
技术摘要:
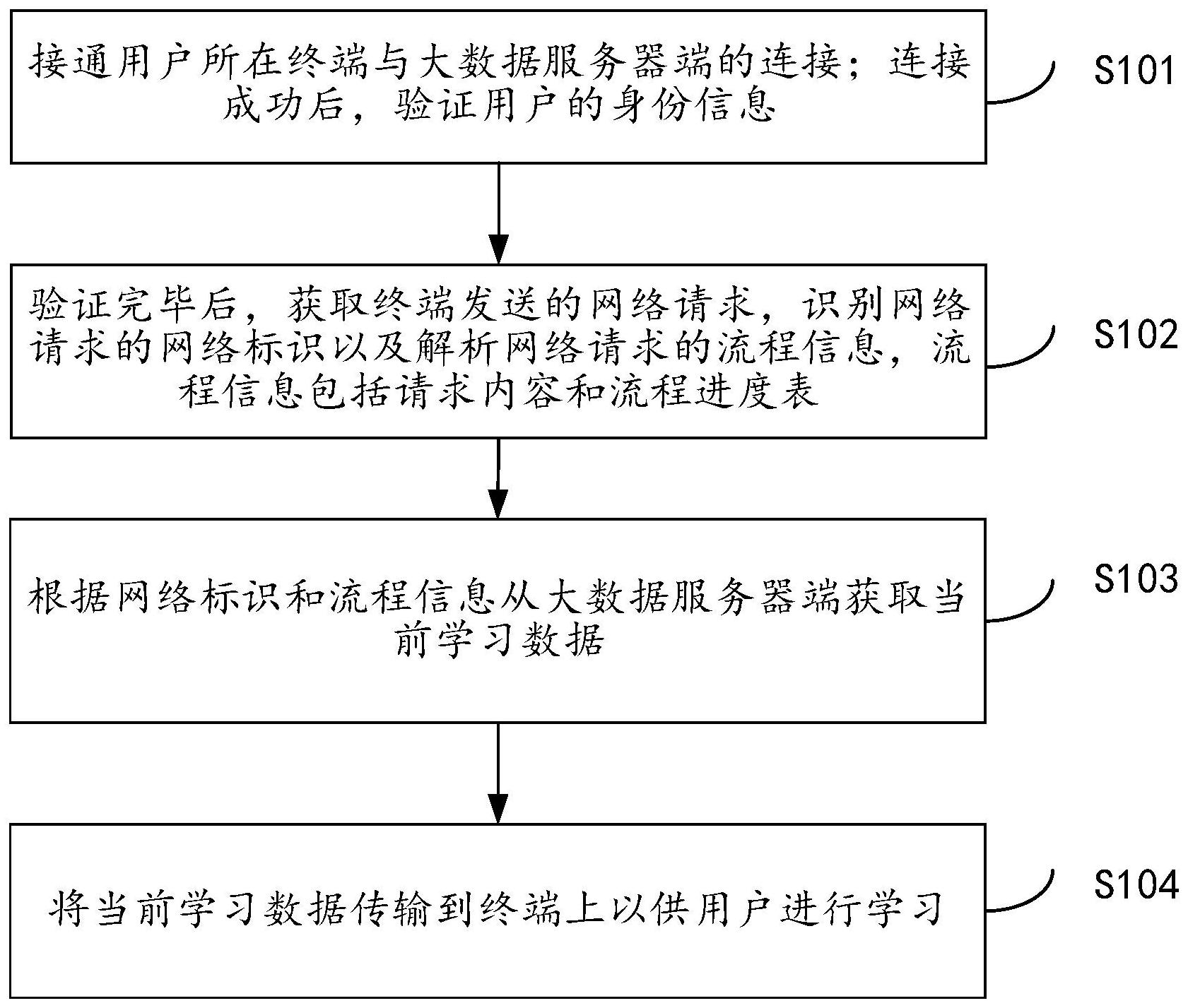
本发明公开了一种基于大数据的课堂学习方法,包括:接通用户所在终端与大数据服务器端的连接;连接成功后,验证用户的身份信息;验证完毕后,获取终端发送的网络请求,识别网络请求的网络标识以及解析网络请求的流程信息,流程信息包括请求内容和流程进度表;根据网络 全部
背景技术:
目前,在线教育越来越受到家长以及老师的热爱,由于其没有教学环境限定以及 脱离了面对面的教育方式,使得学生和老师居家就可进行知识的传授与接收,但是现有的 线上教育方法为老师在自己的第一终端上预先准备好要讲的ppt和内容然后和学生的第二 终端进行视频连接并且授课,但如果老师没有来得及准备ppt和授课内容会由于准备不充 分导致课堂质量低下严重影响了学生的学习效率,于是,科学家提出了利用大数据知识来 自主学习的方法,其流程为用户接通大数据端从大数据端获取所需要的知识内容进行自主 学习,但是这种方法存在以下问题,由于大数据的数量巨大,在用户发出学习申请后根据用 户的需要会反馈大量的学习内容,但是在这些学习内容中有大部分是用户不需要的,故而 需要用户手动的去筛选自己需要的学习内容,严重的浪费了时间并且效率低下,使得用户 体验感很差。
技术实现要素:
针对上述所显示出来的问题,本方法基于验证了与大数据服务器端连接的用户终 端后通过对用户端发送的网络请求进行识别和解析后获得网络标识和流程信息进而根据 网络标识和流程信息获取准确的学习数据推送到用户所在的终端上。 一种基于大数据的课堂学习方法,包括以下步骤: 接通用户所在终端与大数据服务器端的连接;连接成功后,验证用户的身份信息; 验证完毕后,获取所述终端发送的网络请求,识别所述网络请求的网络标识以及 解析所述网络请求的流程信息,所述流程信息包括请求内容和流程进度表; 根据所述网络标识和流程信息从所述大数据服务器端获取当前学习数据; 将所述当前学习数据传输到所述终端上以供用户进行学习。 优选的,所述接通用户所在终端与大数据服务器端的连接;连接成功后,验证用户 的身份信息,包括: 将所述终端的识别信息和连接请求发送至所述大数据服务器端以使所述大数据 服务器端对所述识别信息和连接请求进行校验,检验完毕后生成反馈信息至所述终端; 若所述反馈信息为可以连接,则接通所述终端与所述大数据服务器端的连接; 若所述反馈结果为无法连接,则将“无法连接服务器端”的消息显示在所述终端 上; 在连接成功后,获取所述用户所在的当前场景信息并对所述当前场景信息进行分 析,分析所述当前场景信息是否为常用预设场景信息; 若所述当前场景信息为所述常用预设场景信息时,向所述终端发出获取用户所注 册的用户名和密码的提示; 5 CN 111597442 A 说 明 书 2/9 页 若所述当前场景信息不是所述常用预设场景信息时,向所述终端发出获取用户所 注册的用户名和密码以及人脸识别的提示; 在获取到所述用户输入的用户名和密码以及当前人脸图像后,确认所述用户名和 密码是否正确以及确认所述当前人脸图像是否为预设人脸图像; 若是,向所述终端发出身份确认的提示; 否则,向所述终端发出身份无效的提醒。 优选的,在若所述反馈结果为无法连接,则将“无法连接服务器端”的消息显示在 所述终端上之后,所述方法还包括: 解析所述终端无法连接所述大数据服务器端的原因,生成解析报告; 将所述解析报告显示在所述终端上以使所述用户针对所述解析报告进行处理。 优选的,所述验证完毕后,获取所述终端发送的网络请求,识别所述网络请求的网 络标识以及解析所述网络请求的流程信息,所述流程信息包括请求内容和流程进度表,包 括: 获取所述网络请求所对应的网络参数; 为所述网络参数分配唯一的标识,将所述唯一的标识确认为所述网络标识; 解析所述网络请求以获得请求内容,所述请求内容包括:学科知识、论文、周刊中 的一个或者多个; 在解析出请求内容后,生成所述流程进度表。 优选的,所述根据所述网络标识和流程信息从所述大数据服务器端获取当前学习 数据,包括: 根据所述请求内容从大数据服务器端里的大数据库中获取知识推介集; 将所述知识推介集推送至所述终端以获得所述用户对所述知识推介集中每个学 习数据的兴趣度,获得n个兴趣度; 基于所述n个兴趣度,构建用户兴趣矩阵; 在所述用户兴趣矩阵中选择兴趣度最大的目标兴趣度,获取所述目标兴趣度对应 的目标学习数据; 将所述目标学习数据确认为所述当前学习数据。 优选的,所述方法还包括: 获取不同用户的用户兴趣矩阵,利用相似度算法计算每个用户兴趣矩阵的相似 度,构建用户相似度矩阵; 获取所述不同用户的用户兴趣矩阵中每个用户兴趣矩阵包含的学习数据,利用相 似度算法计算学习数据的相似度,构建学习数据相似度矩阵; 根据所述用户相似度矩阵和所述学习数据相似度矩阵构造用户推荐矩阵和学习 数据推荐矩阵; 构造完毕后,调度出预先建立的网络模型,将所述用户推荐矩阵中的多个用户信 息以及所述学习数据推荐矩阵中的多个学习数据输入到所述网络模型中进行训练直到所 述网络模型收敛。 优选的,所述方法还包括: 对所述当前学习数据进行预处理; 6 CN 111597442 A 说 明 书 3/9 页 确认预处理之后的当前学习数据的功能类型和数据特点; 根据当前学习数据的功能类型在大数据库中进行检索,统计出第一关联信息内 容; 根据当前学习数据的数据特点在所述大数据库中进行二次检索,统计出第二关联 信息内容; 将所述第一关联信息内容和所述第二关联信息内容存储并确定为数据挖掘信息; 对所述数据挖掘信息进行解释和评价,生成数据挖掘报告; 将所述数据挖掘信息和所述数据挖掘报告显示在所述终端上。 优选的,所述方法还包括: 统计所述用户在m个时刻获取的m个第一学习数据; 确定所述m个第一学习数据中每个第一学习数据的第一数据类型; 获取预设数量个第k时刻所对应的第二学习数据,获取所述第二学习数据的第二 数据类型,所述第k时刻为m个时刻中的任一时刻; 判断预设数量个第二数据类型与所述第一数据类型相同的概率是否为大于等于 预设概率; 若是,利用所述m个时刻与m个第一数据类型对网络模型进行训练,得到训练后的 网络模型; 在所述用户发出学习请求时,统计发出所述学习请求所对应的当前时刻,利用训 练后的网络模型为所述用户推荐与所述当前时刻所对应的第一数据类型相似的学习数据。 优选的,所述方法还包括: 实时获取所述用户对所述当前学习数据的学习进度; 根据所述学习进度更新流程进度表; 当所述流程进度表显示完结时,将所述当前学习数据和所述用户的身份信息存储 到预先建立的学习记录文件夹中; 存储完毕后,根据所述学习记录文件夹生成压缩文件发送到所述终端上以使所述 用户随时查看与复习; 根据所述用户的学习频率实时更新所述学习记录文件夹。 优选的,所述根据所述请求内容从大数据服务器端里的大数据库中获取知识推介 集,包括; 步骤B1、获取所述请求内容中的合成词语,所述合成词语可以为词语、单一文字和 成语中的一个或者多个; 步骤B1、将所述合成词语设置为词序列X(X1,X2,X3,....Xn); 步骤B2、利用下列公式计算所述大数据库中的学习数据与所述词序列X的相似度: 其中,Sim(X,Y)表示为所述大数据库中的学习数据与所述词序列X的相似度,n表 示为所述词序列X中合成词语的总数量,q表示为第q个合成词语,mq表示为第q个合成词语 的合成序列值,g表示为所述学习数据的总数量,h表示为第h个学习数据,bh表示为第h个学 7 CN 111597442 A 说 明 书 4/9 页 习数据的学习序列值; 步骤B3、计算所述词序列X中的每个合成词语的信息增益; 其中,P(Cq)表示为Cq类文档在g个学习数据中的概率值,Pq表示为g个学习数据中 包含合成词语q的比重,W表示为每个合成词语的信息增益; 步骤B4、根据所述信息增益和所述相似度,获得一个推介值; 重复所述步骤B3-B4以获得多个推介值; 获取所述多个推介值所对应的最终学习数据以生成所述知识推介集。 本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变 得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明 书以及附图中所特别指出的结构来实现和获得。 下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。 附图说明 附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实 施例一起用于解释本发明,并不构成对本发明的限制。 图1为本发明所提供的一种基于大数据的课堂学习方法的工作流程图; 图2为本发明所提供的一种基于大数据的课堂学习方法的另一工作流程图; 图3为本发明所提供的一种基于大数据的课堂学习方法的又一工作流程图。











