
技术摘要:
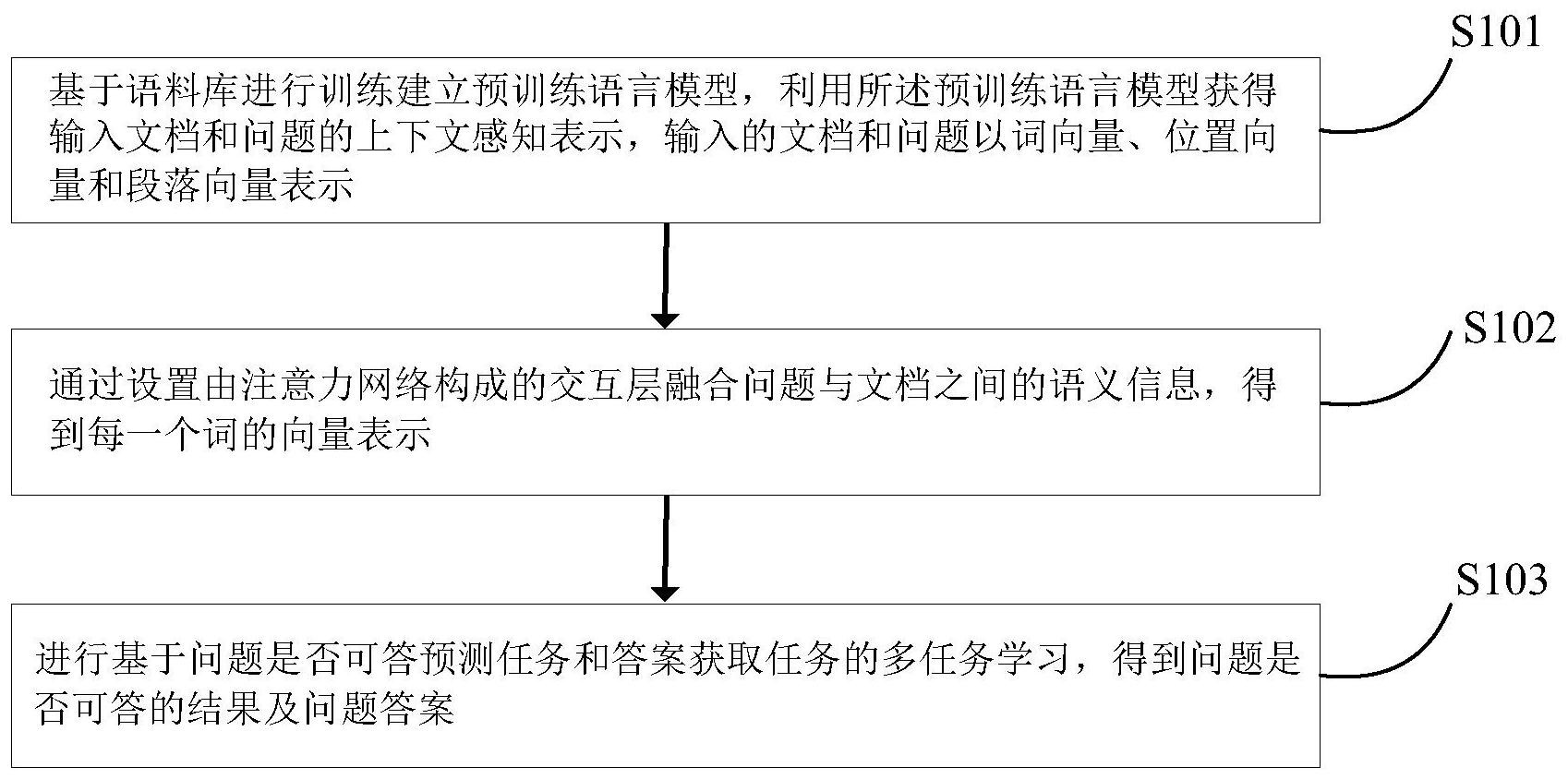
本发明公开一种基于预训练语言模型的多任务学习阅读理解方法。所述方法包括:基于语料库进行训练建立预训练语言模型,利用所述预训练语言模型获得输入文档和问题的上下文感知表示;通过设置由注意力网络构成的交互层融合问题与文档之间的语义信息,得到每一个词的向量 全部
背景技术:
大规模数据使机器阅读理解成为自然语言理解任务里面的一个关键任务。目前的 机器阅读理解任务依照答案的类型可以分为:完形填空型和片段抽取型。片段抽取的机器 阅读理解任务要求从输入的文档当中抽取出连续的文本作为答案。然而,在片段抽取的机 器阅读理解任务当中,大部分的任务都有一个强烈的假设,认为每一个问题都能够从文章 中找到答案。在这种假设下,只需要通过简单的模式匹配找到答案的边界,忽略了该问题是 否能真正被回答,所以仍然无法做到真正的自然语言理解,并且缺乏对问题是否可回答的 预测能力。然而,在现实世界中,不可回答问题却是普遍存在的。 目前,预测问题是否可回答的方法主要两种:一是使用一个简单的分类器对问题 是否可回答进行二分类。这种方法的不足是缺乏问题与文档之间的交互以及蕴含关系;二 是通过使用一种可验证的机制,首先抽取出一个看似合理的答案,然后以此为基础去进行 验证,判断该问题是否可回答。但这个看似合理的答案有可能是错误的,比如,当问题判断 为不可回答时,模型抽取出的看似合理的答案就变成错误的答案了。在错误的答案上进行 验证是不合理的。
技术实现要素:
为了解决现有技术中存在的上述问题,本发明提出一种基于预训练语言模型的多 任务学习阅读理解方法。 为实现上述目的,本发明采用如下技术方案: 一种基于预训练语言模型的多任务学习阅读理解方法,包括以下步骤: 步骤1,基于语料库进行训练建立预训练语言模型,利用所述预训练语言模型获得 输入文档和问题的上下文感知表示,输入的文档和问题以词向量、位置向量和段落向量表 示; 步骤2,通过设置由注意力网络构成的交互层融合问题与文档之间的语义信息,得 到每一个词的向量表示; 步骤3,进行基于问题是否可答预测任务和答案获取任务的多任务学习,得到问题 是否可答的结果及问题答案。 与现有技术相比,本发明具有以下有益效果: 本发明通过基于语料库进行训练建立预训练语言模型,能够获得句对之间的蕴含 关系;通过设置交互层能够充分融合问题与文档之间的语义信息,使模型具有较好的表达 能力;通过进行多任务学习,能够自适应地预测问题是否可答,并获取问题的答案。 3 CN 111581350 A 说 明 书 2/4 页 附图说明 图1为本发明实施例一种基于预训练语言模型的多任务学习阅读理解方法的流程 图。











