; S7、根据匹配检索算法,计算规范化的问句与原始标准FAQ问答对集中的问句的相 似度值; S8、判断相似度值是否大于阈值,若是,则得到与该问句对应的答案;若否,则更新 用户问句,并跳转至步骤S6。 进一步地,步骤S1中构建规范化问句训练集合的过程为: S11、对用户问句进行收集,得到N个用户输入问句集; S12、对N个用户输入问句集进行术语规范化标注,得到N个规范化术语问句构成的 集合,即N个专业问句集; S13、对N个专业问句集进行问句规范化标注,得到N个规范问句构成的集合,即N个 规范问句集; S14、根据N个用户输入问句集、N个专业问句集和N个规范问句集,构建规范化问句 训练集合,其中,规范化问句训练集合为:S={[X1,Y1,Z1],…,[Xi,Yi,Zi],…,[XN,YN,ZN]}, 其中,S为规范化问句训练集合,Xi为第i个用户输入问句集,Xi={xi1,…,xit,…xiT},xit为 第i个用户输入问句集中的第t个用户词,Yi为第i个专业问句集,Yi={yi1 ,…,yit,…yiT}, yit为第i个专业问句集的第t个专业术语词,T为第i个用户输入问句集或第i个专业问句集 的长度,Zi为第i个规范问句集,Zi={zi1,…,zil,…ziL},zil为第i个规范问句集的第l个规 范词,L为第i个规范问句集的长度,1≤i≤N,N为问句总数。 进一步地,所述步骤S5中术语规范化模块M1包括:第一自注意力机制的神经网络、 第一全连接层和第一损失层; 所述问句规范化模块M2包括:第二自注意力机制的神经网络、第二全连接层和第 二损失层; 所述第一自注意力机制的神经网络的输出端分别与第一全连接层的输入端和第 二自注意力机制的神经网络的输入端连接; 所述第一全连接层的输出端与第一损失层的输入端连接; 所述第二自注意力机制的神经网络的输出端与第二全连接层的输入端连接; 所述第二全连接层的输出端与第二损失层的输入端连接。 进一步地,所述术语规范化模块M1通过专业词汇表Vkey={u1,…,uk,…,uK}建立用 户输入问句集Xi和专业问句集Yi之间的映射关系,构建其映射关系的表达式为: 5 CN 111597319 A 说 明 书 3/6 页 其中,uk为专业词汇表Vkey第k个专业术语词,k为专业词汇表Vkey的长度,由上面公 式,得到动态词汇表Vit=Vkey∪{xit},其特征还包括根据映射结果,可用条件概率函数P(w| xit,Xi)来表示这个映射,其中w∈Vit,其特征还有采用基于神经网络transformer来构建术 语规范化模块M1,其输出logits向量Hi,以及利用Hi在动态词汇表Vit上执行动态sotfmax方 法来规范化术语。 进一步地,所述步骤S5中的训练方法为:采用规范化问句训练集合,根据联合损失 函数,通过反向传播算法,并将第一自注意力机制的神经网络的输出logits向量和规范问 句集作为第二自注意力机制的神经网络的输入,迭代训练术语规范化模块M1和问句规范化 模块M2的神经网络参数,得到训练好的问句规范模块;所述反向传播算法采用梯度下降方 式;所述联合损失函数的表达式为: loss=loss1 loss2 其中,loss为联合损失函数,loss1为术语规范化模块M1的损失函数,loss2为问句 规范化模块M2的损失函数。 进一步地,所述术语规范化模块M1的损失函数loss1的表达式为: 其中,hit为输出logits向量Hi的第t个元素,“·”为内积,v(uk)为专业术语词uk的 词向量,ptk表示术语规范化模块M1在动态词汇表Vi,t=Vkey∪{xit}上输出的分布列,ptyit表 示yit对应这个概率序列ptk中的概率,即答案概率。 进一步地,所述问句规范化模块M2的损失函数loss2的表达式为: lpss2=crossentropy(softmax(Li) ,Zi) 其中,crossentropy为交叉熵函数,softmax为逻辑回归函数,Li为向量Hi输入到问 句规范化模块M2后输出的logits向量。 本发明的有益效果为: (1)、本发明在构建规范化问句训练集合时采用二次标注方法,对用户问句进行术 语规范化标注,再对得到的专业问句集进行问句规范化标注,提高用户输入问句集的利用 效率; (2)、两个模块联合训练和应用,术语规范化模块M1为语句规范化模块M2提供增益 信息,提升问句规范系统的性能。 (3)、计算专业词在专业词汇表Veb中的分布列,通过这种方式能自动找到关键词 语赋予更高权重、忽略无关紧要的词语,进而获得更好的问答性能。 (4)、通过将用户输入问句集转换为规范问句集,再通过规范问句集去匹配原始标 6 CN 111597319 A 说 明 书 4/6 页 准FAQ问答对集中的答案,提高了问句匹配的准确度和效率。 附图说明 图1为一种基于FAQ问答系统的问句匹配方法的流程图; 图2为术语规范化模块M1和问句规范化模块M2的结构图。











