
技术摘要:
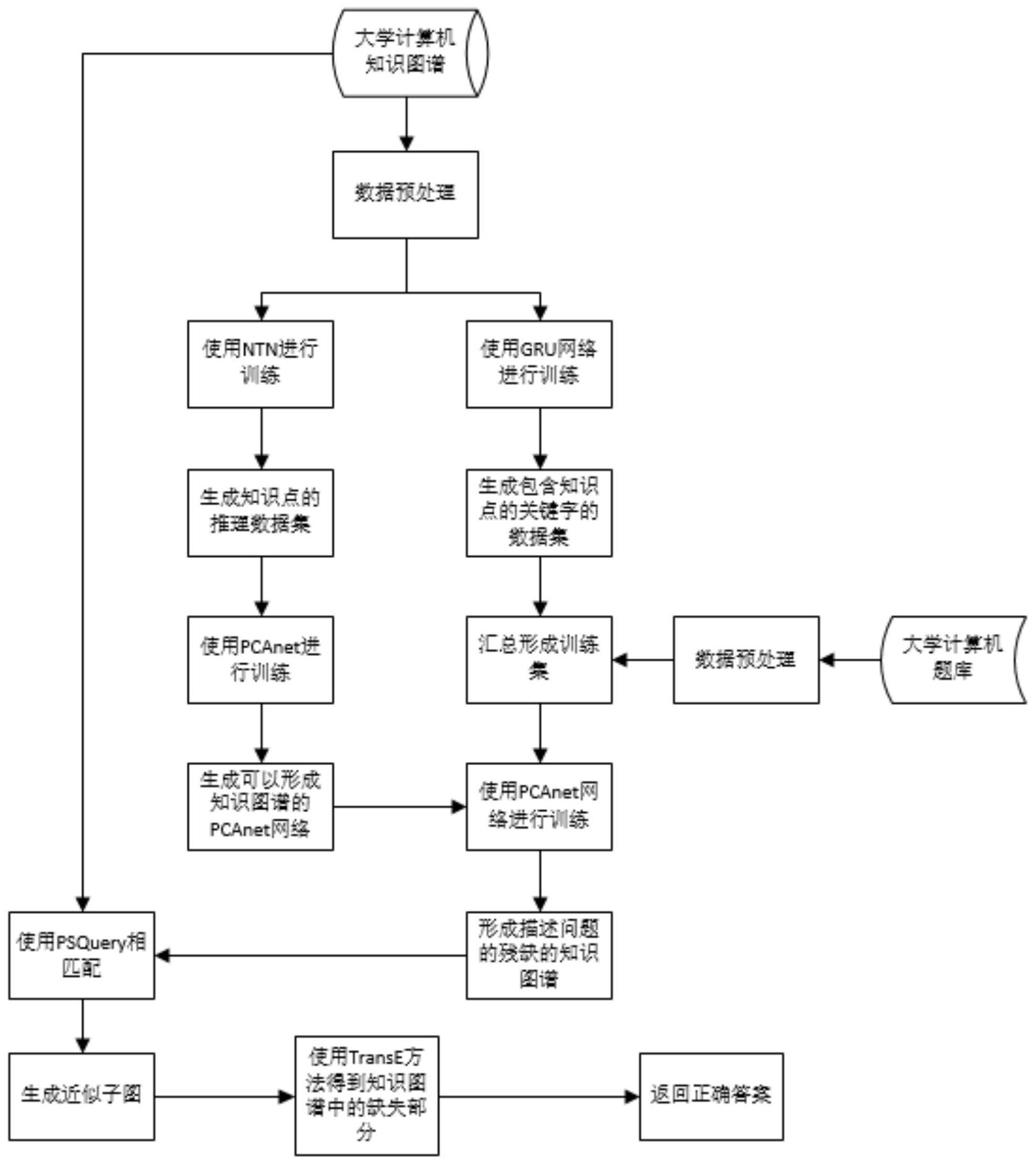
本发明公开了基于深度学习的大学计算机基础知识解题方法,使用已有的大学计算机基础知识图谱和NTN模型来生成包含所有基础知识点的推理数据集,接着使用PCANET和GRU网络生成和问题相对应的残缺的知识图谱,然后使用PSQUERY算法来匹配知识图谱中与残缺知识图谱最接近的近 全部
背景技术:
随着知识图谱技术的发展,我们所拥有的知识图谱数量也越来越多,知识图谱的 规模也越来越大。知识图谱将海量的知识以三元组结构的形式存储起来。而实体关系抽取 是知识图谱中的一个经典人任务,在过去的数十年中持续发展着,也取得了一些阶段性的 成果。随着深度学习时代的到来,各种各样的神经网络模型也为知识图谱方面的研究提供 了新的思路。相比于传统的方法,深度学习模型具有更加高效的学习能力,可以面对更加复 杂的文本语境,可以处理更大规模的训练数据。因此深度学习也为知识图谱在某些方面的 研究提供了更加新颖的解决方法。而随着计算机技术的飞速发展和IT时代的到来,计算机 已经融入到人们生活的每一处角落。而很多同学在自学这门课程的时候,由于基础知识点 不牢固,会出现效率低下的情况。而课外答疑的时间往往也不能满足一个学生的需求。 综上所述,熟练掌握《大学计算机基础》这门课程的方法就极为重要。而在一些同 学的学习中,经常会出现有了题目却没有标准答案的情况。因此发明一套可以根据题目来 获得答案的系统就极为重要。目前所使用的该方面的系统大多是通过手工来给出答案。在 缺少较为专业的知识的情况下,这种方法的速度较低,正确率也没有保障。本发明是所针对 此种情况提出来的一种解决方法。
技术实现要素:
本发明的目的是提出了一种基于深度学习的大学计算机基础知识的解题的方法, 解决了现有技术中存在的手工给出答案效率低的问题。 本方法以深度学习的算法和模型为基础,使用已有的大学计算机基础知识图谱和 NTN模型来生成包含所有基础知识点的推理数据集,接着使用PCANET和GRU网络生成和问题 相对应的残缺的知识图谱,然后使用PSQUERY算法来匹配知识图谱中与残缺知识图谱最接 近的近似子图,并且使用TransE方法来推理得出残缺知识图谱中的缺失部分,最后推理得 出的部分即为正确结果。 一种基于深度学习的大学计算机知识解题方法,运用计算机基础知识图谱和NTN 模型来生成包含所有基础知识点的推理数据集,接着使用PCANET和GRU网络生成和问题相 对应的残缺的知识图谱,然后使用PSQUERY算法来匹配知识图谱中与残缺知识图谱最接近 的近似子图,并且使用TransE方法来推理得出残缺知识图谱中的缺失部分,从而得到题目 的正确结果。 本方法的具体包括以下步骤: 步骤1,对计算机基础知识图谱进行数据预处理,使其从neo4j数据库等可视化形 式变成三元组形式;同时筛选掉考试范围以外的知识点; 4 CN 111598252 A 说 明 书 2/7 页 步骤2,使用NTN网络模型对步骤1中的三元组进行训练,生成知识点的推理训练 集; 步骤3,导入PCANET网络模型,使用步骤2生成的推理训练集训练好一个可以形成 知识图谱的PCANET网络; 步骤4,使用步骤1处理过的数据集,使用GRU网络模型进行训练,生成可以识别知 识点关键字的数据集。 步骤5,对计算机基础知识题库进行数据预处理,得到可以被PCANET网络模型训练 的数据集。 步骤6,使用步骤3生成的PCANET网络模型来训练步骤4形成的可以识别知识点关 键字的数据集和步骤5形成的计算机基础知识图谱数据集,生成描述问题的残缺的知识图 谱。 步骤7,使用PSQUERY方法匹配大学计算机基础知识图谱中与步骤6中的描述问题 的残缺的知识图谱的近似子图。 步骤8,使用TransE方法,得到用来描述问题的知识图谱中的缺失部分。 步骤9,此时知识图谱中的残缺部分即是正确答案,所述残缺部分包括其文字概念 和拓扑关系。 步骤2中,使用了NTN和三元组的优点是:NTN主要训练的方式就是将数据库中的实 体来表示成一个向量来实现的,而一个三元组也可以看作是一个向量,即把三元组中的每 个数据看作是向量中的数值。因此可以把两者结合起来,从而达到使用NTN来训练三元组的 效果;具体为使用了NTN对三元组进行训练;NTN将数据集中的每个对象或个体表示为一个 向量,直接对向量进行操作。NTN主要的步骤是:编写自定义图层,初始化张量形状、激活函 数、张量参数,然后再定义对比最大边缘损失函数,最后汇总数据训练,即可得出结果。这些 向量载体可以捕获有关该实体的事实及它是否成为关系的一部分,每个关系都是通过一个 新的神经张量网络的参数来定义的;因为NTN可以明确地涉及两个实体向量。因此使用NTN 训练三元组的效果会更好。 步骤4中,使用了GRU网络模型训练生成知识点关键字的数据集;GRU可以传递当前 的数据给下一时刻使用;GRU是由无数被称为记忆块的结构构成,每一个记忆块都包含输入 门,输出门,遗忘门和记忆单元;输入门会通过激活函数输入输入门的数据的输出数据判断 选择通过的数据;常用的激活函数是sigmoid函数sigmiod(x)=1/(1 e∧(-x)),可以将取 值为(-∞,∞)的数字映射到(0,1);如果映射的数大于了提前设置的阈值,那么这个数据就 可以被输出,反之则不行; 激活函数有sigmoid激活函数,tanh激活函数,Relu激活函数。 步骤7中,使用了PSQUERY算法匹配生成结果的最优近似子图,首先PSQUERT算法提 取出查询图的特征,然后根据提取出的特征分别进行编码,形成节点和图编码;再基于图编 码构建索引树进行过滤;最后生成候选图集合,再进行子图同构验证,最后得到最终的结果 集。 步骤9中,使用了TransE来获得知识图谱的残缺部分;TransE基于实体和关系的分 布式向量表示,将每个三元组实例中的关系看做从头实体到尾实体的转换。 本发明的有益效果是: 5 CN 111598252 A 说 明 书 3/7 页 本发明针对大学计算机基础知识中的部分题库没有标准答案的问题,采用了NTN 网络模型来对知识图谱进行训练,使用了GRU网络模型训练生成知识点关键字的数据集,使 用了PSQUERY算法匹配生成结果的最优近似子图,使用了TransE来获得知识图谱的残缺部 分。和传统的算法相比,增加了算法运行的效率和答案的准确率。 附图说明 图1为本发明一种基于深度学习的大学计算机知识解题方法基于深度学习的大学 计算机基础题目题解方法总流程图; 图2为本发明一种基于深度学习的大学计算机知识解题方法基于PSQUERY算法匹 配近似子图的过程; 图3为本发明一种基于深度学习的大学计算机知识解题方法基于NTN生成知识点 的推理数据集的过程; 图4为本发明一种基于深度学习的大学计算机知识解题方法在基于PCANET生成与 问题相对应的残缺的知识图谱的过程。 图5为本发明一种基于深度学习的大学计算机知识解题方法基于GRU生成包含知 识点的关键字数据集的过程。 图6为本发明一种基于深度学习的大学计算机知识解题方法基于TransE方法得到 知识图谱中的缺失部分的过程。











